Language Models Are Unsupervised Multitask Learners
A model trained only to predict the next word, on text diverse enough that tasks show up inside it, learns to do those tasks with no extra training just by being asked in plain language, and it does this better the bigger it gets.
Read at your level
Start where you're comfortable and climb as far as you like.
- For a 5-year-old
- For a high schooler
- For a college student
- For an industry pro
- For a PhD candidate
- For a peer researcher
Executive summary
Before this paper, you taught a model a task by collecting thousands of labeled examples of that exact task and training on them. Want a question answerer? Gather question-answer pairs. Want a summarizer? Gather articles and their summaries. Each task needed its own dataset and its own training run. The authors asked a different question. What if you train one model to do nothing but predict the next word, on a huge and varied pile of web pages, and then just ask it to do a task in plain language? It turns out the model can do the task with no extra training at all. Frame a translation as "english = french" and it translates. Add "TL;DR:" after an article and it summarizes. The trick works because the web already contains questions with answers, articles with summaries, and sentences with their translations, so a model good enough at predicting the next word has to learn those skills to predict well. The biggest model, GPT-2 at 1.5 billion parameters, set new records on 7 of 8 language tests this way, and the skill climbed steadily as the model grew. The catch is that "good enough at predicting" still means weak at most tasks. GPT-2 answered only 4 percent of open-domain trivia correctly. The promise was the trend, not the score.
Try it
Load the Zero-shot Q&A preset and press play. Watch "Charles Darwin" fall out of plain next-word prediction with no fine-tuning. Then load Summary with TL;DR:, press play, and the moment it starts the summary, click Task hint to remove the hint mid-run. The output drifts off the summary and back toward the article, the same collapse the paper measured when it took the hint away. Last, load Tiny model fails and step it. The small model can't lean hard on the right answer, so a wrong word often wins. Bump the size up to 1542M and the answer comes back.
The full 1542M model, hint on. Play it and watch 'Charles Darwin' fall out of next-token prediction with no fine-tuning.
Who wrote the book the origin of species? A: [generate]Target answer Charles Darwin
Natural Questions, zero-shot. GPT-2 answers 4.1% correctly, 5.3x the smallest model. Its top answers are well calibrated.
| token | base | boost | prob |
|---|---|---|---|
| Charles★ | 0.72 | 3.40 | 98% |
| the | 0.96 | 0.00 | 1% |
| author | 0.55 | 0.00 | 1% |
| of | 0.32 | 0.00 | cut |
| and | 0.39 | 0.00 | cut |
Step, change the prompt, or toggle the hint to start the log.
The loop is real, the same predict-then-sample step the paper runs. Scores come from small hand-built per-task tables instead of a trained network, so the gold answer winning is legible rather than learned. Model size sets how hard the model leans toward the correct continuation, which is the log-linear lift of Figure 1, and the hint switch is the paper's TL;DR: ablation. Each preset starts from a fixed seed so every run is reproducible; use Reshuffle to try a different sample. This runs 4 tasks over a handful of tokens; GPT-2 runs over a 50,257-token vocabulary and 40 GB of text.
For a 5-year-old
Imagine a kid who reads every book and every webpage in the whole world. Not to study for a test. Just for fun, the same way you might read a comic. The kid plays one tiny game over and over. Someone reads part of a sentence out loud and stops, and the kid guesses the very next word. "The dog wagged its..." and the kid says "tail." That's the only game.
Here's the surprise. To get really good at guessing the next word, the kid has to learn a lot of other stuff by accident. To finish "The capital of France is..." the kid has to know it's "Paris." To finish "Q: Who wrote about evolution? A:..." the kid has to know it's "Darwin." Nobody sat the kid down and taught a Paris lesson or a Darwin lesson. The kid picked it all up just from reading and guessing.
So now you can ask the kid almost anything, and the kid answers by guessing the next word like always. You don't teach a new game. You just ask.
The kid is not really a kid, and the reading is not really reading. The guessing is math with numbers, where every possible next word gets a score and the model picks one. But the feeling is the same. Read enough of everything, and you learn to do lots of things without anyone teaching you each one.
