Agent Q: Advanced Reasoning and Learning for Autonomous AI Agents
A web agent that searches a tree of possible web pages, uses one model as both the actor that proposes clicks and the critic that grades them, and learns from both its wins and its mistakes.
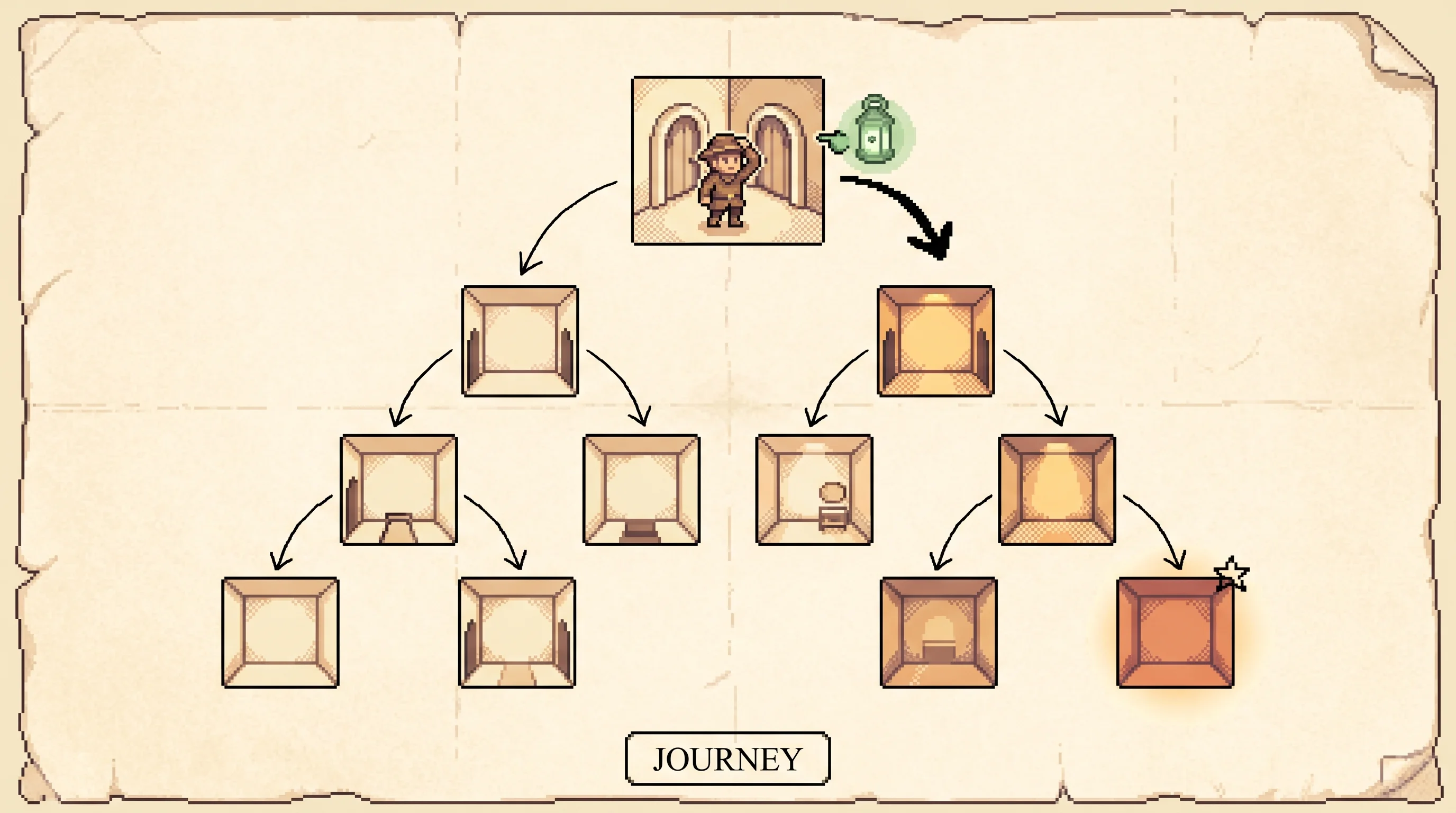
Read at your level
Start where you're comfortable and climb as far as you like.
