Thinking Fast and Slow with Deep Learning and Tree Search
Split learning into a slow planner that searches and a fast net that copies it, and let each one make the other stronger every round until the pair beats the reigning champion.
Read at your level
Start where you're comfortable and climb as far as you like.
- For a 5-year-old
- For a high schooler
- For a college student
- For an industry pro
- For a PhD candidate
- For a peer researcher
Executive summary
A computer learning to play a board game has to do two hard things at once. It has to plan good moves at a single board, and it has to carry what it learns to every other board it might see. Older reinforcement learning made one neural net do both jobs, and that net had to stumble onto good moves on its own, which is slow and shaky. Expert Iteration splits the work. A slow expert, a tree search, reads many moves ahead and finds strong plays at one position. A fast apprentice, a neural net, copies those plays across the whole game. Then the apprentice's learned hunches steer the next search toward moves worth reading deeply, so the expert gets stronger too. Round after round the two pull each other up. On 9 by 9 Hex, trained from nothing, the result beat REINFORCE by a wide margin and went on to defeat MoHeX 1.0, the reigning computer Hex champion, without ever being told a single human strategy.
Try it
Load the ExIt (policy) preset and press play. Watch the orange apprentice line and the green expert line climb together and cross the dashed MoHeX line. Now load REINFORCE and play again, and watch the single line jitter and stall far below. Back on ExIt (policy), pause around iteration 10, then turn the Apprentice prior off and resume, and watch the climb slow because the search has lost the hunch that pointed it at the right moves.
The full loop with TPT targets and the tuned prior weight. Play it and watch the apprentice and expert climb past MoHeX together.
The apprentice prior pulls the search toward move 2, so the visits concentrate instead of spreading evenly.
Play, step an iteration, or flip a control to start the log.
Strength here is an Elo recurrence that follows the paper's framing. The expert is the apprentice plus a search gain, and each iteration the apprentice closes part of the gap up to the expert it just imitated. The run is deterministic (fixed seed) and stops at 60iterations. The real ExIt ran 9x9 Hex with 10,000 simulations per move over hundreds of thousands of positions; this compresses the loop so the compounding is watchable, not at the paper's scale.
For a 5-year-old
Imagine you're learning a tricky board game. You have two ways of thinking.
One way is quick. You look at the board and your gut says "that move feels good." That's your fast thinking. It's fast because you don't really stop to work it out, you just feel it.
The other way is slow. You sit and think hard. "If I go here, then they go there, then I go here." You play it out in your head, far ahead, branch by branch. That's slow thinking, and it finds better moves than your gut, but it takes a long time.
Here's the clever trick. After your slow thinking finds a great move, you teach your gut. "Next time a board looks like this, that's the good move." So your fast gut gets smarter. And the next time you sit and think slow, your smarter gut whispers "start by looking over here," so your slow thinking gets to the great moves faster.
Round and round they go, each one helping the other. Your gut copies your careful thinking, and your careful thinking leans on your sharper gut. After enough rounds, you're so good you can beat the best player around, even though nobody ever told you any tricks. You learned it all yourself, fast and slow.
For a high schooler
You've used a phone keyboard that guesses your next word. That guess is fast thinking. It doesn't reason, it just pattern-matches from everything it has seen.
Now picture two players inside one game-learning system. The first is the apprentice, a neural net. A neural net is a math machine that takes a board and spits out a guess for the best move, instantly, the way your keyboard guesses words. Fast, but only as good as what it has learned.
The second is the expert, a tree search. Instead of guessing, it actually plays the game forward in its head. It tries a move, imagines the reply, tries the next move, and builds out a tree of "what if" lines until it finds a strong play. Slow, but careful, so it beats the apprentice's gut guess.
The loop works like this. The expert searches a bunch of positions and finds strong moves. The apprentice trains to copy those moves, so its instant guesses get better. Then comes the part that makes this special. The apprentice's improved guesses get fed back into the expert's search as hints, telling it which branches are worth reading deeply. With good hints, the search skips junk lines and finds even stronger moves in the same time. The apprentice copies those, and around it goes.
Here's the takeaway in numbers. The old way without an expert barely climbed and bounced around wildly. The two-player loop climbed steadily and ended up strong enough to beat MoHeX, the best computer Hex player at the time, starting from zero knowledge.
