Mastering the Game of Go with Deep Neural Networks and Tree Search
A Go program that beats a human professional by using one neural network to guess which moves are worth trying and a second to guess who is winning, then searching only the few futures that matter.
Read at your level
Start where you're comfortable and climb as far as you like.
- For a 5-year-old
- For a high schooler
- For a college student
- For an industry pro
- For a PhD candidate
- For a peer researcher
Executive summary
Go has more legal board positions than there are atoms in the universe, so no computer can read every line the way it can in checkers. For decades that made Go the game machines couldn't crack. AlphaGo cracks it with two deep neural networks and a search that leans on them. A policy network looks at a board and points at the handful of moves worth considering, which cuts down how wide the search has to go. A value network looks at a board and guesses who's winning without playing the game out, which cuts down how deep the search has to go. A Monte Carlo tree search grows a tree of possible futures using both, spending its effort only on the promising lines. AlphaGo won 99.8% of games against other Go programs and beat the European champion Fan Hui 5 games to 0, the first time a program had beaten a Go professional on a full board. The catch is cost. The full version ran on 48 CPUs and 8 GPUs and still searched thousands of positions per move, and the value network had to be trained on 30 million self-play positions to stop it from memorizing instead of judging.
Try it
Load the Value net lies preset. The value network has been fooled into loving the move contact, which is actually a losing move, and rollouts are switched off so nothing checks it. Step the search and watch the visits pile onto contact, the wrong move. Now drag lambda up to 0.5 so rollouts come back, keep stepping, and watch the search abandon contact for center, the move that's really best. Then load Greedy trap and drag c_puct up from near zero to escape a different failure.
Good priors and a fair value network. The visit count piles onto the move that is actually best.
Hover or click a node to read its prior, visit count, and value. Switch the click mode above to boost a move's prior, make the value net lie about a node, or prune a branch.
Flip a knob, boost a prior, or make the value net lie to start the log.
Selection here is exactly the paper's rule, argmax of Q(s,a) + c_puct·P(s,a)·sqrt(ΣN)/(1+N), and a leaf is scored by V = (1−λ)vθ + λz, the value-net and rollout blend. This runs a fixed 3-by-3 toy tree with hand-set true values standing in for one Go position; the real AlphaGo searches a tree with roughly 250 moves per position and uses 13-layer networks trained on 30 million positions. The move played is always the most-visited root child. The run is fully deterministic: a fixed seed is used so the same preset and knob positions always reproduce the same sequence of simulations.
For a 5-year-old
Imagine a giant maze with a billion paths. You want the path that leads to the treasure. You could try every single path, but that would take forever, longer than your whole life. So you don't.
Instead you bring two friends. The first friend is good at guessing. She looks at where you are and says "only these two doors look interesting, ignore the rest." Now you have way fewer doors to try. The second friend can peek ahead. He looks down a hallway and says "this way feels like it leads to treasure, that way feels like a dead end," without walking all the way there. Now you don't have to walk every hallway to the very end.
With both friends helping, you only explore a few good paths instead of a billion. That's how the Go robot wins. One friend points at the few good moves. The other friend guesses who's winning just by looking. The robot still tries lots of moves in its head, but only the smart ones.
The robot's friends aren't real people who can see. They're math that learned from watching millions of real Go games, so their guesses are usually right. But they're still guesses, and sometimes a guess is wrong. When the pointing friend points at a bad move, the robot has to try other moves anyway to catch the mistake.
For a high schooler
You've used autocomplete. You start typing and your phone offers three words, not every word in the dictionary. It narrows your choices down to the likely ones. AlphaGo does the same thing for Go moves, and that narrowing is the first half of the trick.
Here's the first new term. A policy is a rule that, given a board, hands you a short list of good moves with a score for each. AlphaGo's policy is a neural network that watched 30 million moves from strong human players and learned to predict what a good player would do. So instead of looking at all 250-ish legal moves, the search only seriously looks at the few the policy likes. That shrinks the problem a lot.