- For a 5-year-old
- For a high schooler
- For a college student
- For an industry pro
- For a PhD candidate
- For a peer researcher
Executive summary
A web agent is a model that takes a goal like "book me a table for two on Friday at 7" and then clicks around a real website to do it. The hard part is the chain. One wrong click early on, like opening the wrong restaurant, dooms everything after it, and the agent only finds out at the very end whether it succeeded. Older agents trained by copying expert clicks, so they never saw their own mistakes and kept compounding them. Agent Q has the agent explore instead. At each page it proposes a handful of possible clicks, ranks them with the same model acting as its own critic, and runs Monte Carlo Tree Search to try whole paths and see which reach the goal. Then it turns the search into lessons. Where two sibling clicks ended up far apart in value, the better one becomes a "do this" example and the worse one a "not this" example, and the model fine-tunes on those pairs with Direct Preference Optimization. On a real booking site this lifted a Llama-3 70B agent from 18.6% success to 81.7% after one day of self-collected data, and to 95.4% when it also searched at test time. The catch is that letting an agent explore live websites means it makes real mistakes on the way, which is dangerous on anything that spends money or sends messages.
Try it
Load Guided search and press play. Watch the tree grow down toward the booked-reservation room while the visit counts pile up on the correct path. Then load Greedy DPO trap, set the click mode to Inspect, and play. With exploration off, the agent commits to the wrong restaurant on its first try and never opens the alternative, so it never books. Now switch the click mode to Flip its critic, load Guided search again, run a few steps, and click the OpenTable search node. The critic now ranks the wrong restaurant highest, and the search starts wasting its budget down the dead branch.
A trustworthy critic and balanced exploration. The search threads the correct path (right restaurant, open date, set date) and the Q-values concentrate there.
OpenTable search
The agent opens OpenTable and must reach the right restaurant page.
| action | critic | MCTS | blend |
|---|---|---|---|
| Open the wrong restaurant | 0.35 | 0.00 | 0.17 |
| Open the correct restaurant | 0.80 | 0.00 | 0.40 |
No sibling gap clears the threshold yet. Run more rollouts.
This runs one base LLM as both the actor that proposes actions and the critic that ranks them, exactly as in the paper, over a fixed 8-page booking task standing in for OpenTable. The per-action critic ranks, the actor proposals, and each action's true reach-the-goal chance are hand-set so the search is legible; a trained agent learns these from data. Rollout stochasticity and the 24-rollout budget are fixed per preset. The DPO fine-tuning step itself is summarised by the preference pairs the search produces, not run as gradient descent here. Runs are deterministic: the same preset always produces the same tree.
For a 5-year-old
Imagine you're in a big house with lots of rooms, and you want to find the room with the cookies. Every room has a few doors. You don't know which door leads to cookies, so you have to try them.
Here's the smart way. You walk through a door, then another, all the way until you hit a room with no cookies, a dead end. You remember "that path had no cookies." Then you go back and try a different door. Little by little you learn which doors lead toward cookies and which ones are dead ends. After enough tries, you know the whole way without even thinking.
Now imagine you have a little helper floating next to you. Every time you reach a new room, the helper looks at the doors and whispers "that one looks good, that one looks bad." The helper isn't always right, but it points you at good doors first so you don't waste time on silly ones.
The robot in this story is a computer that uses websites instead of a house. The rooms are web pages and the doors are clicks. The cookies are finishing the job, like booking a table at a restaurant. The robot tries paths, remembers which ones worked, and listens to its little helper. The neat trick is the helper is the same robot, just stopping to grade its own ideas. There is no real floating helper, the robot is talking to itself, asking "which of my ideas looks best?" before it picks.
For a high schooler
You've used a website to book something, maybe movie tickets or a haircut. You click through pages until it's done. A web agent is a computer program that does this clicking for you from a sentence like "book a table for two on Friday."