For a college student
You should care about this because it's the same idea that powers AlphaGo Zero, developed at the same time and arrived at independently. The paper calls it Expert Iteration, and it's a clean way to think about why pairing search with learning works.
The setup is a Markov Decision Process. At each step an agent in state s picks an action a, and at the end of an episode it gets a reward R. A policy π(a|s) is a distribution over actions. We want a policy that wins.
The motivation is a split that older reinforcement learning blurred. Discovering a good move and generalising it to new positions are different jobs. A method like REINFORCE makes one neural net do both. The net must explore, stumble onto good actions, and also learn to repeat them everywhere, all through noisy gradient updates. That's slow and unstable.
Expert Iteration separates the jobs into two policies that improve each other.
π̂_0 = initial_policy() # the apprentice, an untrained net
π*_0 = build_expert(π̂_0) # the expert, a tree search using the net
for i = 1 .. N:
S_i = sample_self_play(π̂_{i-1}) # positions to study
D_i = {(s, target(π*_{i-1}(s))) | s ∈ S_i} # expert's moves at those positions
π̂_i = train_policy(D_i) # imitation learning: apprentice copies expert
π*_i = build_expert(π̂_i) # expert rebuilt with the sharper apprenticeTwo steps repeat. Imitation learning trains the apprentice π̂ to copy the expert's moves, like a student studying worked examples. Expert improvement rebuilds the expert using the better apprentice to guide search, like that student now reasoning with sharper intuition. Neither half is new on its own. Putting them in a loop where the expert keeps getting stronger is the contribution.
The expert is Monte Carlo Tree Search (MCTS). It picks which branch to explore with the UCT rule, which trades off exploiting moves that look good against exploring moves it hasn't tried much.
UCT(s, a) = r(s, a) / n(s, a) + c_b * sqrt( log n(s) / n(s, a) )Here n(s, a) is how many times the search took action a from s, n(s) is the total visits to s, and r(s, a) is the summed reward through that edge. The key move in this paper is bending UCT with the apprentice's policy π̂.
UCT_{P-NN}(s, a) = UCT(s, a) + w_a * π̂(a|s) / (n(s, a) + 1)That extra term pulls the search toward moves the apprentice likes, strongest when the search hasn't visited the move yet. They found w_a = 100 worked best, close to the average number of simulations per move at the root.

In the simulation, the small tree on the right shows this directly. Turn the apprentice prior on and the visits pile onto the move the apprentice favors. Turn it off and the search splits its visits more evenly, because now only its own raw reading guides it.
A worked path, end to end. The apprentice starts as a random net, around minus 120 Elo. The expert searches with that weak prior and still finds moves worth roughly plus 200 Elo over the apprentice, because reading ahead beats guessing. The apprentice trains to copy those moves and closes most of that gap. Now the expert searches with the stronger prior and finds moves stronger still. Repeat, and both curves climb past MoHeX. The limitation is that each iteration's apprentice can only reach as high as the expert it copied, so the whole system rises only as fast as the expert keeps improving.
For an industry pro
The problem this solves is sample efficiency and stability when you have a simulator but no strong off-the-shelf expert. Plain policy gradient methods like REINFORCE explore and generalise with the same network, so they're noisy and slow to converge, and they can regress. If you can run a search in your environment, ExIt lets the search do the hard exploration while the net does cheap generalisation, and the two compound.
Deployment cost has a clear shape. The expensive part is generating expert moves, because tree search is orders of magnitude slower than a network forward pass, so ExIt spends most of its wall-clock time building datasets. The good news is that step is embarrassingly parallel. Each plan is independent and summarises to well under 1KB, so you can spread dataset creation across many cheap machines with almost no bandwidth. Training the net is the cheap part. You need a simulator fast enough to run thousands of search simulations per decision, which rules out problems where each step is costly to evaluate.
The expected improvement over a policy-gradient baseline is large and not marginal. Against REINFORCE on Hex, ExIt learned stronger policies faster and showed no instability across runs. The final agent, trained from scratch, won 75.3% against MoHeX at equal search budget and still beat MoHeX even when MoHeX ran 10 times more search. The failure mode to plan around is that the curves had not flattened when they stopped, so the headline numbers are a floor, not a ceiling, and you should budget compute knowing more would have helped. The other operating constraint is the simulator requirement. No fast, accurate model of your environment, no ExIt.