The second new term is value. A value is a single guess at who's winning from a board, a number from "you lose" to "you win." AlphaGo's value network looks at a board and outputs that number directly, without playing the game out. That matters because the alternative, playing every line all the way to the end, is what makes Go too big to search.
Here's a worked example with small numbers. Say at some point you have three moves. The policy scores them 0.45, 0.30, and 0.25, so move one looks best to start. But scores are just guesses. As the search tries each move and the value network rates where they lead, move one might turn out to lead somewhere the value network rates at -0.6, a loss, while move two leads to +0.55, a win. The search shifts its attention to move two. The starting guess pointed one way, the deeper look corrected it.
The whole machine is those two guesses plus a search that keeps trying moves and updating which one looks best.
For a college student
You should care about this because it's the paper that beat Go, the last classic board game machines hadn't won, and it did it by fusing deep learning with classical search in a way that became the template for AlphaZero and everything after.
Start with why Go is hard. A game tree has breadth b, the number of legal moves per position, and depth d, the length of the game. Brute-force search costs about b^d. Chess is roughly b ≈ 35, d ≈ 80. Go is roughly b ≈ 250, d ≈ 150. That exponent is hopeless. You reduce it two ways. Cut the depth by replacing the subtree below a position with an estimate of its value, so you stop reading early. Cut the breadth by only sampling from the moves a policy thinks are good, so you stop reading wide. AlphaGo does both with learned networks.
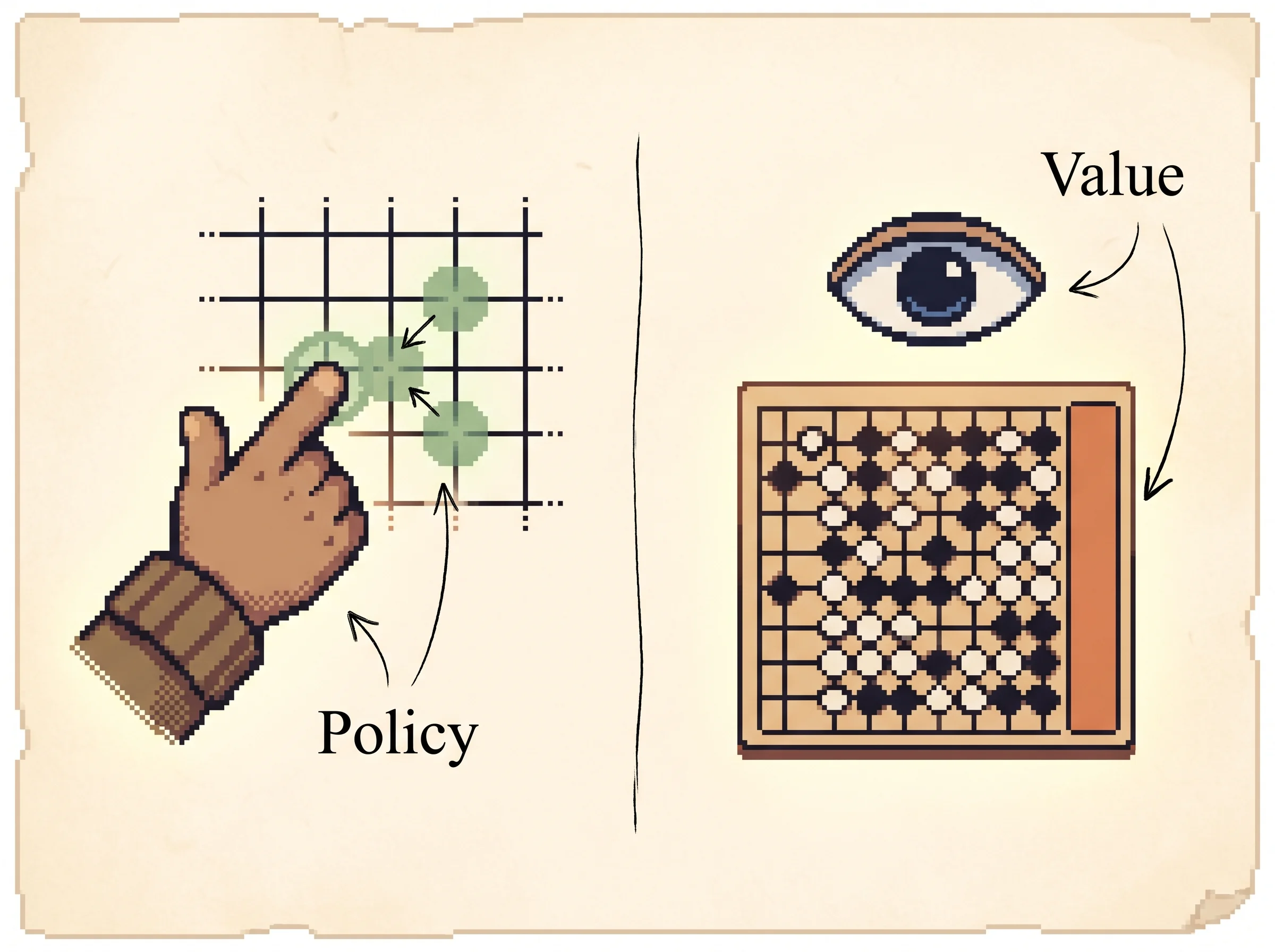
The policy network p is a 13-layer convolutional network. The board comes in as a 19 by 19 stack of feature planes (stone colors, liberties, capture counts, and so on), and the network outputs a probability over every legal move. They train it in two stages. First, supervised learning on 30 million human positions, which reaches 