The problem is that one task takes many clicks in a row, and a mistake near the start ruins everything. Pick the wrong restaurant on click one and every click after that is wasted, but you only find out at the end when the booking is wrong. Older agents learned by copying a human expert's clicks step by step. They never practiced recovering from their own mistakes, so small errors stacked up.
Here's the one new idea for this section. Search means trying many possible futures before committing, like thinking three moves ahead in chess instead of grabbing the first move that looks okay. Agent Q searches over web pages. At each page it proposes a few clicks it might make, then it plays out whole sequences of clicks to the end to see which ones actually finish the task. Paths that reach the goal get a high score, paths that dead-end get a low score, and those scores flow back up so the agent learns which early click was worth it.
There's a second trick. The same model that proposes clicks also grades them. Before trying anything, it ranks its own ideas, "this click looks most useful, that one looks pointless." That ranking is a cheap guess that steers the search toward good clicks first, so it doesn't waste tries on obvious junk.

Once the search has tried a bunch of paths, the agent looks at moments where two possible clicks ended up very different. Say at the search page, "open the correct restaurant" scored 0.8 and "open the wrong restaurant" scored 0.2. That's a clear lesson. The agent saves "prefer the correct one, reject the wrong one" and uses pairs like that to retrain itself, so next time it picks the good click on its own without searching.
The result is that a model went from booking right about 1 in 5 times to about 4 in 5 times after a single day of practicing on itself.
For a college student
You should care about this because it's a clean recipe for turning a frozen language model into an agent that gets better at a real task by practicing, with almost no human labels. It stitches together three ideas you've probably seen separately: tree search, a learned value estimate, and preference-based fine-tuning.
