Reflexion: Language Agents with Verbal Reinforcement Learning
An agent that gets better at a task by writing notes to itself about why it failed and reading them before its next try, learning without ever changing a single weight.

Read at your level
Start where you're comfortable and climb as far as you like.
- For a 5-year-old
- For a high schooler
- For a college student
- For an industry pro
- For a PhD candidate
- For a peer researcher
Executive summary
The usual way to make a model better at a task is to fine-tune it, which means feeding it many examples and slowly nudging its weights. That's slow and expensive, and for a big language model it needs a lot of compute. Reflexion skips all of it. An agent tries the task, gets a simple pass-or-fail signal, then writes a short note to itself about what went wrong. That note goes into a small memory, and the next attempt reads it before acting. The agent improves across a handful of tries without anyone touching its weights. On the HumanEval coding benchmark it hit 91% pass@1, past GPT-4's 80%. On AlfWorld household tasks it solved 130 of 134, a 22% jump over the baseline. The catch is that the whole thing rests on the agent judging its own work and writing a useful note. When the note misdiagnoses the mistake, the agent can get stuck repeating it, and there's no math guaranteeing it ever succeeds.
Try it
Load Reflexion and press play. Watch the first trial fail, a lesson appear in memory, and the success strip fill in over a few trials. Then load ReAct only and play again. With reflection off, the agent keeps walking into the same trap and the strip never goes green. Switch to Local minimum, where the self-reflection keeps misdiagnosing, and watch it churn through all 12 trials without solving. Then on the Reflexion preset, pause right after the first lesson lands, hit Corrupt last lesson, and step forward. The next trial repeats the mistake the agent had already fixed.
Reflection on, sharp self-reflection, memory of three lessons, an honest evaluator. The agent names each mistake and clears the task in a few trials.
Empty. The agent fails the first trial blind, then the self-reflection model writes its first lesson here. Step until a fail, then watch a line appear.
Press play or step to start the loop.
This runs the paper's Algorithm 1 over a four-step task, not a real LLM. The actor, evaluator, and self-reflection model are stand-ins whose behavior follows the paper's rules. "Mastered" counts the steps the agent now gets right because a correct lesson sits in memory. A weight never changes; the only thing that updates between trials is the text in the memory panel. The run is deterministic: same preset, same trajectory every time.
For a 5-year-old
Imagine you're trying to build a tall tower of blocks, but it keeps falling over. The first time, you don't know why. It just falls.
So you grab a little notebook and you draw what happened. "The tower fell because I put the big block on top of the small one." Now you try again. Before you start, you read your note. This time you put the big block on the bottom. The tower stands.
That's the whole trick. Try, fail, write down why, read your note, try again. Each time your note gets smarter, so you do too.
The funny part is your brain didn't change at all. You're the same kid. The only thing that changed is the note in your pocket. A robot can do the same thing. It keeps a little notebook of lessons, and reading the notebook is how it gets better, not by getting a new brain.
But the notebook only works if you write down the right reason. If you wrote "the tower fell because the floor was wobbly" when really you stacked the blocks wrong, you'll keep making the same mistake. A note is only as good as the thinking that wrote it.
For a high schooler
You've used an app that finishes your sentences or answers questions. Behind it is a language model, a huge program that learned from a mountain of text. Normally, to make that program better at a new job, engineers fine-tune it, meaning they run more training and slowly adjust the billions of numbers inside it. That's expensive and slow.
Reflexion gets the same kind of improvement a different way. Here's the one new idea for this section. The agent keeps an episodic memory, which is just a short list of notes about its own past attempts. It never changes the numbers inside the model. It only changes what's written in that list.
The loop is simple. The agent tries the task. Something checks the result and says pass or fail. If it failed, the agent writes a sentence explaining what it did wrong. That sentence gets added to the memory. On the next try, the agent reads its memory first, so it walks in already knowing the mistake to avoid.
Here's a concrete run. Say the task is a five-step puzzle and the agent botches step three on its first try. It writes "step three failed because I picked the locked door, I should pick the window." Next try, it reads that, picks the window, and clears step three. If there's still a later mistake, it writes another note. Over four or five tries the notes stack up and the agent solves the whole thing.