For a PhD candidate
The contribution is framing search-plus-learning as a policy iteration where the expert is any planner and the apprentice is a function approximator that both generalises the expert's plans and accelerates its search. This generalises several known algorithms by choice of expert class. Take a Monte Carlo search expert and you recover a form of Policy Iteration. Strip the expert improvement step from online ExIt and you recover DAgger, since online ExIt aggregates all datasets and trains on the union, exactly the DAgger reduction.
The methodological choices reward scrutiny. The imitation target matters more than raw prediction accuracy suggests. They compare chosen-action targets (CAT), which minimise -log π(a*|s) for the search's best move, against tree-policy targets (TPT), which match the full visit distribution n(s,a)/n(s).
L_CAT = -log[ π(a*|s) ]
L_TPT = - Σ_a n(s,a)/n(s) * log[ π(a|s) ]CAT and TPT had near-identical top-1 errors, 47.0% versus 47.7%, yet TPT produced a network 50 plus or minus 13 Elo stronger. The reason is cost-sensitivity. When two moves are close in strength the search visits both, so TPT penalises confusing them less, which spends capacity on the decisions that actually matter. In the simulation, switch the target from TPT to CAT and the apprentice closes less of the gap per iteration. That extra Elo at fixed accuracy is the single most interesting empirical result in the paper.
The value network choice is also worth noting. They lack the 10^5-plus independent samples needed to fit V^{π*} from Monte Carlo returns without overfitting, so they instead approximate V^{π̂}, the apprentice's own value, which is cheap to sample. The tree policy then uses a weighted average of the network estimate and the rollout estimate, the Gelly and Silver scheme. Figure 3 shows value-and-policy ExIt cleanly beating policy-only ExIt once datasets are large enough.
Threats to validity worth probing. The evidence is one game, Hex, at one board size, 9 by 9, against one opponent, MoHeX 1.0. Hex is chosen partly because its win condition is mutually exclusive and move order is irrelevant, which makes simulation cheap and clean, so generalisation to messier games is assumed rather than shown. The training curves had not converged, so the comparison to MoHeX is at a snapshot, not at the limit. The follow-up questions the field then chased are visible here. Whether root Dirichlet noise, which AlphaGo Zero used and this paper deliberately did not, would help exploration, and whether warm-starting from a vanilla-MCTS expert is necessary or just a compute saver.
For a peer researcher
The delta against prior imitation-plus-RL work is that ExIt improves the expert throughout training rather than only at the start. Silver et al.'s AlphaGo pipeline did imitation learning from human games and then switched to REINFORCE. Kai-Wei Chang et al.'s LOLS used Monte Carlo estimates of Q* and trained the apprentice against a mixture of the latest apprentice and the original expert. Both treat the expert as a fixed asset that helps early and then gets left behind. ExIt's expert is a search seeded by the current apprentice, so it strengthens every iteration, which is what lets the system pass the original expert's level and keep going. That single change is the difference between a warm start and tabula rasa mastery.
The choices read as deliberate tradeoffs. TPT over CAT trades a touch of top-1 accuracy for cost-sensitivity, and the ablation says that's worth about 50 Elo, because the search's visit counts encode which mistakes are cheap. Approximating V^{π̂} instead of V^{π*} trades the theoretically right value target for one with cheap Monte Carlo samples, a concession to a compute budget orders of magnitude smaller than AlphaGo Zero's. Skipping the verification step that AGZ used, where a new expert must beat the old one before replacing it, trades a safety check for speed, and they report not needing it on Hex.
What would change my mind on the central claim. If a single-network policy-gradient method matched ExIt's sample efficiency and final strength at equal compute on the same task, the case for separating planning from generalisation would weaken. It didn't happen here, and AlphaGo Zero's independent success on Go is strong corroboration. The honest soft spots are the single-game evidence and the unconverged curves. The open question this paper leaves wide, and the one the appendix's AGZ comparison circles, is exactly which of the implementation differences, value targets, noise, network size, verification, actually carry the weight.