For a high schooler
Your phone keyboard guesses your next word. You type "see you" and it offers "later." It learned that from reading a lot of text and noticing which words tend to follow which. This paper takes that same idea and pushes it as hard as it goes.
Here's the one new word for this section. A language model is a program that, given some words, gives a probability to every possible next word. "The sky is..." makes "blue" likely and "purple" less likely and "refrigerator" almost zero. Train it by showing it tons of real text and nudging it whenever its guess is off, until its guesses match how people actually write.
Now the clever part. The web is full of patterns where the answer sits right next to the question. Trivia pages have "Q: ... A: ...". Translation forums have an English line next to its French line. News articles get summed up by their own headlines. So to predict the next word well across all of that, the model has no choice but to pick up question answering, translation, and summarizing along the way. They're baked into the text.
Here's a worked example. Feed the model "Who wrote the book the origin of species? A:" and ask for the next word. The model has read enough pages that mention Darwin near "origin of species" that "Charles" gets a high score and "the" or "a" get low scores. It picks "Charles," then "Darwin." It never trained on a trivia dataset. It just learned that "Charles Darwin" is the likely continuation.
Train the model on more text with more parameters and it gets better at every one of these tasks at once, without anyone teaching the tasks one by one.
For a college student
You should care because this is the paper that made "just prompt it" a real strategy, and the line straight from here runs to every chatbot you use now. The setup before GPT-2 was supervised and narrow. To do task T you estimated p(output | input) from a dataset built for T. Each task was its own model.
