Process Reinforcement through Implicit Rewards
A way to reward an AI for every reasoning step, not just the final answer, using a reward model that comes free from the language model itself and stays honest by updating online.
Read at your level
Start where you're comfortable and climb as far as you like.
- For a 5-year-old
- For a high schooler
- For a college student
- For an industry pro
- For a PhD candidate
- For a peer researcher
Executive summary
When you train a model to solve math by reinforcement learning, you usually only get to grade the final answer. Right or wrong, one bit at the end. That makes it hard to teach, because a long solution can be right for the wrong reasons or wrong because of one slip near the start, and the single end grade can't tell those apart. People knew that a score on every step would train faster and assign credit better, but getting those step scores meant building a separate reward model on hand-labeled steps, which costs too much and gets gamed the moment the policy drifts away from it. PRIME gets the step scores for free. It uses a result that any language model trained with the usual loss on final-answer labels already encodes a per-token reward, the log-ratio of its own next-token probability to a frozen copy's. So you skip the separate reward-model training stage entirely, and you keep that reward honest by retraining it on fresh rollouts every step. Starting from Qwen2.5-Math-7B, PRIME lifts average accuracy on hard reasoning benchmarks by 15.1% over the supervised model, hits 2.5 times the sample efficiency of outcome-only RL, and the 7B result beats Qwen's own instruct model on seven benchmarks while using a tenth of the data. The cost is one extra forward pass per step for the reward and a reward model that you now have to keep updating, which the paper argues is the whole point.
Try it
Load the Online PRIME preset and press play. True accuracy and the reward climb together, and the PRM accuracy light stays green. Now load Frozen reward hacks, press play, and once it's running hit Inject shortcut. The reported reward keeps climbing to 100% while true accuracy collapses and the gap light flips to "Reward hacking". That split is the failure the online update prevents. Switch the PRM: frozen toggle back to online mid-run and watch the reward reconnect to the truth.
