Direct Preference Optimization: Your Language Model is Secretly a Reward Model
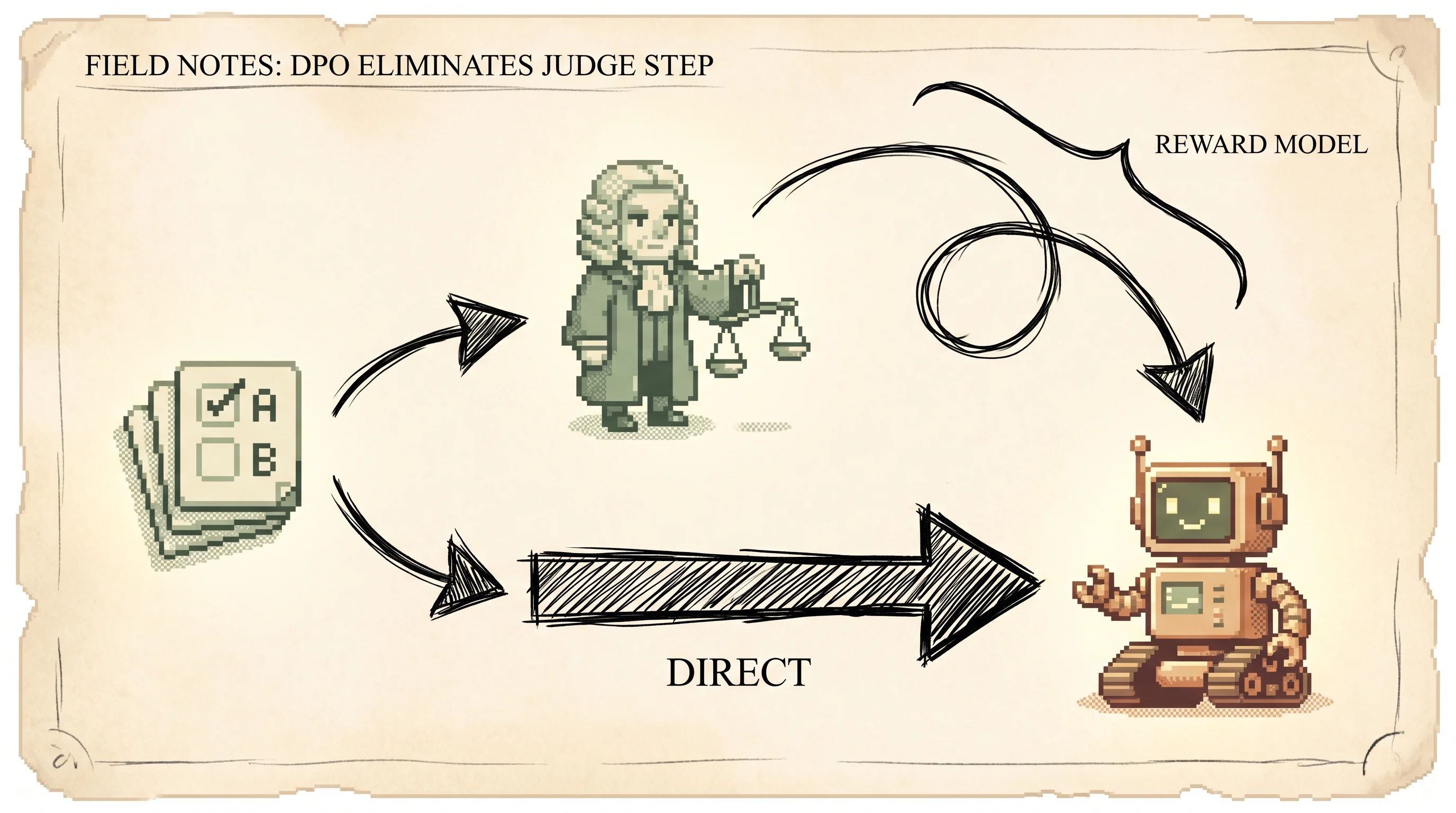
A way to teach a language model what people prefer in one direct training step, skipping the separate reward model and reinforcement learning that the old recipe needed.