The core move is to notice that the supervised objective is a slice of the unsupervised one. A general system should model p(output | input, task), conditioning on the task as well as the input. And language lets you write the task right into the input as plain text. A translation example becomes the token sequence (translate to french, english text, french text). A reading-comprehension example becomes (answer the question, document, question, answer). Once the task lives inside the token stream, predicting the next token over a diverse enough corpus already optimizes the task. No separate objective.
So the whole model is one autoregressive language model. It factors the probability of a sequence into a product of next-token probabilities.
p(x) = product over n of p(s_n | s_1, ..., s_{n-1})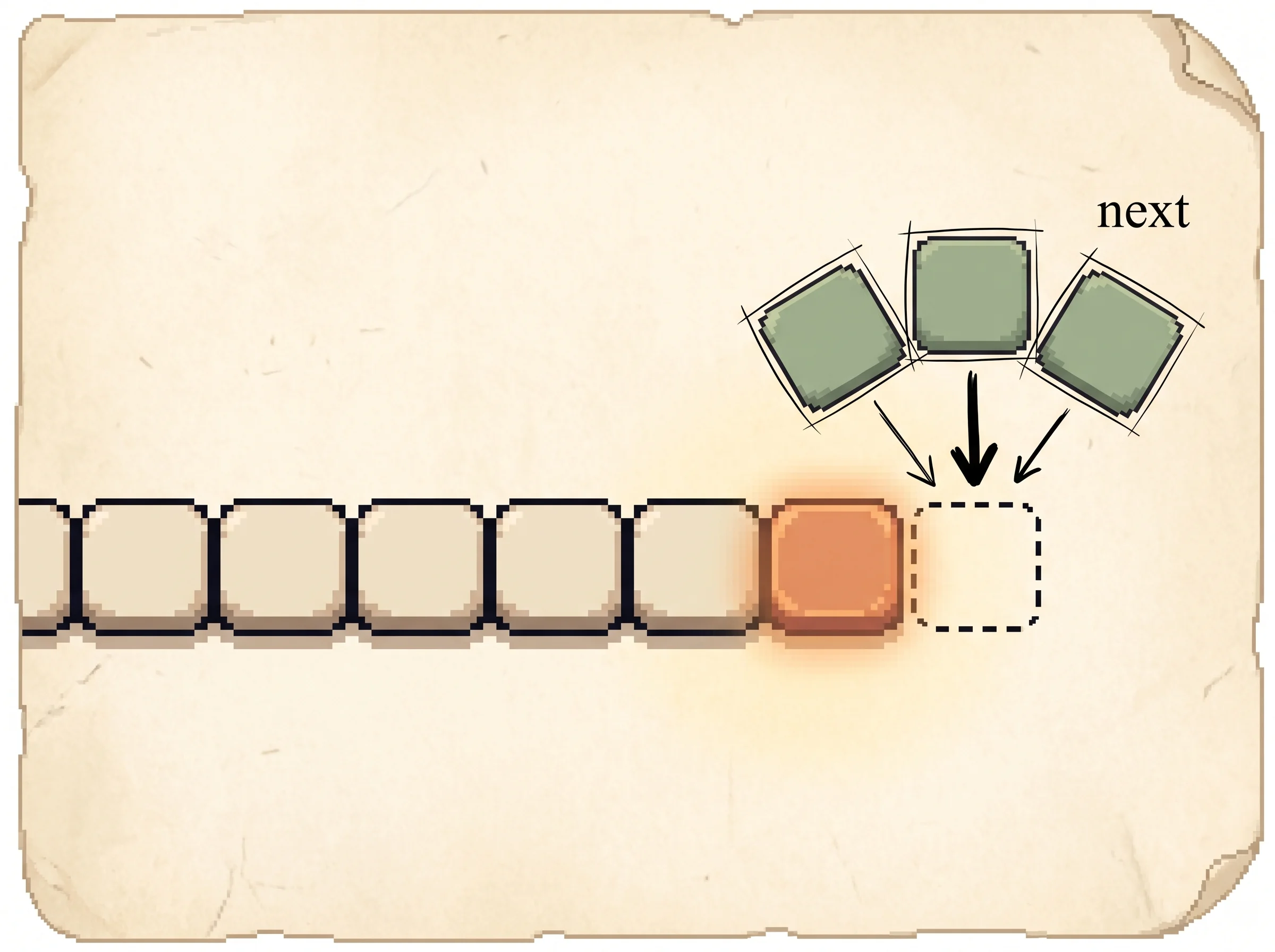
To generate, you compute the distribution over the next token, sample one, append it, and repeat. The simulation above is exactly this loop. At each step it scores the candidate next tokens, divides by a temperature, keeps the top k, softmaxes into a probability distribution, and samples.
Two design choices made the corpus work. First, the data. Instead of scraping all of Common Crawl, which is full of junk, the authors built WebText from the outbound links of Reddit posts with at least 3 karma, a cheap human filter for "someone found this worth sharing." That's about 8 million documents and 40 GB of text. Second, the tokenizer. They use byte-level Byte Pair Encoding, which starts from raw bytes and merges frequent pairs into tokens. Byte-level means it can encode any string at all, so the model is never stuck on an out-of-vocabulary word, and BPE keeps the vocabulary at a manageable 50,257 tokens.
The single most important finding is the scaling curve. They trained four sizes, from 117M to 1542M parameters, and across nearly every task the zero-shot performance rose log-linearly with model size.
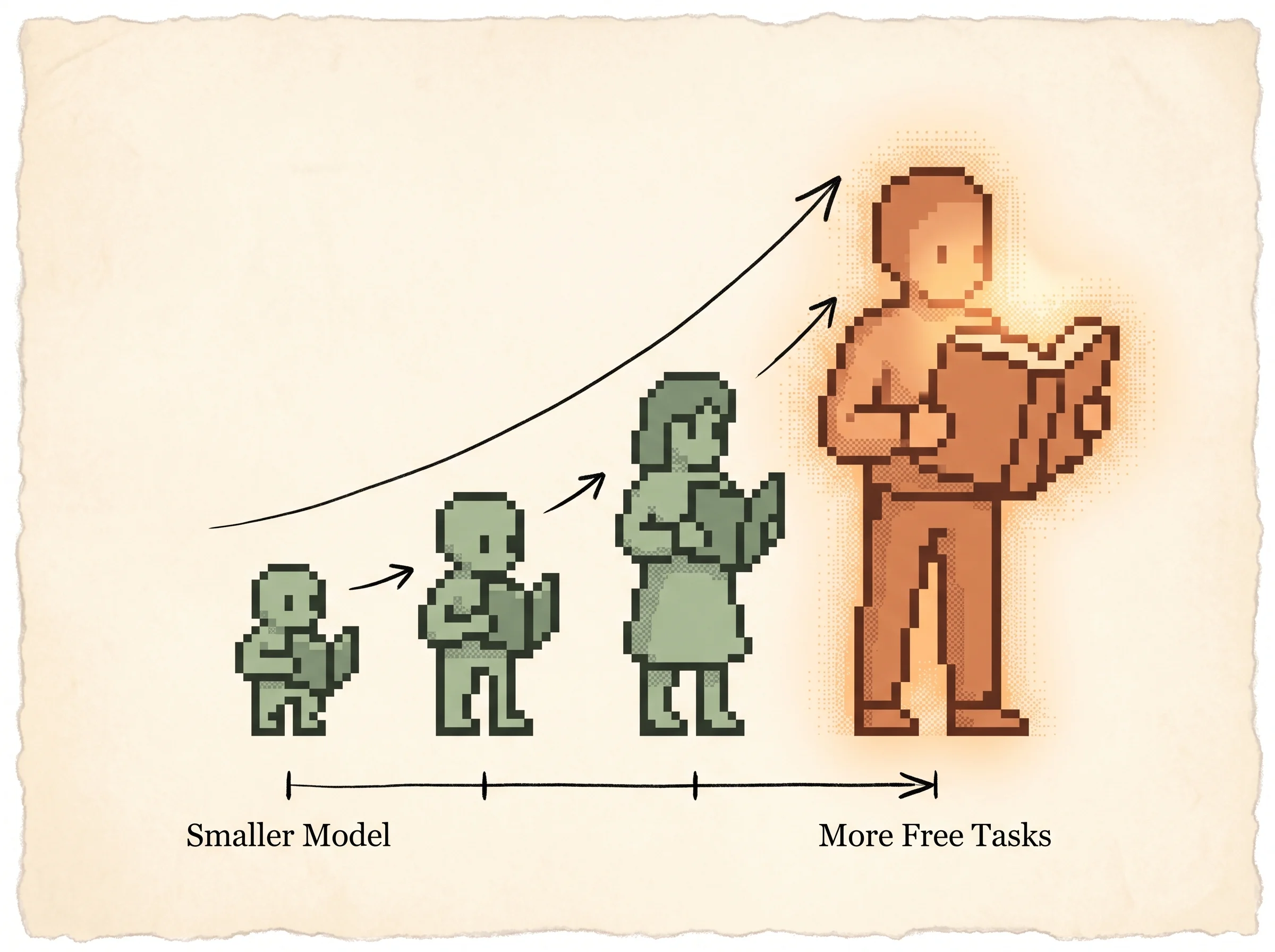