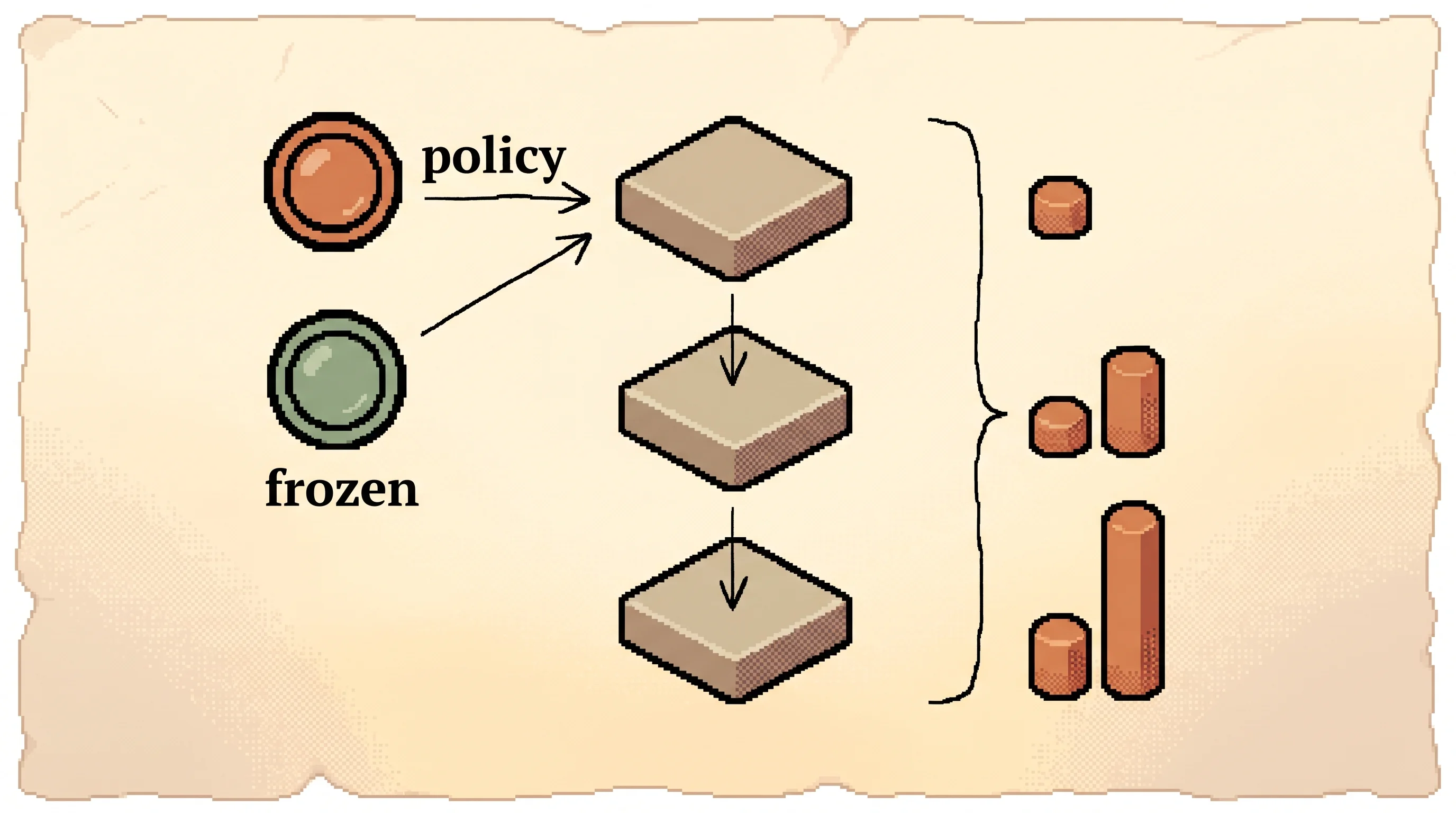
The full method. The implicit PRM starts from the SFT model and updates on every batch of rollouts. Play and watch true accuracy and reported reward climb together while PRM accuracy holds.
| rollout | verifier | process r | advantage |
|---|---|---|---|
| Step once to sample a batch of rollouts. | |||
Step, flip a control, or inject the shortcut to start the log.
The implicit reward here is exactly equation 3, beta times log of the policy model's token probability over the frozen reference's. The branch has three moves where the paper's model has thousands of tokens, and the outcome verifier is a clean rule where the paper's is exact-match on math and unit tests on code. The online cross-entropy update on rollouts is Algorithm 1's line 8, the one thing that keeps the reward honest. Every run is fully deterministic: the same preset always produces the same trajectory. Reset restores the preset from scratch.
For a 5-year-old
Imagine you're learning to bake cookies with a friend who tastes everything. The old way, your friend only tastes the very last cookie and says "yum" or "yuck". If the last cookie is bad, you don't know which step you messed up. Did you add too much salt? Forget the sugar? You just know the end was wrong.
The new way, your friend tastes the dough at every step. After you crack the eggs, taste. After the flour, taste. After the sugar, taste. Now when something goes wrong you know exactly where, because your friend told you "this step got worse" the moment it did.
The clever trick is where the friend comes from. You don't have to go find a special taster. You make a copy of yourself from before you started learning today, freeze that copy, and the friend is just you comparing what you do now against what the frozen copy would have done. If you got more sure about a step than the frozen copy was, that step gets a happy point.
A frozen copy can be fooled, though. So real friends don't stay frozen, they keep tasting your new cookies and learning. The friend gets updated again and again, which is math with numbers, not a real person eating dough. Keep the friend learning and you can't trick them. Freeze the friend and you can.