Read at your level
Start where you're comfortable and climb as far as you like.
- For a 5-year-old
- For a high schooler
- For a college student
- For an industry pro
- For a PhD candidate
- For a peer researcher
Executive summary
To make a language model helpful instead of just fluent, people show it pairs of answers and mark which one is better. The old way to learn from those marks, called RLHF, took two big steps. First it trained a separate scorer, a reward model, to guess how good any answer is. Then it ran reinforcement learning to push the language model toward high-scoring answers, sampling fresh answers in a loop the whole time. That loop is slow, fiddly, and prone to falling apart. DPO shows the two steps fold into one. The optimal model under the old objective has a closed-form shape, and once you write it out, the reward turns out to be a simple ratio you can read straight off the model itself. So you can drop the reward model and the reinforcement learning and just train the language model on the preference pairs with a plain classification loss. It's stable, it's cheap, and in the paper's tests it matched or beat RLHF with PPO on sentiment control, summarization, and dialogue, on models up to 6B parameters. The catch is that it still needs a fixed batch of preference data collected up front, and the setting beta that controls how far the model may drift carries over from the old recipe unchanged.
Try it
Load the Align to preferences preset and press play. Watch the preferred reply's bar climb while the policy stays close to the sage tick that marks where it started. Now load Drop the sigma weight and play again. The same data with the adaptive weight turned off shoves the winner toward 100 percent and the KL number runs away, which is the degeneration the paper warns about. Then load Mislabel a pair, or click any preference pair to flip it mid-run, and watch the model faithfully chase the wrong answer up.
The honest dataset and a steady beta. Play it and watch the preferred reply climb while the policy stays close to the reference.
The reward is beta times the log of how much likelier the policy makes this reply than the reference does. No reward model was trained; the policy is the reward model. The gradient leans on the pair by beta times sigma(reward of the loser minus reward of the winner), so a pair already ranked right barely moves.
Step, drag a slider, or flip a pair to start the log.
This runs the exact DPO loss and its gradient over 2 prompts with 4candidate replies each, where a real run works over a full vocabulary of completions. The policy starts as a copy of the reference, and the reward is beta times log pi(y)/pi_ref(y), exactly the paper's implicit reward. The reference starts at a uniform distribution (seed fixed for determinism); every run of the same preset produces the same result.
For a 5-year-old
Imagine a puppy you want to teach good tricks. You show the puppy two tricks and point at the better one. "This one." You do it again. "This one." Over and over, you just point at the better trick, and the puppy slowly learns to do the kind of trick you keep pointing at.
The old way needed a helper. First you'd hire a judge to watch all the tricks and give each one a score out of ten. Then the puppy would try tricks and chase the judge's high scores. Two jobs, two helpers, lots of waiting.
The new way skips the judge. You point at the better trick, and the puppy learns straight from your pointing. No judge, no scores, just "this one is better than that one," again and again.
A real model doesn't have a puppy or a finger. The pointing is math. Each answer gets a number for how likely the model is to say it, and the model nudges the better answer's number up and the worse one's number down. But the feeling is the same. You show what's better, and it learns to do more of that.
For a high schooler
You've used a phone that finishes your sentences. A language model is that, scaled way up. It can write paragraphs, but out of the box it doesn't know which paragraph you'd actually like. So people collect preference data. They show the model's answers to humans in pairs and the humans pick the better one in each pair.
Here's the one new idea for this section. The old recipe, called RLHF, which stands for reinforcement learning from human feedback, did this in two stages. Stage one trained a reward model, a second network whose only job is to look at an answer and output a score for how good it is. Stage two took the language model and trained it to produce answers the reward model scores highly, using a trial-and-error method called reinforcement learning. The model would generate an answer, get scored, adjust, generate again, in a loop. That loop is expensive and unstable.
DPO's trick is to notice that you never needed the separate scorer. The score is already hiding inside the language model. Take any answer, look at how likely the trained model is to say it, and compare that to how likely the original untrained model was. If the trained model got a lot more likely to say it, that answer is one the model now thinks is good. That comparison is the score.