That straight-line climb is the real result. It says the model hadn't hit a ceiling, so more scale should keep helping. Load the Tiny model fails preset in the simulation, then walk the size up from 117M to 1542M and watch the probability on the correct answer rise the same way.
The limitation is blunt. Zero-shot numbers are still low in absolute terms. GPT-2 answered 4.1 percent of Natural Questions correctly, far below systems built for the task. The contribution is the existence of the trend, not a deployable QA system.
For an industry pro
The problem this solves for you is the cost of a labeled dataset per task. The old pipeline was collect, label, train, repeat, for every capability you wanted. This paper shows one pretrained next-token model can attempt many tasks with zero task-specific data, steered by a text prompt. That's the seed of the prompt-engineering workflow you use today.
What it costs. Training is one large language-model run over a big corpus, which is real money and engineering but amortizes across every downstream task instead of being paid per task. Inference is autoregressive, so generation is sequential and you pay per token. And the framing here is strictly zero-shot, no fine-tuning, so you take whatever the base model gives you.
The expected improvement, measured honestly, is mixed. On reading comprehension GPT-2 reached 55 F1 on CoQA, competitive with 3 of 4 supervised baselines that each trained on 127,000+ examples, which is a strong result. On most other tasks it cleared trivial baselines but stayed far below supervised systems. Summarization barely beat picking 3 random sentences. Translation got 5 BLEU, worse than a word-by-word dictionary.
The failure mode to plan around is overconfidence in the zero-shot number. As a practical tool in 2019 this model was not good enough for production QA or translation. What it told you was where to invest. The log-linear scaling said the path forward was more parameters and more data, and the next models proved it. Read this as a direction signal, not a product.