For a high schooler
Your phone's keyboard predicts your next word. A language model is a giant version of that, and you can train it to solve math problems by letting it write out a solution and then telling it whether the final answer was right. That's reinforcement learning. The hard part is the feedback. Telling the model "your final answer was wrong" after a 30-step solution is like a coach who only times your final sprint and never watches your form. You finished slow, but was it your start, your turn, your breathing? One number at the end can't say.
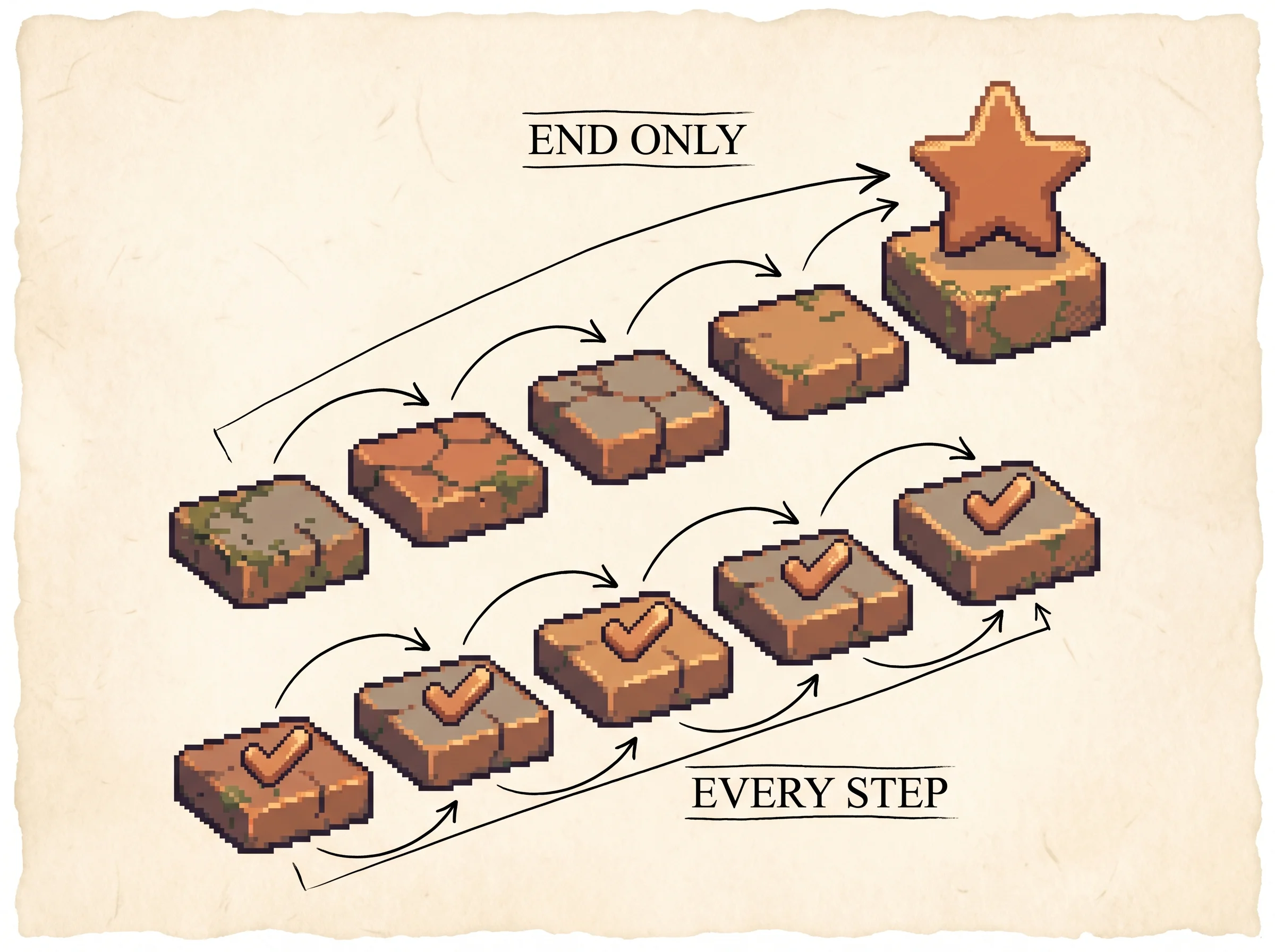
Here's the one new term for this section. A reward is the score the model is trying to make bigger. An outcome reward is one score at the very end. A process reward is a score on every step. Process rewards train better because they point at the exact step that helped or hurt.