The improvement comes from better notes, not a better brain.
For a college student
You should care about this because it's one of the cleanest demonstrations that an agent can improve through pure in-context learning. No gradients, no fine-tuning, no labeled dataset. The only thing that updates between attempts is natural-language text in the prompt.
The motivation is cost. Traditional reinforcement learning improves a policy by computing gradients and updating weights, which for a large language model means a lot of compute and many samples. The authors ask whether you can get policy improvement from language alone. Treat the agent's memory as part of its policy. Improving the policy then means writing better text into that memory, which an LLM can do in one forward pass.
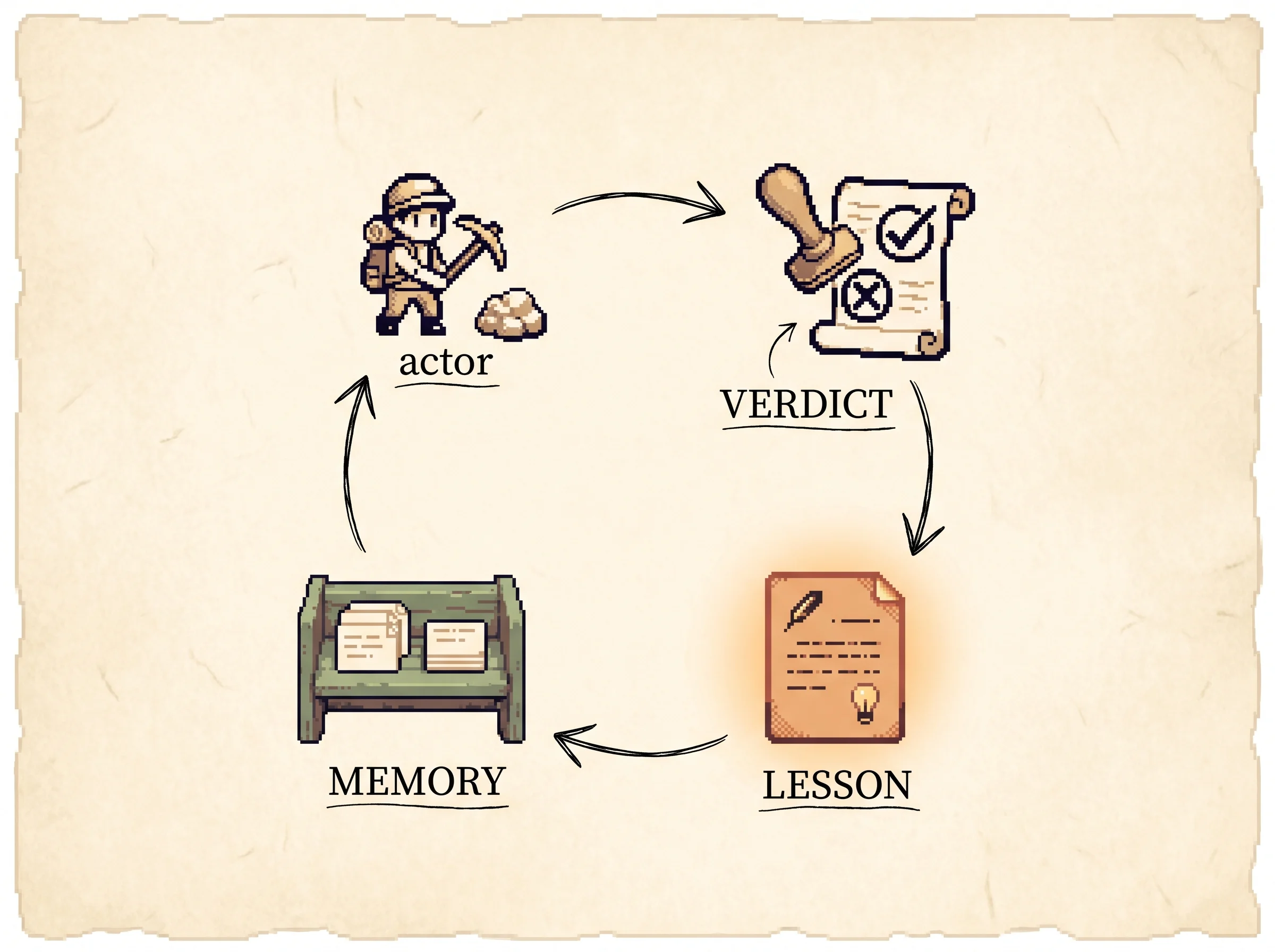
The framework has three models that pass a task around a loop. The Actor is an LLM that reads the current state plus its memory and produces an action. The Evaluator scores a finished trajectory and returns a reward, often just binary pass or fail. The Self-Reflection model is another LLM that reads the failed trajectory and its reward and writes a verbal lesson. That lesson lands in memory, which the Actor reads on the next attempt.