Here's a worked example with tiny numbers. Say for some question, answer A and answer B. A human marked A as better. The model raises how likely it is to say A and lowers how likely it is to say B, just enough to get the pair in the right order. No second network, no loop. One pass of ordinary training, the same kind that recognizes cats in photos, does the whole job.
So instead of building a judge and then chasing the judge, you teach the model to rank the answers the way people did.
For a college student
You should care about this because DPO is now the default way to align open language models, and it replaced a pipeline that was a genuine pain to run. The motivation is the cost and instability of RLHF. The standard RLHF objective is a KL-constrained reward maximization. Given a reference policy pi_ref (your starting supervised model) and a reward r(x, y), you want a policy pi_theta that maximizes reward while not drifting too far from the reference.
max_pi E_{x ~ D, y ~ pi}[ r(x, y) ] - beta * KL( pi(y|x) || pi_ref(y|x) )That beta controls the leash. A bigger beta keeps the trained policy closer to the reference.

Now the key move. This objective has a known closed-form solution. The optimal policy is
pi_r(y|x) = (1 / Z(x)) * pi_ref(y|x) * exp( r(x, y) / beta )where Z(x) is a normalizing sum over all answers, hopeless to compute directly because there are exponentially many answers. The old recipe got stuck here, which is why it fell back on reinforcement learning. DPO refuses to get stuck. Take the log and solve for the reward instead.
r(x, y) = beta * log( pi_r(y|x) / pi_ref(y|x) ) + beta * log Z(x)So the reward is just beta times the log-ratio of the policy to the reference, plus a term that depends only on the question x, not on the answer.

Here's why that log Z(x) term stops being a problem. Human preferences follow the Bradley-Terry model, which says the chance you prefer answer 1 over answer 2 depends only on the difference of their rewards. When you subtract two rewards for the same question, the beta * log Z(x) term is identical in both, so it cancels. The preference probability comes out in terms of the policy alone. Plug that into the same maximum-likelihood loss you'd use to fit a reward model, and you get the DPO objective.
L_DPO = -E_{(x, y_w, y_l) ~ D}[ log sigma( beta*log(pi_theta(y_w|x)/pi_ref(y_w|x)) - beta*log(pi_theta(y_l|x)/pi_ref(y_l|x)) ) ]Read it as a classifier. For each pair, y_w is the preferred answer and y_l the dispreferred one. The term inside sigma is the margin by which the model's implicit reward favors the winner. The loss is just binary cross-entropy pushing that margin to be positive. One worked path, end to end. Start with the supervised model. For each labeled pair, raise the log-probability of y_w and lower that of y_l, weighted by how badly the current model has the pair backwards. Repeat over the dataset. That's the whole algorithm, and the simulation above runs exactly this loss and its gradient.
The limitation falls out of the setup. You still need a fixed dataset of preferences gathered ahead of time, and you still pick beta by hand. DPO solves the optimization, not the data collection.
For an industry pro
The problem it solves for you is the operational nightmare of RLHF. PPO-based RLHF means standing up a reward model, then running an RL loop that samples from your policy on every step, juggles a value network, and is famously sensitive to hyperparameters. DPO collapses that into a single supervised-style training run on a static preference dataset. No reward model to train and serve, no sampling in the loop, no PPO to babysit.
Deployment cost drops on every axis. You need the policy and a frozen reference copy in memory during training, plus the preference pairs. That's it. There's no online generation during the update, so a DPO run looks like ordinary fine-tuning and finishes far faster. The paper reports almost no hyperparameter tuning was needed, where PPO runs usually demand a sweep.
The expected improvement is real, not marginal. On the IMDb sentiment task, DPO sits on the best reward-versus-KL frontier of every method tested, beating even a PPO that was handed the ground-truth reward. On Reddit TL;DR summarization, DPO won about 61 percent of GPT-4 judgments against the reference summaries at temperature 0, against PPO's best of roughly 57 percent, and DPO held up as sampling temperature rose while PPO degraded toward the base model. On Anthropic-HH dialogue, DPO was the only method that beat the dataset's own chosen answers.