57% accuracy at predicting the human move. Then, reinforcement learning by self-play, where the network plays past versions of itself and gets nudged toward moves that won, using a policy-gradient update.
Δσ ∝ ∂ log p(a | s) / ∂σ (supervised: copy the human move)
Δρ ∝ (∂ log p(a_t | s_t) / ∂ρ) · z_t (self-play: reward winning moves)The value network v shares the same architecture but outputs one number, the expected outcome from a position. Training it is the subtle part. If you train on positions from complete games, successive positions in one game share the same final label and differ by a single stone, so the network memorizes outcomes instead of learning to judge. They beat this by building a fresh self-play set of 30 million positions, each drawn from a separate game, which dropped the gap between training and test error to almost nothing.
Now the search. AlphaGo runs Monte Carlo tree search, but every node stores learned statistics. Each edge (s, a) keeps a prior P(s,a) from the policy network, a visit count N(s,a), and a mean action value Q(s,a). A simulation walks down the tree picking the move that maximizes value plus an exploration bonus.
a_t = argmax_a ( Q(s,a) + u(s,a) )
u(s,a) ∝ P(s,a) / (1 + N(s,a))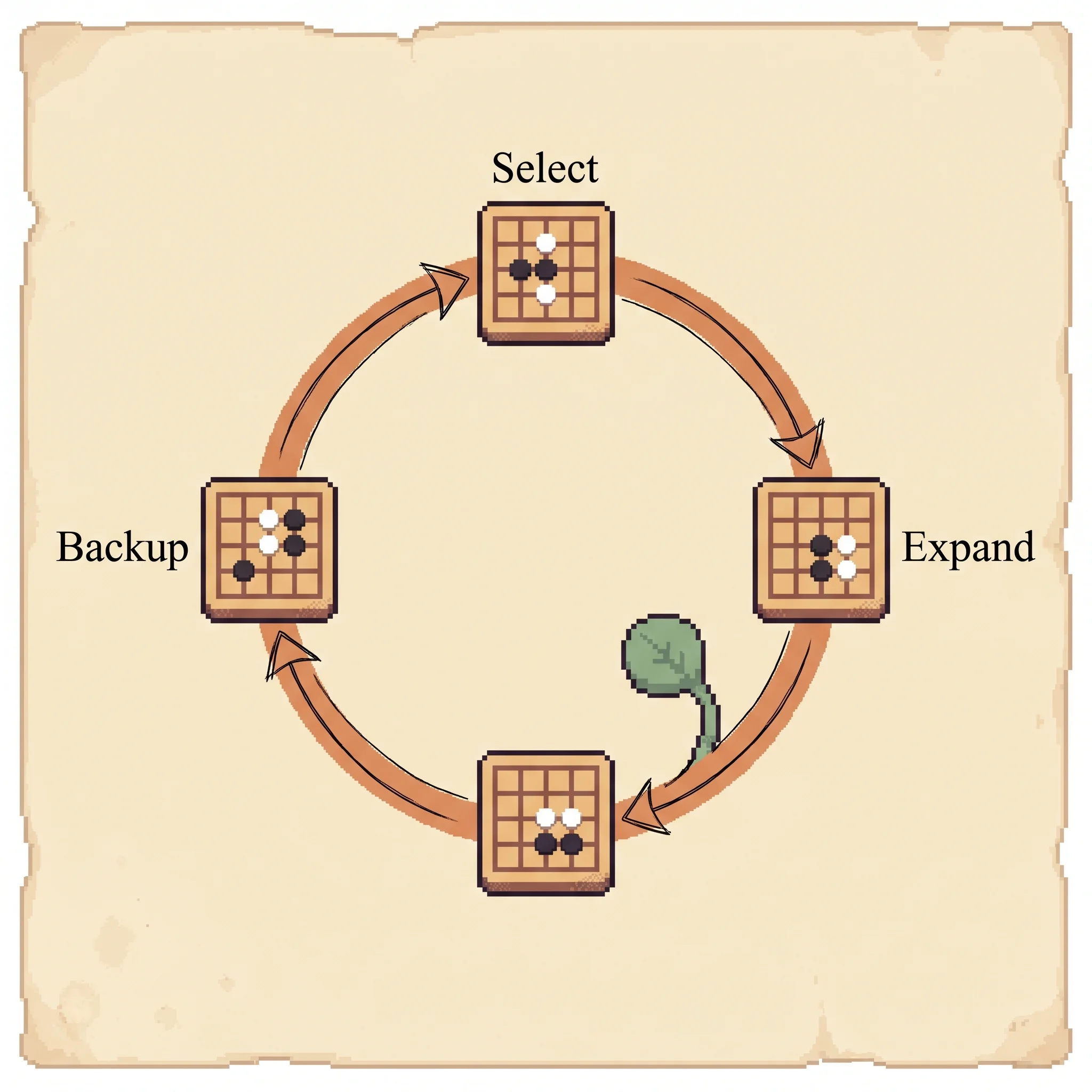
Read the bonus. It's large when the prior is high and the visit count is low, so early on the search trusts the policy and tries its favorites. As a move gets visited, the bonus shrinks and Q, the measured value, takes over. That's the balance between trusting the coach's guess and checking it yourself. The simulation above runs exactly this rule. Drag c_puct to zero and the search stops checking, riding the prior straight into whatever the policy liked.
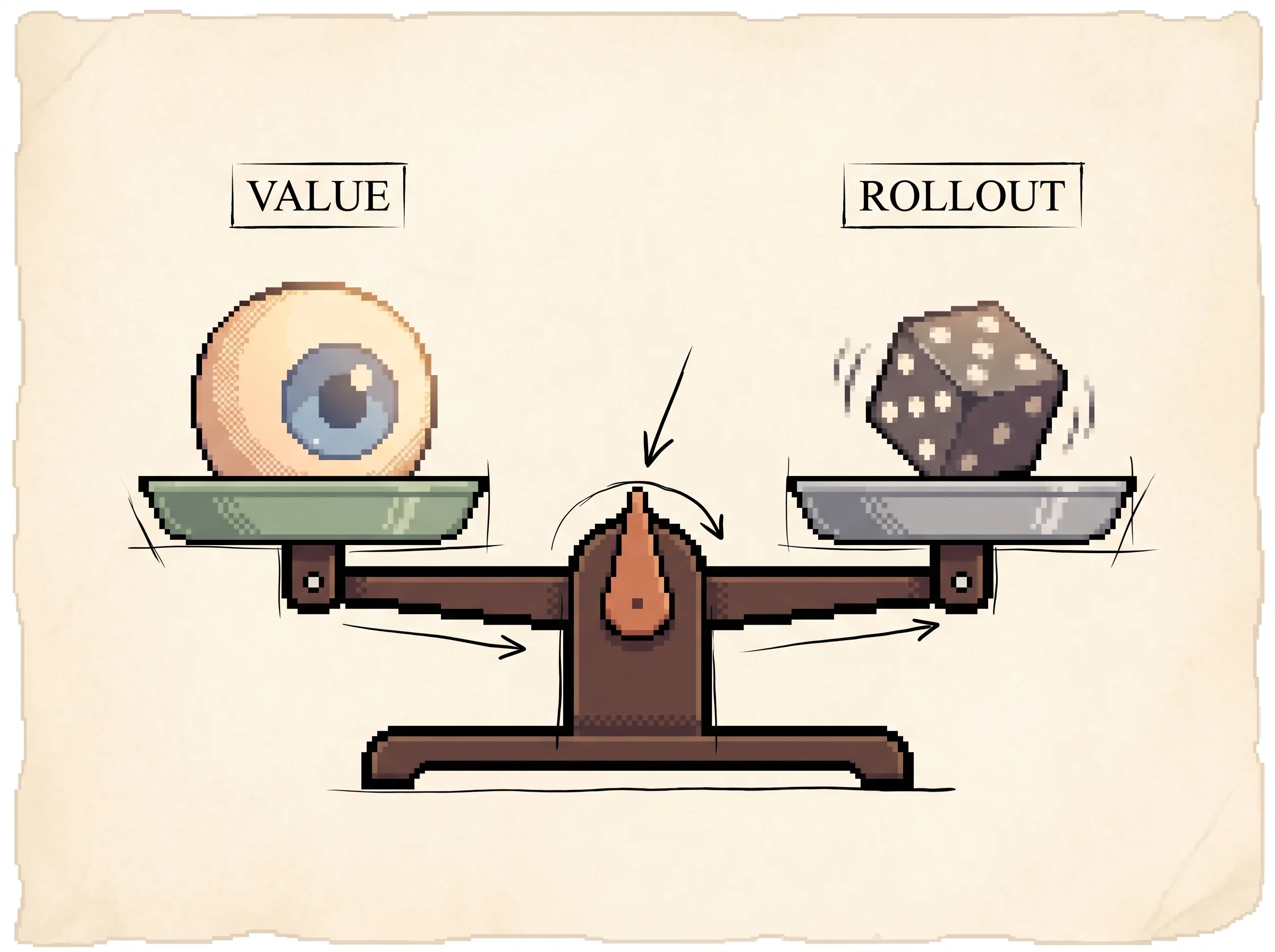
When a simulation reaches a leaf, the leaf gets scored two ways and the scores get mixed.
V(s_L) = (1 - λ) v_θ(s_L) + λ z_LThe value network gives v_θ, its direct guess. A fast rollout plays the position out to the end with a cheap policy and reports the winner as z. The mix parameter λ trades them off, and the paper found λ = 0.5, an even blend, beat either alone.