Here is the loop as the paper's Algorithm 1, in plain terms.
memory = []
trajectory = Actor.run(task, memory)
reward = Evaluator.score(trajectory)
while reward is not "pass" and trials_left:
reflection = SelfReflection.write(trajectory, reward, memory)
memory.append(reflection) # evict oldest if over capacity
trajectory = Actor.run(task, memory)
reward = Evaluator.score(trajectory)Walk one end-to-end path. Trial 0, the Actor runs blind because memory is empty, picks a wrong action at some step, and the Evaluator returns fail. The Self-Reflection model writes "I failed at step k because I did X, I should have done Y." Trial 1, the Actor reads that note before step k, does Y, and clears it. Repeat until the Evaluator says pass or the agent runs out of trials. The simulation above runs exactly this loop, one micro-step at a time, so you can pause between the Actor's move, the Evaluator's verdict, and the reflection.
The reward signal here is the gradient's stand-in. Where ordinary RL turns a scalar reward into a weight update, Reflexion turns it into a sentence. The authors call the reflection a "semantic gradient signal," because it points in a concrete direction to improve, the way a gradient does, but in words.
The honest limitation falls straight out of the design. There's no proof this converges. A bad reflection that misreads the failure can send the agent in circles, a local minimum it can't climb out of. And the memory is a fixed window, so old lessons drop off.
For an industry pro
The problem this solves for you is adapting an agent to a task without a training run. If you've got an LLM agent that fails a multi-step job, the standard fix is collecting data and fine-tuning, which is a project. Reflexion gets measurable improvement across a few attempts using only prompting, so the iteration loop is minutes, not days.
Deployment cost is low and mostly inference. You need an environment that returns a usable signal (a unit test result, a task-success flag, a binary classifier), an LLM call to write the reflection, and a small buffer to hold the last few reflections. The paper bounds that buffer to 1 to 3 entries to stay inside the context window, so memory growth isn't a concern. No GPUs for training, no labeled set.
The expected improvement is real and not marginal against an LLM-agent baseline. HumanEval Python pass@1 went from 80% to 91%. AlfWorld solved 130 of 134 tasks versus a stalling ReAct baseline. HotPotQA reasoning improved 20%. These are against current strong agents, not stale baselines.
Now the failure modes, because they decide whether this is safe to ship. The method's quality is capped by the agent's ability to judge its own work. For code, the agent writes its own unit tests, and a flaky test creates a false positive: tests pass on a wrong solution and the agent submits it, confident and wrong. The paper measures this. On MBPP Python the false-positive test rate was 16.3%, which dragged Reflexion below the GPT-4 baseline there, the one benchmark where it lost. Load the Flaky evaluator preset in the simulation to watch this happen. The agent reports a pass on a wrong answer and stops, and the honesty light flips. The other failure is the local minimum: if the self-reflection keeps misreading the mistake, the agent burns its trials without improving. If your environment can't give a trustworthy pass-or-fail signal, this method inherits that weakness directly.
For a PhD candidate
The contribution is framing policy improvement as memory editing in natural language, with no parameter updates. Prior self-improvement work for LLMs, like Self-Refine, refines a single generation within one episode conditioned on feedback. Reflexion's delta is persistence across episodes: it builds a long-term episodic memory of self-reflections that carries lessons from one full trial into the next, which is what lets it learn a task over a handful of trials rather than polish one output.