The failure modes to plan around. DPO is exactly as good as your preference data. The simulation makes this blunt. Mislabel a pair and DPO will faithfully optimize toward the bad answer, with no reward-model smoothing to hide behind. The beta setting still matters and you still tune it, since too small lets the model drift and over-optimize, too large barely moves it. And this is offline learning on a fixed batch, so if your data doesn't cover the answers your deployed model will actually produce, you're extrapolating.
For a PhD candidate
The contribution is a change of variables that turns the RLHF reward-modeling-plus-RL pipeline into a single maximum-likelihood problem over the policy. Prior work fit an explicit reward under Bradley-Terry, then optimized it with PPO under a KL constraint, eating the variance and instability of policy-gradient RL plus the cost of a learned value baseline. DPO uses the analytic solution of the KL-constrained objective, pi_r proportional to pi_ref * exp(r/beta), inverted to express r as beta * log(pi/pi_ref) + beta * log Z(x), and exploits the fact that Bradley-Terry depends only on reward differences so the intractable partition function cancels.
The methodological choices reward scrutiny. The DPO gradient is the tell.
grad L_DPO = -beta * E[ sigma(r_hat(x, y_l) - r_hat(x, y_w)) * ( grad log pi(y_w|x) - grad log pi(y_l|x) ) ]where r_hat(x, y) = beta * log(pi_theta(y|x)/pi_ref(y|x)) is the implicit reward. The sigma(r_hat_l - r_hat_w) factor is an adaptive per-example weight. When the implicit reward already orders a pair correctly, the weight is near zero and the example contributes almost nothing. When the model has the pair backwards, the weight is large.
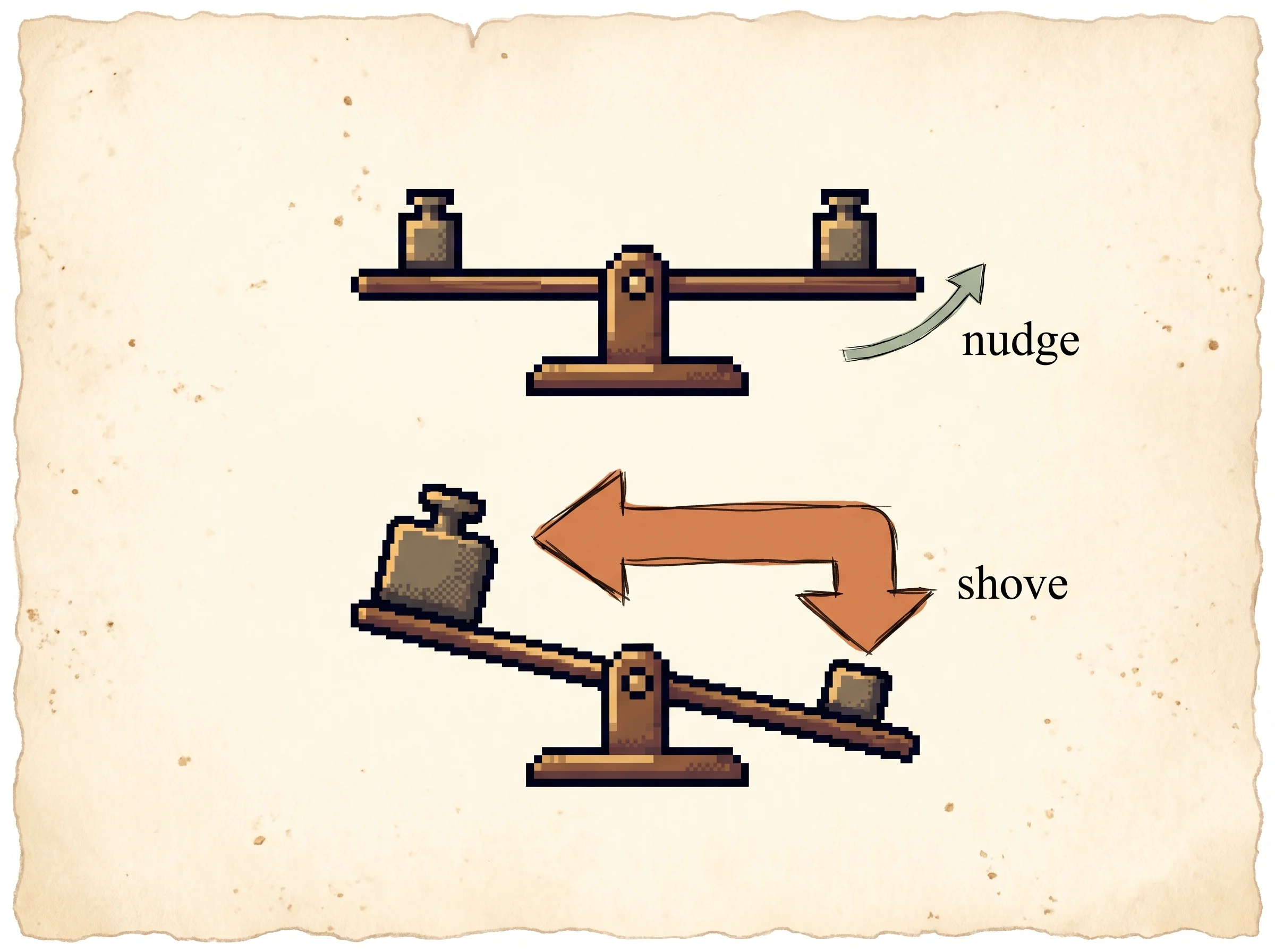
The paper's Appendix Table 3 shows that dropping this weight, optimizing the bare log-ratio margin, degenerates the policy. The simulation reproduces that. Toggle the adaptive weight off and the preferred mass collapses toward one while the KL runs away.