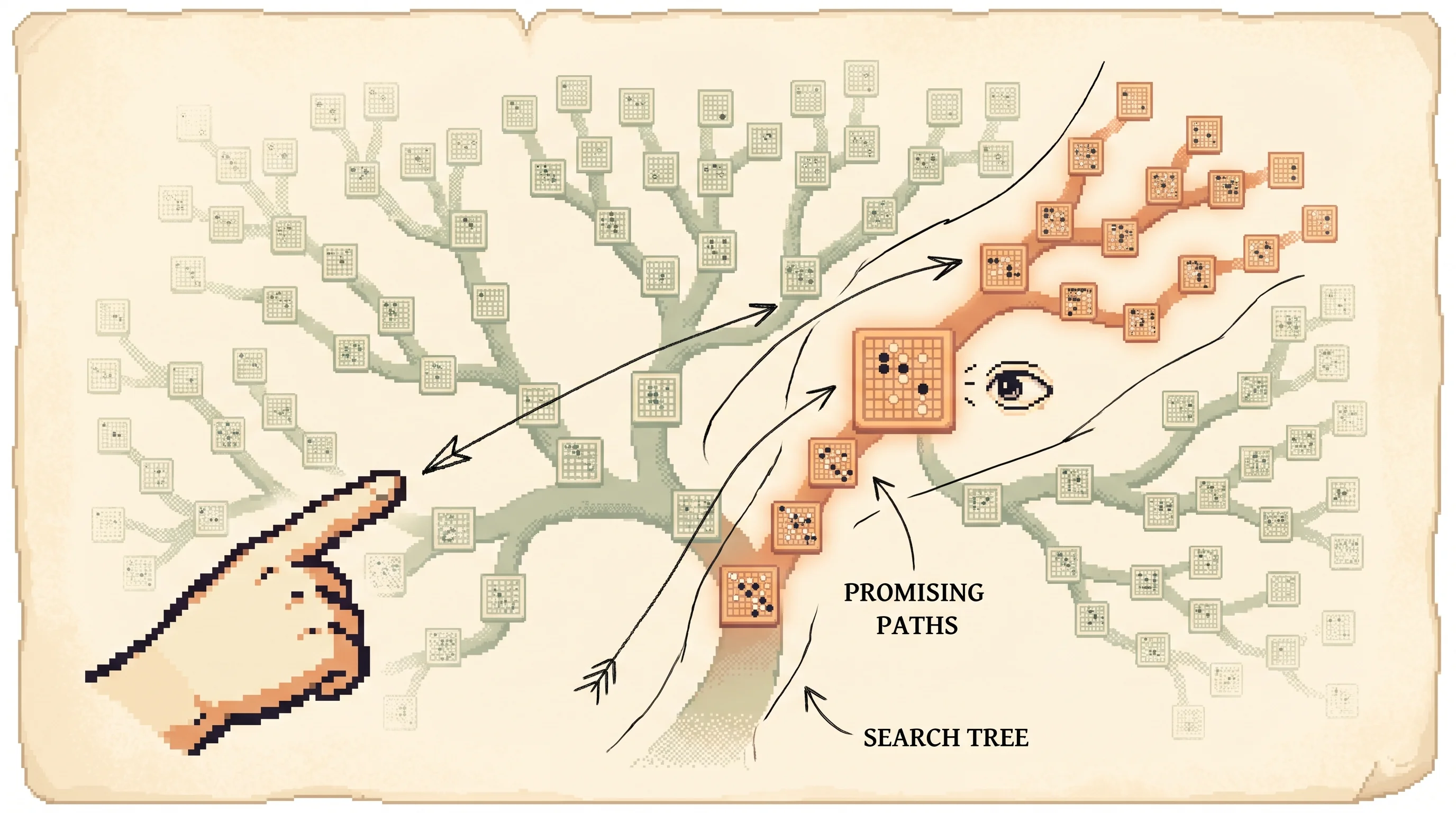
Walk one path end to end. The search reaches a new position, expands it, the policy stamps priors on its children, the value network and a rollout score it, and that score gets added back up every edge on the path so each Q and N updates. Do this thousands of times and the visit counts concentrate on the strongest move. When the time runs out, AlphaGo plays the move with the most visits, not the highest value, because visit count is the more stable signal.
The limitation is cost. Evaluating these networks is orders of magnitude slower than the hand-written scoring functions old programs used, so AlphaGo runs the search asynchronously across many CPUs and GPUs to keep up.
For an industry pro
The problem this solves is decision-making in a space too large to enumerate, where you have a cheap way to score options and a cheap way to estimate outcomes. Go is the extreme case, but the pattern (a learned proposal model plus a learned evaluator plus a search that spends compute where the models point) transfers to planning, scheduling, and any tree of choices you can't fully expand.
Deployment cost is the headline you can't ignore. The single-machine version used 48 CPUs and 8 GPUs; the distributed version used 1,202 CPUs and 176 GPUs. Training was heavier still. The supervised policy took about three weeks on 50 GPUs across 340 million updates, and the value network ran 50 million mini-batches on 50 GPUs over a week. You're buying superhuman play with a serious hardware bill, both to train and to run. Budget for inference latency too, since every move spends a fixed compute window running thousands of simulations.