The problem was always where the step scores come from. You'd have to pay people to read thousands of solutions and grade every step, then train a separate model to copy those grades. Expensive, and it breaks. PRIME found a shortcut. It turns out that if you train a model the normal way, just on whether the final answer was right, that model secretly already knows how to score steps. You read out the score like this. Take the model you're training, and take a frozen copy of where it started. For each step, ask both "how likely is this step?" The score for that step is how much more the trained model likes it than the frozen copy does.
Quick numbers. Say a good step gets log-ratio 0.5 and a bad step gets minus 0.4. Multiply by a knob the paper calls beta, say 0.6, and the good step earns +0.3, the bad step earns minus 0.24. Now every single step has a number, and you never paid anyone to label a step.
There's a catch you can feel coming. A frozen scorer can be tricked. If the model finds a sentence that the scorer happens to like but that's actually wrong, it'll spam that sentence and the score goes up while the answers get worse. So PRIME keeps re-teaching the scorer on the model's newest attempts, checked against the real right answers, so the scorer never stays foolable for long.
For a college student
You should care about this because it's the recipe behind a class of strong open math-and-code reasoning models, and it makes dense-reward RL for language models cheap enough to actually use. Start with the setup. In RL for an autoregressive model, the state at step t is the prompt plus the tokens generated so far, the action is the next token y_t, and you optimize the policy π_θ to maximize return. The policy gradient uses an advantage A_t, which is the discounted future reward minus a baseline.
The trouble is reward sparsity. In the standard setup only the final token carries a reward, r(y_t) = 0 for t < T and r(y_T) is the 0-or-1 outcome. The advantage collapses to A = r(y_T) - b, the same number smeared across every token. That causes three problems. It rewards right answers reached by wrong reasoning, it wastes samples, and it makes credit assignment hard because the signal at the end has to travel back through the whole sequence.
Dense rewards fix that, if you can get them. A process reward model (PRM) scores each step. The catch is building one. You need step labels, which are expensive, and the model gets overoptimized as the policy moves away from the data the PRM saw.
The key idea is the implicit process reward. A prior result (Yuan et al.) showed that if you train a reward model π_φ with the ordinary cross-entropy objective on outcome labels, parameterizing the reward as r_φ(y) = β log(π_φ(y) / π_ref(y)), then the per-token reward you can read out is
r_φ(y_t) = β · log( π_φ(y_t | y_<t) / π_ref(y_t | y_<t) )That's a process reward at every token, and you got it from a model trained only on outcome labels. No step labels, ever. Because π_φ is just a language model, you initialize it from the model you already have (the SFT model) instead of training a reward model from scratch.
PRIME runs this inside the training loop. Each iteration samples K responses per prompt, grades them with an exact rule-based verifier (match for math, fraction of passing tests for code), reads out the token rewards with the equation above, and forms the advantage by combining a leave-one-out baseline on the process rewards with a leave-one-out baseline on the outcome rewards.
A_t = [ Σ_{s≥t} γ^{s-t} ( r_φ(y_s) - mean_{j≠i} r_φ(y^j) ) ] (implicit process)
+ [ r_o(y^i) - mean_{j≠i} r_o(y^j) ] (outcome)Then the crucial move. It updates π_φ online, by cross-entropy against the same outcome labels, on the fresh rollouts.