Start with the setup. The agent works in a partially observed environment. It sees a web page as an HTML tree plus its own history, and it emits actions like CLICK [id], TYPE [id] [text], or GOTO [url]. The reward is sparse and binary. You get 1 only if the whole task finishes correctly, 0 otherwise. That sparsity is the core difficulty. With one bit of feedback at the end of a 14-click trajectory, how does the agent know which click was the good one? This is the credit assignment problem.
The first answer is Monte Carlo Tree Search. Picture each web page as a node in a tree, and each candidate click as an edge to a child page. MCTS repeats four phases. It selects a path down the tree, expands a new node, rolls out a trajectory from there to a terminal page to get a reward, and backpropagates that reward up the path.
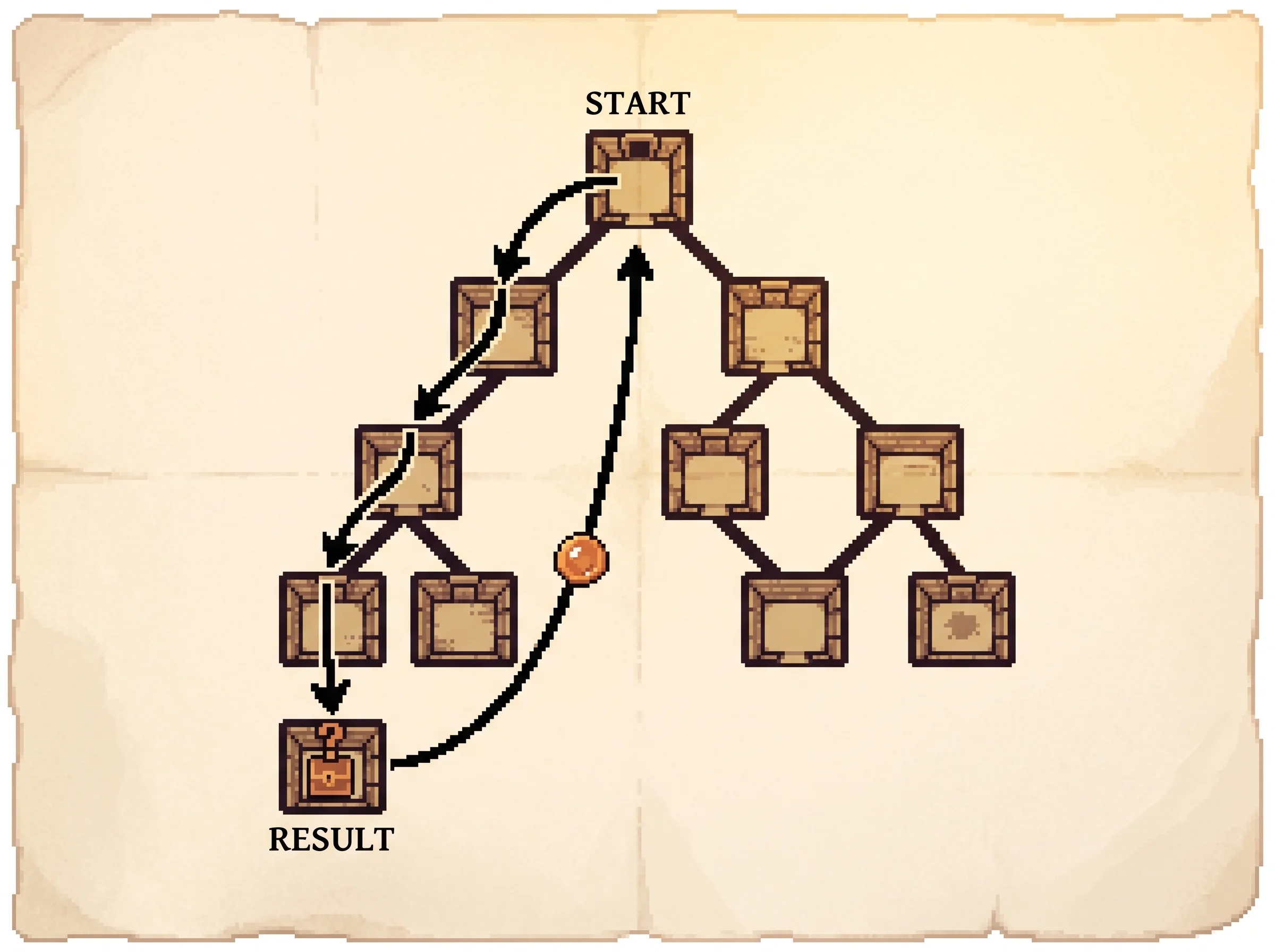
Selection uses the UCB1 rule, which balances trying what already looks good against trying what's unexplored.
a* = argmax_a [ Q(h, a) + c_exp * sqrt( log N(h) / (1 + N(h')) ) ]The first term, Q(h, a), is how good action a looks from state h. The second term is an exploration bonus. It's large when the parent has been visited a lot but this child has barely been tried, so the search is pulled toward neglected branches. The constant c_exp sets how curious the agent is. Turn it to zero and the agent only ever exploits its current best guess, which is exactly the failure you can trigger in the simulation above.
Backpropagation just keeps a running average of the rewards each action collected.
Q(h, a) <- ( Q(h, a) * N(h, a) + R ) / ( N(h, a) + 1 )
N(h, a) <- N(h, a) + 1Now the clever part. Web environments give no reward in the middle of a task, only at the end, so early in the search every Q is zero and UCB1 has nothing to steer by. Agent Q fills that gap with an AI critic. The same base model is prompted to rank the proposed actions by how useful they look, and that rank becomes a value estimate Q_hat. The value that actually drives the search is a blend of the two.
Q(h, a) = alpha * Q_tilde(h, a) + (1 - alpha) * Q_hat(h, a)Here Q_tilde is the empirical MCTS estimate from rollouts and Q_hat is the critic's rank-based guess. The slider labeled alpha in the simulation is exactly this. Push it to 1 and the agent trusts only what it measured by rolling out, which is slow to warm up. Push it down and the agent leans on the critic, which is fast but only as good as the critic. The Misleading critic preset shows what happens when the critic is wrong and alpha leans on it. The search marches confidently down a dead branch.