Threats to validity worth probing. The theoretical equivalence to RLHF holds under the Bradley-Terry preference model and assumes pi_ref matches the distribution the preferences were collected on; when no SFT model is available the authors fit pi_ref by maximum likelihood on the preferred completions, which is a distribution-shift patch. The empirical claims rest on models up to 6B parameters with GPT-4 as the proxy judge, validated against humans but still a proxy. And beta was barely tuned, which the authors note may understate DPO. The natural follow-ups are out-of-distribution generalization of DPO policies versus explicit-reward policies, whether reward over-optimization appears in the direct setting, and scaling to frontier model sizes.
For a peer researcher
The delta against RLHF is that the reward model and the RL stage both vanish, replaced by one classification loss on the policy. The mechanism is the closed-form KL-constrained optimum inverted into a reward parameterization r(x, y) = beta * log(pi/pi_ref) + beta * log Z(x), with the partition function cancelling under Bradley-Terry's difference structure. Theorem 1 shows this reparameterization loses no generality. Every reward equivalence class (rewards differing by a prompt-only function induce the same Bradley-Terry preferences and the same optimal policy) contains a representative of the form beta * log(pi/pi_ref), so constraining to that family preserves the representable preference distributions while making the optimal policy analytically available.
The choices read as deliberate. The implicit reward is exactly what the policy log-ratio gives you, so there's no separate reward to over-optimize against, and the authors frame DPO's stability through the actor-critic lens of Section 5.2, where the troublesome normalization term in PPO's objective is the soft value function that DPO never has to estimate. The adaptive sigma weighting is not a design knob but a consequence of differentiating the logistic loss, and it's load-bearing, since the unweighted version degenerates.
What would change my mind on the central claim. If DPO policies generalized markedly worse out of distribution than reward-model-based policies, the equivalence would be theoretically clean but practically hollow, because the explicit reward might regularize in ways the implicit one doesn't. The initial CNN/DailyMail transfer result has DPO ahead of PPO, but it's one experiment. The honest soft spots are the dependence on the fixed offline dataset, the unexamined reward-over-optimization question the authors raise themselves, and the absence of frontier-scale evidence in this paper.