L_CE(φ) = - E [ r_o(y) · log σ(r_φ(y)) + (1 - r_o(y)) · log(1 - σ(r_φ(y))) ]This is what keeps the reward from being gamed. A static reward model drifts as the policy moves, and the policy learns to exploit the drift. Retraining the reward on each new batch, checked against ground-truth outcomes, pins it back to reality.
The worked path. The policy proposes a sound solution and a fluent shortcut that reaches the right number through wrong reasoning. The verifier marks the shortcut wrong. With a frozen reward that happens to like the shortcut's surface form, the process reward keeps paying out for it, the policy piles onto the shortcut, and reported reward climbs while accuracy drops. With the online update, the next batch re-grades the shortcut against the verifier, the reward model's preference for it gets pushed down, and the policy is pulled back to the sound path. The simulation runs exactly this.
The limitation is honest and small. You pay one extra forward pass per step for the reward model, about 24% more wall-clock per step in their measurements, and you now maintain a model that updates rather than a fixed one. Because PRIME hits the same reward in 40% of the steps, the net is still about 2x faster.
For an industry pro
The problem this solves for you is credit assignment and sample efficiency in RL fine-tuning for reasoning, without the cost and fragility of a separate process reward model. Today, if you do outcome-only RL (the GRPO or RLOO style most teams run), you're smearing one terminal reward across a long trajectory. It works, but it's sample-hungry and it happily reinforces lucky-but-wrong reasoning. The alternative everyone wanted, dense step-level rewards, has been blocked by two costs. Step labels are expensive to collect, and a fixed reward model gets reward-hacked as your policy moves off its training distribution.
PRIME removes both costs. The reward model needs no step labels, only the same outcome labels you already have, because the per-token reward is read out as a log-probability ratio against a frozen reference. And you initialize the reward model from your SFT checkpoint, so there's no dedicated reward-modeling stage to build, staff, and maintain. That's the deployment win. You delete a whole pipeline.
What it costs to run. One extra forward pass per training step for the implicit PRM, roughly 24% more time per step. The reward model updates online, so you keep it in the training loop rather than freezing it. On their hardware the single-controller setup offloads the policy and rollout engine to CPU during the PRM update, so it added no extra GPU memory. Net efficiency is about 2x over outcome-only RL because you reach the same reward in 40% of the steps.
The expected improvement against your current outcome-only baseline is real. 6.9% higher final reward, 2.5x sample efficiency, and consistent gains on downstream test accuracy, not just training reward. The 7B model beat the vendor's own instruct model on seven benchmarks with a tenth of the data. It also drops into REINFORCE, RLOO, PPO, and GRPO as an advantage-function change, so you don't rewrite your trainer.
The failure mode to plan around is the one the simulation makes vivid. If you freeze the reward model to save the update cost, you reopen the reward-hacking door, and the paper's Figure 5 shows the frozen reward's accuracy sliding through training while the online one holds. The online update isn't optional polish, it's the safety mechanism. Their other finding worth banking is that the implicit PRM used as a reward beats a learned value model used as a baseline, so if you were reaching for a value head, this is the better spend.
For a PhD candidate
The contribution is making dense-reward online RL for LLMs scalable by sidestepping both the labeling cost and the overoptimization that have kept PRMs out of large-scale training. Prior dense-reward work either built PRMs on expensive step annotations (Lightman et al.) or used estimation-based rollout methods that need roughly 10x more rollouts per step (Wang et al., Kazemnejad et al.), and neither is scalable online. DeepSeek and others reported similar conclusions and stuck with verifiable outcome rewards. PRIME's delta is to instantiate the implicit-reward parameterization (Rafailov's DPO-as-Q result, generalized by Yuan et al. to any objective optimizing the log-ratio reward) inside the online loop, so the reward model is a language model you already have and update with the outcome labels you already collect.