The last step turns search into training. After a round of search, look at every page where two sibling actions ended with values that differ by more than a threshold. The higher one is the preferred action, the lower one is rejected, and the pair feeds Direct Preference Optimization (DPO). DPO is a way to fine-tune a model on "prefer A over B" pairs without training a separate reward model. The loss pushes the model to raise the log-probability of the preferred action relative to the rejected one.
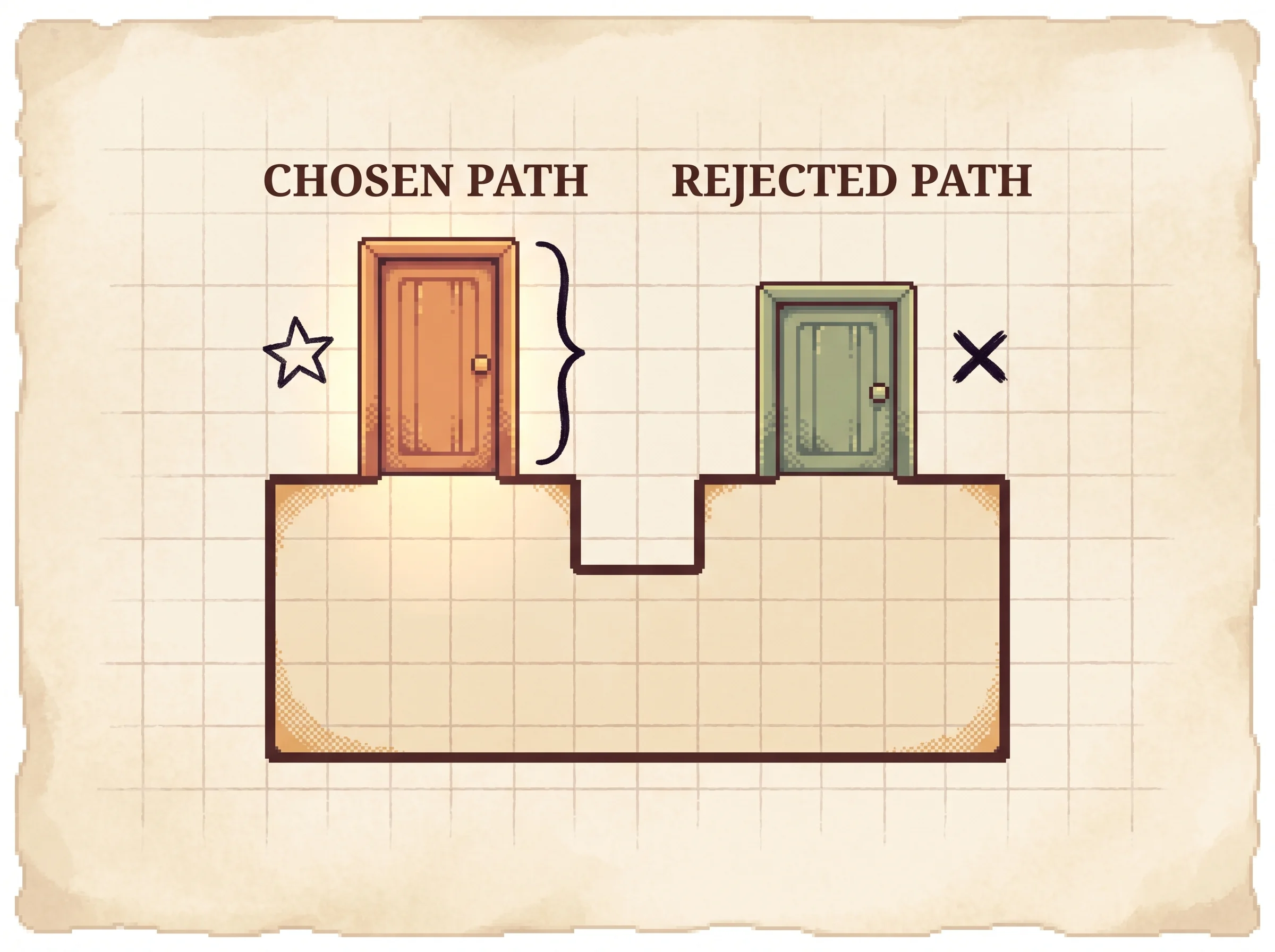
The threshold matters. A tiny threshold makes pairs out of near-ties, which is noisy. A big threshold only keeps the clearest lessons but gives you fewer of them. Drag the DPO threshold slider in the simulation and watch the pair list shrink as you raise it.