The methodological choices reward scrutiny. The Evaluator is deliberately swappable: exact-match grading for reasoning, hand-written heuristics for decision-making (flag a repeated action loop, or a trajectory longer than 30 steps), and an LLM-as-judge for the rest. The Self-Reflection model converts a sparse scalar into a dense verbal critique, which the authors argue carries more information than the scalar alone, because it can name the specific action that caused later errors and propose a replacement. That is the credit-assignment claim, and it's the crux. The memory is bounded to a sliding window of 1 to 3 experiences to respect the context limit, which trades long-horizon recall for tractability.
The ablations are the strongest part of the paper. On the 50 hardest HumanEval Rust problems, removing the self-reflection step (keeping test generation) drops accuracy to the 60% baseline, and removing test generation drops it to 52%, below baseline, because without tests the agent can't tell a correct solution from a wrong one and edits good code into bad. So both halves are load-bearing, and they interact. For HotPotQA, an episodic-memory ablation isolates the reflective step itself: adding the most recent trajectory to memory helps, but adding the verbal self-reflection on top adds another 8%, evidence that the gain is from reasoning about the failure, not just seeing the past.
Threats to validity worth probing. The success rests on the base model's self-evaluation, with no formal convergence guarantee, and the false-positive analysis on MBPP shows exactly where that bites. The trial counts are small, so variance across seeds matters and isn't deeply characterized. And "verbal reinforcement" is a useful metaphor, but the analogy to gradient-based policy optimization is loose: there's no objective being provably descended, just an LLM writing text it believes is corrective.
For a peer researcher
The delta against Self-Refine and other single-episode self-correction is persistence and credit assignment across trials. Self-Refine improves one generation in place. Reflexion maintains an episodic buffer of verbal critiques that survive across full episodes, so the policy at trial t conditions on distilled lessons from trials 0 through t-1. Frame the policy as the LLM plus its memory, and the "update" is appending text, which makes the whole thing in-context learning wearing an RL costume.
The choices read as deliberate tradeoffs. Binary or scalar reward amplified into free-form language is the central bet, that a verbal critique carries more actionable signal than the scalar, and the HotPotQA episodic-memory ablation is the cleanest evidence for it, an 8% lift from the reflective step over raw trajectory recall. The bounded memory window is a context-budget concession, not a principled design, and the authors flag vector stores as the obvious extension. Self-generated tests as the Evaluator for code is the riskiest choice, and they're honest about it: the MBPP Python regression traces directly to a 16.3% false-positive test rate, where passing tests certify a wrong solution.
What would change my mind on the central claim. If a no-memory baseline that simply re-prompts with the full failed trajectory matched Reflexion, the "reflection" would be doing nothing beyond context-stuffing. The ablation says it doesn't, the verbal step adds real signal. The honest soft spot is that everything rides on the base model's self-evaluation, and the paper says as much, betting that the paradigm only improves as models do. The open question they leave is the memory structure, where this sits today as a sliding window and where richer retrieval over a large experience store is the natural next move.
How it works
The problem and why prior approaches failed. LLMs are now used as goal-driven agents that act in environments like games, compilers, and APIs. Teaching such an agent a new task by the standard route means reinforcement learning with gradient descent, which needs many samples and expensive fine-tuning of a model with an enormous number of parameters. So in practice people fell back on in-context examples, which don't let the agent actually learn from its own trial-and-error. Earlier self-improvement methods like Self-Refine fixed a single output within one attempt but kept nothing across attempts, so they couldn't learn a multi-step task over several tries.
The key idea. Reinforce the agent through language, not weights. Convert the environment's pass-or-fail signal into a verbal summary of what went wrong, store that summary in an episodic memory, and feed it back as extra context on the next attempt. The reflection acts as a "semantic gradient," a concrete direction to improve stated in words. The agent's weights never change. Its memory does.