The methodological choices reward scrutiny. The advantage in Eq. 5 keeps the implicit-process return and the outcome return as separate leave-one-out-baselined terms summed at the end, rather than mixing reward values directly, which they justify on numerical-stability grounds (citing the GRPO authors on value mixing). The reward-model update is cross-entropy against ground-truth outcomes on the on-policy rollouts, which is exactly what makes the online PRM track the shifting policy distribution. They choose Monte Carlo advantage estimators over GAE after finding MC strong enough, and instantiate with the RLOO leave-one-out baseline.
The ablations are where the paper earns trust. SFT-initialized PRM beats a specially-trained EurusPRM that saw 500K extra examples (Figure 4), which they attribute to the policy and PRM starting from the same model, so the PRM only ever fits the policy's own online rollouts and the distribution-shift gap stays small. Online beats offline directly (Figure 5), with the offline PRM's classification accuracy degrading over training while the online one rises, the cleanest evidence that overoptimization is the real enemy and the online update is the fix. And the Section 5.4 comparison shows the implicit PRM as a reward beats both a linear-head value model and the implicit PRM used as a value model, so the gain is about reward quality, not just having an extra critic.
Threats to validity worth probing. The verifier is exact rule-based reward, which is unhackable but limits the domains to math and code where you have a checker, so the "only outcome labels" claim quietly assumes a reliable outcome oracle. The reward-hacking story is demonstrated on these verifiable tasks; how the online update behaves when the outcome signal itself is noisy or learned is open. And the leave-one-out baseline needs K rollouts per prompt, so the sample-efficiency comparison is at fixed K. The follow-ups the paper invites are non-verifiable domains, the interaction of beta with the update rate, and whether the online PRM can drift if the policy collapses onto a narrow distribution.
For a peer researcher
The delta against prior dense-reward RL is that the reward model stops being a separate artifact you train and freeze, and becomes a language model you initialize from the policy's own SFT checkpoint and update online with the outcome labels you already have. The implicit-reward parameterization (Rafailov, generalized by Yuan et al.) is the enabling result, r_φ(y_t) = β log π_φ/π_ref is a free per-token reward from an outcome-trained model. PRIME's move is to put the update inside the RL loop and show the online cross-entropy step is what defeats overoptimization, the failure that sank fixed PRMs.
The design reads as deliberate tradeoffs. Keeping process and outcome returns as separately-baselined LOO terms summed at the end trades a tiny bit of coupling for numerical stability over mixing reward magnitudes. SFT-initializing the PRM trades the expressivity of a purpose-trained reward model for a tight distribution match to the policy, and the ablation says the match wins, the SFT-init PRM beats a PRM trained on 500K extra examples. Using the implicit PRM as a reward rather than as a value model trades the variance reduction of a critic for the credit-assignment quality of a dense reward, and Section 5.4 says reward beats value for both kinds of value model.
What would change my mind on the central claim. The whole story rests on an exact, unhackable outcome verifier, so the "only outcome labels" framing is really "only outcome labels plus a perfect oracle." If the online PRM still resisted hacking under a noisy or learned outcome signal, the claim would generalize past math and code; if it didn't, the method is scoped to verifiable domains. The honest open question, which the paper names, is the non-verifiable setting, exactly where the next work has to go.
How it works
The problem and why prior approaches failed. RL for LLM reasoning maximizes expected return, and the advantage A_t says how much better an action is than the baseline. In the common setup only the final token carries reward, so A = r(y_T) - b smears one terminal grade across every token. That sparsity rewards right-answer-wrong-reasoning, wastes samples, and makes long-range credit assignment hard. Dense rewards from a PRM would fix it, but PRMs need expensive step labels and, worse, a fixed PRM gets reward-hacked as the policy drifts off the data it was trained on (Gao et al. on overoptimization). Estimation-based dense rewards need about 10x the rollouts. So dense rewards stayed off the table for online RL.