Walk one path end to end. The agent starts on the OpenTable search page. It proposes "open the correct restaurant" and "open the wrong restaurant." The critic ranks the correct one higher, so the search tries it first, rolls out, opens the date selector, sets the right date, and books, earning reward 1. That reward flows back up and lifts Q on every click along the way. The wrong-restaurant branch gets tried too, dead-ends, and earns 0. Now the two siblings at the search page differ a lot, so they become a preference pair, and the fine-tuned model learns to pick the correct restaurant without searching next time.
For an industry pro
The problem this solves is the one every agent team hits. Your base model can describe what to do but botches long multi-step tasks because errors compound and there's no signal telling it which step was wrong. Behavior cloning on expert traces plateaus fast, because the agent never trains on recovering from its own mistakes. Agent Q gives you a self-improvement loop that needs almost no human labels.
The recipe has two phases you can adopt separately. At inference time, wrap your policy in MCTS with a self-critique step. The same model proposes K actions per page and ranks them, and the search uses that ranking plus rollout rewards to pick a path. This alone is a big lever. On the real booking task, search at test time took the trained agent from 81.7% to 95.4%. At training time, run the search to collect trajectories, mine preference pairs from sibling value gaps, and fine-tune with DPO. On the same task this took a raw Llama-3 70B agent from 18.6% to 81.7% after a single day of self-collected data, beating zero-shot GPT-4o at 62.6%.
Deployment cost is real and worth pricing out. The base policy needs strong reasoning. They tried a smaller model on the booking task and it scored 0.0%, so they used Llama-3 70B. Search multiplies inference cost, because each step now proposes and ranks K actions and runs rollouts to terminal states, and the booking task averages 13.9 steps. The critic in this paper is a frozen GPT-4V for final scoring, so you're paying a strong vision model per trajectory during data collection. Budget for the search blowup at test time too, since 95.4% only comes with online search, not from the fine-tuned weights alone.
The failure mode to price in is safety. The whole method depends on the agent exploring live websites and making real mistakes along the way. On a booking site a wrong click is cheap. On anything that moves money, sends email, or files forms, an exploring agent is a liability. The paper says this plainly and limits the deployable scope to low-stakes sites. If your task touches payments or communications, you need guardrails the paper doesn't provide, like a separate safety critic or a human in the loop, and those eat into the autonomy that made the method attractive.
For a PhD candidate
The contribution is a closed self-improvement loop for LLM web agents that unifies guided search and preference-based RL, validated on a live website rather than only a simulator. The novelty isn't any single component. MCTS over language, AI process feedback, and step-level DPO each exist in the math-reasoning literature. The delta is assembling them into an interactive, autonomous loop and showing it works on a real booking site with sparse binary rewards and 14-step horizons.
The methodological choices reward scrutiny. They formulate the agent as a POMDP and compress the history into a running summary of past actions plus the current DOM, rather than the full trajectory, because real web tasks blow past context windows. Actions are composite. A step bundles a plan, a thought, an environment action, and an explanation, and they optimize the joint likelihood over all of them rather than down-weighting the reasoning tokens, which is a deliberate break from prior agent-DPO work.