The improvement over the previous best is not incremental. Against the strongest prior programs, Crazy Stone and Zen, single-machine AlphaGo won 494 of 495 games. Distributed AlphaGo beat single-machine AlphaGo 77% of the time. The jump in playing strength was about 1,000 Elo over the prior state of the art, which is the difference between a strong amateur and a professional.
The failure mode to plan around is that both networks are guesses, and the search has to budget exploration to catch their mistakes. Cut exploration to save compute and the search tunnels into whatever the policy network favored, even when it's wrong. The simulation's Greedy trap preset is exactly this. The two evaluation signals also exist to cover each other. The value network is the strong but slow judge; the rollout is the fast sanity check. The paper's measured best was a 50/50 blend, so leaning entirely on either one in production is leaving accuracy on the table.
For a PhD candidate
The contribution is the first demonstration that deep neural networks, trained by a supervised-then-reinforcement pipeline, can supply both the move-selection prior and the position evaluator inside Monte Carlo tree search well enough to reach professional strength in Go. Prior MCTS Go programs used handcrafted features and shallow linear policies to bias rollouts; the delta is replacing both the breadth heuristic and the depth heuristic with learned convolutional networks, and showing they compose inside the tree search.
The training choices reward scrutiny. They run two policy networks at search time, the slow accurate SL policy p_σ for the priors and a fast linear rollout policy p_π (2 microseconds per move versus 3 milliseconds) for the playouts. Notably they found the SL policy gave better priors than the stronger RL policy p_ρ, which they attribute to humans selecting a diverse beam of moves while the RL policy collapses onto the single best one. But the value network derived from the RL policy was the better evaluator. So the two heads come from different training targets on purpose. The value network's anti-correlation problem (positions within one game share a label) is handled by generating one position per self-play game across 30 million games, which is the kind of data-engineering detail that decides whether the whole thing works.
The search uses a variant of PUCT, a_t = argmax(Q + u) with u = c_puct · P · sqrt(ΣN)/(1+N), and asynchronous policy-and-value MCTS (APV-MCTS) with virtual loss to keep parallel threads from exploring the same path. Leaf evaluation mixes value and rollout at λ = 0.5. The ablations are clean. With value only (λ = 0) or rollouts only (λ = 1) AlphaGo still beats every other program, but the mix wins ≥95% of games against either single-signal variant, which is strong evidence the two estimators are complementary rather than redundant.
Threats to validity worth probing. The headline human result is five formal games against one professional (Fan Hui, 2 dan), which is a small sample against a player well below the top ranks, so "professional level" is established but the ceiling isn't. The networks are trained heavily on human games, so the supervised policy inherits human biases, and how much the self-play stage escapes them is a question this paper opens more than answers. And the compute is enormous, which leaves open whether the approach is the right one or just the one that worked first at scale. The obvious follow-ups, which the lab then chased in AlphaGo Zero and AlphaZero, are dropping the human data entirely and learning the policy and value from self-play alone.
For a peer researcher
The delta against prior MCTS Go (Crazy Stone, Zen, Pachi, Fuego) is that the policy prior and the leaf evaluator both become deep nets instead of handcrafted patterns, and the value net makes truncated, network-based position evaluation competitive with rollouts for the first time in Go. The delta against TD-Gammon-style value learning is depth and the convolutional architecture, plus the trick of decorrelating the value-network training set by sampling one position per game.
The choices read as deliberate tradeoffs. Using p_σ not p_ρ for priors trades single-move strength for a wider move distribution that the search benefits from, which is a nice empirical inversion of the obvious choice. Mixing value and rollout at λ = 0.5 trades the value net's speed and global judgment against the rollout's exact terminal scoring, and the ≥95% win rate of the mix over either pure variant is the cleanest result in the paper. Virtual loss in APV-MCTS trades a small per-thread bias for the parallelism that makes the network evaluations affordable inside a real time control.