How it works
The problem and why prior approaches failed. Sequential decision making needs two things that pull against each other. You have to find strong actions at a given state, which is planning, and you have to reuse what you learn at every other state, which is generalisation. Standard deep reinforcement learning, like REINFORCE or DQN, leans on one neural network to do both. The network picks actions with no lookahead, so it has to discover good moves by trial and error through noisy gradient steps, and it has to generalise them at the same time. That dual burden makes training slow, high in variance, and prone to local minima.
The key idea. Decompose the problem. Use a slow tree search as an expert to plan strong moves at single positions, and a fast neural network as an apprentice to generalise those moves across the state space. Then close the loop by feeding the apprentice's policy back into the search to guide it, so the expert improves too. Planning and generalisation each get their own tool, and the tools sharpen each other.
Methodology. The test bed is Hex on a 9 by 9 board, a connection game where one player joins top to bottom and the other joins left to right. Hex is a clean reinforcement learning test bed because exactly one player can have a winning path, so games resolve cleanly and move order doesn't matter.
The expert is Monte Carlo Tree Search, run at 10,000 simulations per move, biased by the apprentice through the modified UCT term shown earlier. The apprentice is a convolutional network trained on positions sampled one per game to keep the dataset uncorrelated, following the DAgger procedure of expanding the dataset with the latest apprentice's self-play. Batch ExIt redoes imitation learning from scratch each iteration on a fresh 243,000-move dataset. Online ExIt aggregates datasets, which makes it close to DAgger plus expert improvement, and it learns faster because improvements generalise sooner.
The imitation target is the tree-policy target, matching the search's visit distribution rather than just its top move, which buys cost-sensitivity worth about 50 Elo at equal prediction accuracy. When a value network is added, it's trained against the binary game result with a KL loss and shares a network body with the policy head.
L_V = -z log[ V(s) ] - (1 - z) log[ 1 - V(s) ]Results with effect sizes. Against REINFORCE warm-started from the same network, ExIt learned stronger policies faster and showed no instability across 5 runs, where REINFORCE's curve jittered and barely rose. Online ExIt beat batch ExIt, and retaining a larger aggregated dataset helped a little more. Adding a value network beat policy-only ExIt cleanly once datasets passed roughly 550,000 positions. The final agent won 75.3% of games against MoHeX 1.0 at 10,000 iterations each, 59.3% against a 100,000-iteration MoHeX, and 55.6% against a 4-second-per-move MoHeX running over six times slower than the searcher, all while trained tabula rasa with no game-specific knowledge beyond the rules.