How it works
The problem and why prior approaches failed. A pretrained language model knows a lot but produces whatever the internet taught it, helpful and harmful mixed together. Aligning it to human preferences means collecting pairwise judgments and steering the model toward the preferred kind of answer. RLHF did this in three phases. Supervised fine-tuning to get a base model pi_ref. Reward modeling, fitting a network r_phi(x, y) to the preferences under the Bradley-Terry likelihood. RL fine-tuning, using PPO to maximize the learned reward minus a KL penalty against pi_ref. The reward model and the RL loop are the pain. RL over language is high-variance, needs a value network, samples from the policy every step, and is sensitive enough that getting it to work is its own research skill.
The key idea. You never needed to separate reward learning from policy learning. The KL-constrained objective has a closed-form optimum, and inverting it expresses the reward as a log-ratio of the policy to the reference. Because preferences depend only on reward differences, the awkward normalizing term cancels, and the whole problem becomes one maximum-likelihood fit on the policy.
Methodology. Start from the RLHF objective and its known solution.
pi_r(y|x) = (1/Z(x)) * pi_ref(y|x) * exp( (1/beta) * r(x, y) )Solve for the reward.
r(x, y) = beta * log( pi_r(y|x) / pi_ref(y|x) ) + beta * log Z(x)Substitute into the Bradley-Terry preference probability p(y_w > y_l) = sigma(r(x, y_w) - r(x, y_l)). The beta * log Z(x) terms are equal and cancel, leaving the preference expressed in the policy alone. Fitting that by maximum likelihood gives the DPO loss.
L_DPO(pi_theta; pi_ref) = -E[ log sigma( beta*log(pi_theta(y_w|x)/pi_ref(y_w|x)) - beta*log(pi_theta(y_l|x)/pi_ref(y_l|x)) ) ]In practice you reuse a public preference dataset, set pi_ref to your SFT model, pick beta, and minimize the loss with ordinary gradient descent. When no SFT model exists, the authors set pi_ref by maximizing the likelihood of the preferred completions first, to keep the reference in the right distribution.
Results with effect sizes. On controlled IMDb sentiment generation, where the true reward is a known classifier, DPO traced the best reward-versus-KL frontier of all methods and beat PPO even when PPO was given the ground-truth reward. On Reddit TL;DR summarization, DPO reached about 61 percent win rate against reference summaries at temperature 0 by GPT-4 judgment, above PPO's roughly 57 percent peak, and stayed robust as sampling temperature climbed while PPO collapsed toward the base model. On Anthropic-HH single-turn dialogue, DPO was the only method to improve over the dataset's chosen completions and matched or beat the expensive Best-of-128 baseline. A human study confirmed GPT-4 judgments agreed with people about as often as people agreed with each other.
Limitations and open questions. DPO learns offline from a fixed preference batch, so it can't fix gaps the data doesn't cover, and a mislabeled pair gets optimized toward faithfully. beta is still a hand-set knob. The authors flag open questions about out-of-distribution generalization compared to explicit-reward policies, whether reward over-optimization shows up in the direct setting, and scaling beyond 6B parameters.
My assessment
The authors got the central call right, and the field moved fast to agree. DPO became the default alignment method for open models within about a year, because it deleted the two hardest parts of RLHF and lost little or nothing in quality. The derivation is the kind of result that looks obvious only in hindsight. The closed-form optimum of the KL-constrained objective had been known for years, and the Bradley-Terry cancellation is a couple of lines, yet nobody had connected them to retire the reward model and the RL loop. That's the mark of a good paper, a small move with a large blast radius.
The adaptive sigma weight is the piece I'd flag as underappreciated by casual readers. It looks incidental, just the derivative of a logistic, but it's the whole difference between learning and degenerating, and the simulation makes that visceral. Where the paper is honestly thin is the question it raises and doesn't answer, whether dropping the explicit reward costs you anything in generalization or invites a different flavor of over-optimization. Later work found that it does have failure modes the explicit-reward setting smooths over, which is why the alignment literature keeps producing DPO variants. None of that dents the core contribution. The reward model really was hiding inside the language model the whole time.