What would change my mind on the framing. If a pure self-play system with no human data matched this, the "supervised bootstrap is necessary" reading would weaken, and that's exactly what AlphaGo Zero went on to show, so the human-data stage turned out to be a convenience rather than a requirement. The honest soft spot is the evaluation against humans, a single 2-dan opponent over five formal games, which proves the threshold was crossed but says little about the margin, later settled by the Lee Sedol and Ke Jie matches.
How it works
The problem and why prior approaches failed. Sequence the difficulty first. Optimal play in a game of perfect information means computing a value function over a game tree of size roughly b^d. For Go, b ≈ 250 and d ≈ 150, so exhaustive search is out. The two general fixes are to truncate depth by evaluating a position instead of reading to the end, and to narrow breadth by sampling only from promising moves. Earlier Go programs narrowed breadth with shallow handcrafted policies and truncated depth with Monte Carlo rollouts, reaching strong amateur play but no further, because the policies were too weak to prune well and rollout-based evaluation was too noisy.
The key idea. Learn both the breadth reducer and the depth reducer as deep convolutional networks, then run them inside Monte Carlo tree search. The policy network supplies the prior over moves at each node (breadth), and the value network supplies a direct estimate of who's winning at each leaf (depth). Neither needs lookahead to be useful, and together inside search they reach professional strength.
Methodology. The pipeline has four stages. Train an SL policy network on 30 million human positions to predict expert moves. Train a faster, weaker rollout policy on local pattern features. Improve the policy by self-play reinforcement learning into an RL policy. Finally, train a value network by regression on 30 million self-play positions, one per game to avoid overfitting. At play time, the search keeps per-edge statistics and runs four phases per simulation.
select: descend by a = argmax( Q(s,a) + c_puct·P(s,a)·sqrt(ΣN)/(1+N) )
expand: add the leaf's children, stamp priors P = p_σ(a|s) from the policy net
evaluate: score the leaf V = (1-λ)·v_θ(s) + λ·z, value net blended with a rollout
backup: for every edge on the path, N += 1, accumulate V, recompute Q = W/NAfter the budget of simulations runs out, play the most-visited move from the root. The visit count is preferred over the mean value because it's less sensitive to a single noisy evaluation. Load the Greedy trap preset in the simulation to watch what happens when the exploration term is too small to ever overturn a confident but wrong prior.
Results with effect sizes. Against other Go programs, single-machine AlphaGo won 494 of 495 games (99.8%). Distributed AlphaGo beat the single-machine version 77% of the time and every other program 100% of the time. The value-plus-rollout mix (λ = 0.5) beat the value-only and rollout-only variants in at least 95% of games. The RL policy network alone, with no search, beat the strongest open-source program Pachi 85% of the time, where the previous supervised-only state of the art beat Pachi only 11% of the time. And AlphaGo beat the European champion Fan Hui 5 games to 0 in formal games.
Limitations and open questions. The networks are guesses and the search must spend exploration to catch their errors. Evaluation is far more expensive than the linear scoring functions it replaced, forcing the asynchronous distributed search and a large hardware footprint. The human result is one professional over five formal games, so the margin above professional play is unmeasured here. And the heavy reliance on human game data left open whether the same level could be reached from self-play alone.
My assessment
The authors got the central bet right, and the field moved with them. The architecture (a learned proposal model and a learned evaluator wrapped in tree search) became the spine of AlphaGo Zero, AlphaZero, and MuZero, and the same shape now shows up far from board games. The cleanest piece of the paper is the ablation showing the value-rollout mix beats either signal alone in 95% of games, because it makes a falsifiable claim about why two estimators are better than one and then backs it with numbers, rather than asserting it.
Where the paper was conservative, history was kind. They leaned on 30 million human games to bootstrap the policy, which was the sensible move in 2016 and which the lab itself later showed was unnecessary when AlphaGo Zero learned stronger play from self-play with no human data at all. So the human-data stage reads now as scaffolding that got removed, not a load-bearing wall. The honest weak spot is the human evaluation, a single 2-dan player over five games, which proves the line was crossed but says nothing about by how much. The Lee Sedol match a few months later answered that. None of this dents the result. The game everyone said was a decade away fell, and it fell to a design simple enough to generalize.