Methodology. Three models cooperate in a loop. The Actor M_a is an LLM (the paper uses Chain-of-Thought and ReAct variants) that generates the trajectory from the state plus memory. The Evaluator M_e scores a finished trajectory into a reward. The Self-Reflection model M_sr reads the trajectory and its reward and writes the verbal lesson. The lesson appends to memory mem, bounded by a capacity Omega usually set to 1 to 3 so the prompt stays inside the context limit.
Initialize Actor, Evaluator, Self-Reflection: M_a, M_e, M_sr
Generate initial trajectory t_0 using M_a
Evaluate t_0 using M_e
Generate initial reflection sr_0 using M_sr
mem <- [sr_0]; t = 0
while M_e not pass and t < max_trials:
Generate trajectory t_t using M_a (conditioned on mem)
Evaluate t_t using M_e
Generate reflection sr_t using M_sr
Append sr_t to mem
t = t + 1The Evaluator is the part that flexes per task. For reasoning they grade by exact match against the answer. For decision-making they use a hand-written heuristic, such as flagging the same action repeated more than three times, or a trajectory that runs past 30 steps as inefficient. For both decision-making and code they also try an LLM judging itself. For code in particular, the agent writes its own unit tests with Chain-of-Thought, keeps the syntactically valid ones, and runs the solution against them, which is what makes the coding setup eligible for honest pass@1 reporting.
Results with effect sizes. On AlfWorld, ReAct plus Reflexion solved 130 of 134 tasks and kept improving over 12 trials, where the ReAct-only baseline flatlined between trials 6 and 7 and converged with a 22% hallucination rate that never recovered. On HotPotQA reasoning, Reflexion beat the baselines by 20%, and an ablation that isolated the reflective step over raw trajectory memory showed an 8% gain from the reflection itself. On code, Reflexion hit 91% pass@1 on HumanEval Python (past GPT-4's 80%), 68% on HumanEval Rust, and set a 15% mark on the new LeetcodeHardGym. The one loss was MBPP Python, 77.1% versus the 80.1% baseline, traced to a 16.3% false-positive rate in the self-generated tests.
The memory has an edge. It holds only the last few lessons, so a fresh reflection can push an old one out of the window and the agent forgets a fix it already found.

In the simulation, build up a couple of lessons on the Reflexion preset, then drag the memory window down to 1 and watch the oldest lesson get evicted, so a step the agent had mastered can break again.
Limitations and open questions. Reflexion is policy optimization done in natural language, so it can still get stuck in a non-optimal local minimum, a bad reflection that keeps misdiagnosing. The memory is a bounded sliding window, and the authors point to vector embedding stores or SQL databases as richer alternatives. For code, test-driven self-evaluation struggles with non-deterministic functions, impure functions that call APIs, and anything hardware- or concurrency-dependent. And there's no formal guarantee of success, the whole loop leans on the LLM's self-evaluation being good enough.
My assessment
The authors got the central call right, and the field followed. Treating an agent's memory as its policy and improving it by writing text turned out to be a genuinely useful primitive, and self-reflection loops over tool feedback are now standard in agent frameworks. The cheap parts carried the most weight, exactly as you'd want. The reflection is one extra LLM call, the memory is three lines of text, and that's enough to turn a stalling ReAct agent into one that solves 130 of 134 AlfWorld tasks.
The ablations are where the paper earns trust. Stripping the self-reflection step drops performance to baseline, and stripping the self-generated tests drops it below baseline, which proves both halves are doing work and that they interact. A lot of agent papers would have shown the headline number and moved on. This one shows you where it breaks, and the MBPP Python loss is reported plainly with the false-positive rate that explains it, instead of buried.
The honest soft spot is the one the title invites. Calling this "reinforcement learning" is a strong frame for what is, mechanically, clever in-context prompting with a memory. There's no objective provably descended and no convergence guarantee, and the local-minimum failure is real, you can watch it in the simulation. But the metaphor is productive rather than misleading, because it names the right analogy: the reward signal becomes a direction to improve, just rendered in words a model can read. The open question the paper leaves wide, what memory should be once you outgrow a three-line window, is exactly where retrieval-augmented agents went next.