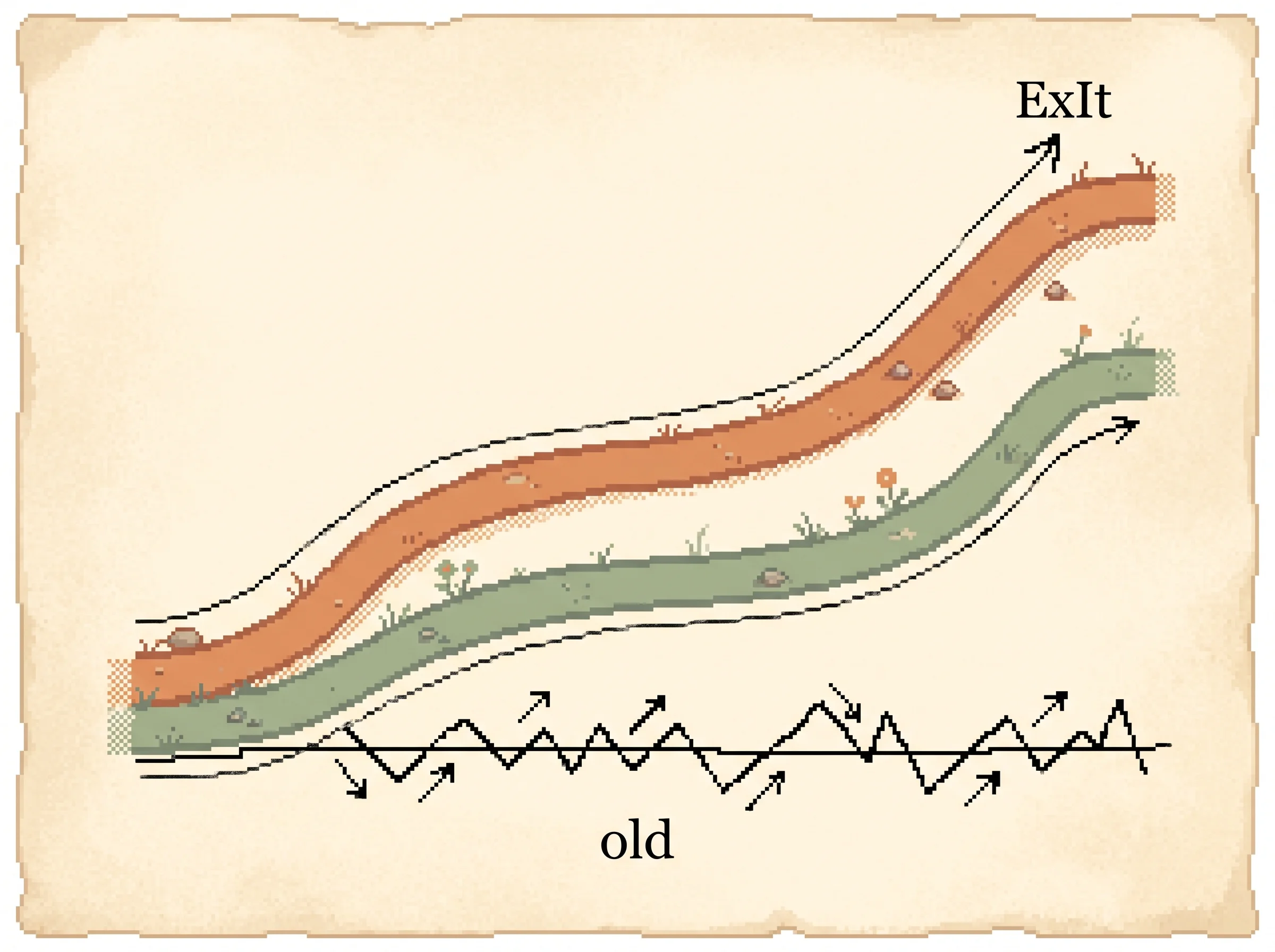
In the simulation, the orange and green lines are the apprentice and the expert, and the dashed line is MoHeX. The flat noisy path in the paper's REINFORCE comparison is what you get when you load the REINFORCE preset and the single line refuses to climb.
Limitations and open questions. ExIt needs a fast, accurate simulator to run thousands of search simulations per move, so it doesn't apply where each step is costly to evaluate. The evidence is one game at one board size against one opponent, and the training curves had not converged when the comparison was taken, so the numbers are a floor. The value target is the apprentice's value, not the expert's, a concession to compute. And they leave open whether tricks they skipped, like root noise for exploration or an expert-verification step, would help.
My assessment
The authors got the central call right, and history confirmed it twice over. The same loop, discovered independently as AlphaGo Zero, mastered Go from scratch, so the idea that separating planning from generalisation and letting them bootstrap is more than a Hex trick is about as well supported as a single-paper claim can get. The framing through dual-process theory is more than decoration. It names exactly why the loop works. A fast system that copies and a slow system that searches are genuinely different computations, and forcing one network to be both was the bottleneck the field hadn't named clearly.
The sharpest piece of work is the TPT versus CAT ablation. Two targets with the same top-1 accuracy, one 50 Elo stronger, because one of them respects that confusing two equally good moves is cheap while confusing a good move with a blunder is not. That's a real insight about imitation targets, not a tuning footnote, and it generalises past games to any setting where you imitate a planner. Where the paper is appropriately humble is the evidence base. One game, one opponent, unconverged curves. The honest read is that ExIt clearly beats REINFORCE on Hex and clearly beat the champion, and the rest is extrapolation that AlphaGo Zero happened to vindicate. The weakest brick is the value network, approximating the apprentice's value instead of the expert's purely because they couldn't afford the samples, which they're candid about. None of that dents the core. Thinking fast and thinking slow, taking turns, really did learn to play better than anything hand-built before it.