The key idea. A reward model trained with the ordinary cross-entropy objective on outcome labels, with the reward parameterized as the log-ratio r_φ(y) = β log(π_φ(y)/π_ref(y)), yields a free per-token process reward at inference.
r_φ(y_t) = β · log( π_φ(y_t | y_<t) / π_ref(y_t | y_<t) )No step labels are needed, and because π_φ is a language model you initialize it from the SFT model rather than training a reward model from scratch. The reward of a step is just how much more the policy model likes that step than a frozen reference does.
Methodology. Each iteration runs the loop in Algorithm 1. Sample K responses per prompt, grade them with a rule-based outcome verifier, filter prompts by difficulty, read out the implicit token rewards, then build the advantage as the sum of a leave-one-out-baselined process return and a leave-one-out-baselined outcome return (Eq. 5). Update the policy with a PPO clip loss, and update the implicit PRM online by cross-entropy against the outcome labels on the fresh rollouts.
for each iteration:
sample K responses per prompt from the policy
r_o = outcome_verifier(responses) # exact match / passing tests
r_phi = beta * log(pi_phi / pi_ref) # implicit per-token reward
A = LOO(process returns of r_phi) + LOO(outcome r_o)
update policy with PPO clip loss on A
update pi_phi by cross-entropy on (responses, r_o) # the online stepThat last line is the one that matters most. Freeze it and you get a static reward the policy learns to game.

Load the Frozen reward hacks preset and inject the shortcut to watch the left panel happen live, then flip the PRM back to online to watch it snap to the right panel.
Results with effect sizes. Starting from Qwen2.5-Math-7B-Base, PRIME lifts average accuracy 15.1% over the SFT model and over 20% on AMC and AIME. Against outcome-only RLOO it reaches 6.9% higher final reward at 2.5x the sample efficiency, and beats it on downstream test accuracy with lower variance. Eurus-2-7B-PRIME surpasses Qwen2.5-Math-7B-Instruct on seven benchmarks using 10% of its data, and hits 26.7% pass@1 on AIME 2024, above GPT-4o and Llama-3.1-70B-Instruct. The SFT-initialized PRM beats a specially-trained EurusPRM, the online PRM's accuracy rises through training while a frozen PRM's falls, and the implicit PRM used as a reward beats value models. PRIME plugs into REINFORCE, RLOO, PPO, and GRPO and improves all four.
Limitations and open questions. The outcome verifier must be exact and unhackable, which scopes the method to verifiable domains like math and code. The online update adds about 24% wall-clock per step, offset by reaching the same reward in 40% of the steps for a net 2x. How the online PRM behaves under a noisy or learned outcome signal, and in non-verifiable domains, is left open.
My assessment
The authors got the central bet right, and the evidence is unusually clean for an RL paper. The implicit reward isn't their invention, it's Rafailov's and Yuan's, but the insight that you can run the reward-model update inside the online loop and that doing so is what kills reward hacking is the real contribution, and Figure 5 makes it undeniable. The offline PRM's accuracy sliding down through training while the online one climbs is the kind of plot that settles an argument. The SFT-initialization ablation is the other quietly important result, because it inverts the intuition that more reward-model training is better, the PRM that saw 500K extra examples lost to the one that just started from the policy and only ever saw the policy's own rollouts. That's a distribution-shift story told well.
Where I'd push back is the framing of "only outcome labels." The method leans entirely on an exact, unhackable verifier, so it's really "outcome labels plus a perfect oracle," and that oracle is exactly what you don't have in the domains where dense rewards would matter most, like open-ended reasoning or writing. The paper is honest that non-verifiable settings are future work, but the title undersells how much the verifier is doing. The other open edge is the coupling between beta and the update rate, the simulation here makes it obvious that a large reward weight with a slow update is the danger zone, and the paper doesn't map that boundary. None of that dents the core result. Getting dense process rewards for free, from a model you already have, kept honest by an online update, is a genuinely useful unlock, and it landed as the recipe behind a real family of open reasoning models.