The value blend in Equation 10, Q = alpha * Q_tilde + (1 - alpha) * Q_hat, is the load-bearing design decision. With sparse outcome rewards, the empirical Q_tilde is useless until rollouts accumulate, so the critic's Q_hat carries the early search. They justify treating the critic's ranking as a value estimate by leaning on the self-rewarding LLM line of work, and they prove (their Theorem 1, adapting Setlur et al.) that DPO on preferences drawn from the optimal value function recovers the optimal RL policy. The honest gap is that Q_hat comes from a frozen critic prompted zero-shot, not the optimal value function, so the theorem's clean guarantee degrades by however miscalibrated that critic is. The Misleading critic preset in the simulation is a direct probe of that degradation.
A few threats to validity stand out. The strongest results lean on a frozen GPT-4V critic for the final reward on OpenTable, so the loop is not fully self-supervised and inherits GPT-4V's blind spots. They state vision meaningfully improved classification accuracy over a text-only Llama critic, which means the open-source-only version is weaker than the headline. The WebShop gains from process supervision are modest (50.5% with MCTS versus 50.0% average human), and they attribute this to short horizons, which implies the method's edge depends on long-horizon credit assignment that WebShop doesn't stress. The 95.4% number requires test-time search, so it's not a property of the learned weights. The obvious follow-ups they name are training the critic rather than freezing it, and replacing MCTS with a learned search policy via meta-RL.
For a peer researcher
The delta against the math-reasoning DPO-with-tree-search papers (Chen et al., Xie et al., Zhang et al., and the step-DPO line) is the move to an interactive, partially observed web environment with real dynamics, and against the prompted-search web-agent line (Koh et al., Zhou et al.) it's that they actually train the policy instead of only searching at inference. Both deltas are real and the combination is the point. They use the branching structure of MCTS to manufacture step-level preferences, then close the loop by fine-tuning on them, on a live site.
The choices read as deliberate tradeoffs. DPO over PPO is a simplicity-and-safety call. They want offline, off-policy training because online policy-gradient rollouts on live websites are slow and risky, and DPO fits the branching preference data naturally. They drop the reference model and use an off-policy replay buffer with stored generation likelihoods, which trades a bit of the KL-anchoring DPO normally gives for not paying for a second forward pass. The blended value of Equation 10 trades the asymptotic correctness of pure MCTS for fast warm-up from the critic, and the whole method's quality is bounded by how good that frozen critic's rankings are.
What would change my mind on the framing. If a pure outcome-supervised DPO agent closed most of the gap on a genuinely long-horizon task, the process-supervision machinery would look like overhead, and the WebShop numbers already hint at that on short horizons. If the 95.4% held up without test-time search, the learned policy would be the story, but it doesn't, so the honest read is that search is doing heavy lifting at inference, not just at training. The open question I'd push on is the frozen critic. Equation 10 and Theorem 1 both want a well-calibrated value function, and they supply a zero-shot prompted ranker, so the obvious experiment is to fine-tune the critic in the loop and measure how much of the gap to the optimal-value guarantee that closes.
How it works
The problem and why prior approaches failed. Sequential decision-making on the web is a sparse-reward POMDP. The agent sees a page and its history, emits a composite action, and only learns whether it won at the very end of a long trajectory. Behavior cloning on expert demonstrations, the standard fix, trains the agent only on correct states, so it never learns to recover from the off-distribution states its own mistakes produce, and errors compound. Outcome-only fine-tuning (RFT or trajectory-level DPO) helps a little but still can't tell which step in a failed trajectory was the culprit, so it learns weak exploration. On WebShop the authors saw exactly this. Their DPO agent greedily grabbed the best item on the first page of results instead of paging through, because nothing taught it that exploring further was worth it.
The key idea. Search the space of web pages with MCTS, use the same base model as both actor and critic, blend the critic's action rankings with the rollout values to guide the search through the reward desert, and then convert the search tree into step-level preference pairs that fine-tune the policy with DPO. Search gives the agent foresight at inference; the preference pairs bake that foresight into the weights.
Methodology. At each node (a web page plus history h_t), the actor proposes K candidate actions. The critic, the same model prompted to rank, scores them into Q_hat. Selection descends by UCB1 (Equation 7), expansion adds a child, a rollout from the child reaches a terminal page for a binary reward R, and backpropagation updates the running averages (Equation 8). The value UCB1 uses is the blend of Equation 10.
Q(h_t, a) = alpha * Q_tilde(h_t, a) + (1 - alpha) * Q_hat(h_t, a)After search, preference pairs come from sibling actions whose blended values differ by more than a threshold, and the policy is optimized with the DPO loss over those pairs. The full loop is Algorithm 1.
for i in 1..N:
pi_ref <- pi_theta # off-policy: use the data-gen density
for each task in batch:
root <- h_0
for t in 1..T:
select by UCB1 (Eq. 7)
rollout with pi_theta to a terminal page, get R
backprop the value bottom-up (Eq. 8)
collect trajectories into replay buffer B
build pref pairs (h_t, a_win, a_lose) where |Q(h_t,a_win) - Q(h_t,a_lose)| > theta
optimize pi_theta with DPO (Eq. 5) on those pairsThe reward on the live booking site comes from a frozen GPT-4V critic that reads the final screenshot and the action history and returns a binary success score against four constraints (date, party size, user info, completed reservation). On WebShop the reward is the environment's exact-match signal.
Results with effect sizes. On WebShop, search at test time lifted the base xLAM-v0.1-r model from 28.6% to 48.4%, and the trained Agent Q with MCTS reached 50.5%, just past the 50.0% average-human bar. The training-only gain over outcome-DPO was modest here (Agent Q 50.5% versus DPO 40.6%), which they attribute to WebShop's short trajectories. On the real OpenTable booking task the numbers are larger. A zero-shot Llama-3 70B agent scored 18.6%. One round of RFT on 600 successful traces reached 67.2%, already past zero-shot GPT-4o at 62.6%. Outcome DPO reached 71.8%, and the full Agent Q pipeline reached 81.7%, a 340% relative gain over the zero-shot base. Adding MCTS at test time pushed it to 95.4%. Ablating the AI process feedback (Agent Q with MCTS Q-values only) gave 75.2%, so the intermediate process supervision was worth about 6.5 points.
Limitations and open questions. The critic is frozen and prompted zero-shot rather than trained, which the authors flag as likely suboptimal. The strongest results lean on a proprietary GPT-4V critic, so the fully open-source version is weaker. The headline 95.4% needs test-time search, not just the fine-tuned weights. And the method requires the agent to explore live websites, which means real mistakes on the path to learning, limiting safe deployment to low-stakes sites. They suggest training the critic and learning the search policy via meta-RL as next steps.
My assessment
The authors got the central bet right, and it's the same bet the field keeps winning with. Search plus learning beats either alone, and the cheap version of each is enough. The whole loop is built from parts that are easy to stand up: a frozen base model doing double duty as actor and critic, vanilla MCTS, and DPO instead of PPO so you never touch online policy gradients. That pragmatism is the strength. Anyone with a 70B model and a website can run a recognizable version of this.
Two things deserve a harder look. The first is how much of the win is search at test time versus learning in the weights. The 95.4% only shows up with online search, and even the trained-weights number (81.7%) sits on top of a frozen GPT-4V critic that scores the rewards. So the loop is not the fully self-supervised flywheel the framing suggests, it's a strong proprietary critic teaching an open model, plus expensive search at inference. That's still useful, but it's a different and more expensive claim than "the agent taught itself." The second is the safety story, which they're honest about but which guts the autonomy pitch. A method whose engine is "explore and make real mistakes" can't be pointed at the tasks people most want agents for, the ones involving money and messages, without bolting on the human oversight the method was supposed to remove.
The open thread I'd pull is the frozen critic. Equation 10 leans on Q_hat, Theorem 1 wants that estimate to approximate the optimal value function, and they hand it a zero-shot prompted ranker. The Misleading critic preset above is the whole risk in one knob. When the critic is wrong and you trust it, the search confidently wastes its budget on a dead branch. Closing the gap between the prompted ranker and a trained value function is where the next real gain lives, and the authors say as much. The paper is a clean, honest demonstration that the search-and-learn recipe ports from math problems to live websites, with the asterisks stated out loud.