For a PhD candidate
The contribution is the demonstration that a single unsupervised language model, with no parameter or architecture changes, performs downstream NLP tasks zero-shot, and that this ability scales log-linearly with capacity. It connects two lines of work, the transfer-via-pretraining line that still fine-tuned for each task, and the line showing language models can do specific tasks, by removing the fine-tuning step entirely.
The framing rests on the observation that p(output | input, task) collapses into p(output | input) when the task is specified in natural language inside the same token stream. The authors lean on McCann et al.'s decaNLP, which showed many tasks can be cast as question answering over text, and push it to its limit. If the global optimum of the unsupervised objective is reached, the supervised objective comes along for free as a subset, so the open question becomes purely practical, whether you can optimize the unsupervised objective well enough in practice. Their answer is that capacity is the lever.
The methodological choices reward scrutiny. WebText's Reddit-karma filter is a pragmatic proxy for document quality that sidesteps the unintelligible bulk of Common Crawl, and they deliberately remove Wikipedia to avoid contaminating the many evaluation sets sourced from it. Byte-level BPE buys universal string coverage at the cost of slightly longer sequences, and they add a rule preventing merges across character categories to stop the vocabulary wasting slots on dog. versus dog!. The de-tokenizers used at evaluation, which strip tokenization artifacts before scoring, are a form of light domain adaptation worth flagging, worth 2.5 to 5 perplexity.
Threats to validity. The headline scaling holds across many tasks but absolute zero-shot scores are weak, so the claim is about the trend, not capability. The train-test overlap analysis is the honest part. They build Bloom filters of 8-grams and find WebText shares 1 to 6 percent overlap with common benchmark test sets, comparable to those sets' overlap with their own training splits, and estimate the inflation at roughly 0.5 to 1 F1 on CoQA. Notably the model still underfits WebText, train and test perplexity improve together with size, which is the clearest sign the curve had not flattened.
For a peer researcher
The delta against the pretrain-then-fine-tune paradigm of the day, GPT-1 and BERT, is dropping the fine-tune step. Same Transformer backbone, but the claim is that a sufficiently large LM trained on sufficiently diverse data does the task zero-shot from a natural-language prompt, and that capacity, not task-specific adaptation, is the binding constraint. Against decaNLP, which unified tasks under a supervised multitask QA objective, the move is to get the multitasking for free from the unsupervised objective because the task demonstrations occur naturally in the corpus.
The choices read as deliberate. The Reddit-karma corpus filter trades a principled quality model for a cheap human signal that works, the kind of janky-but-effective move that scaled. Byte-level BPE trades sequence length for never hitting an OOV token, which matters once you want to evaluate on any dataset regardless of preprocessing. Keeping the architecture identical across the four sizes is what makes the log-linear scaling claim clean, since size is the only variable moving.
What would change my mind on the central claim. If zero-shot performance had plateaued before the largest model, the "capacity is the lever" thesis would weaken, but train and test perplexity kept falling together and the model underfit WebText, so the curve pointed up. The honest soft spot is that absolute task performance is low, so this is a proof of direction. The open questions the paper names, whether fine-tuning on top closes the gap and where the ceiling sits, are exactly what the few-shot scaling work that followed went after.
How it works
The problem and why prior approaches failed. The dominant recipe was supervised learning on a task-specific dataset. You wanted a system that does task T, so you collected a dataset of inputs and correct outputs for T and trained on it. This produces narrow experts that are brittle to any shift in input distribution or task framing, and it scales badly, since every new capability needs its own labeled dataset and training run. Multitask learning, training one model on several tasks at once, helps, but the most ambitious efforts at the time trained on only 10 to 17 task-and-objective pairs, nowhere near enough to generalize the way the authors wanted.
The key idea. Train one model on a single objective, next-token prediction, over a corpus diverse enough that task demonstrations occur naturally inside it. Because the web contains questions next to answers and articles next to summaries, a model that predicts the next token well must implicitly learn those tasks. Then perform a task zero-shot by writing it into the prompt in plain language, with no parameter or architecture change.
# Generate one token at a time. No task-specific code anywhere.
context = tokenize(prompt) # e.g. "...origin of species? A:"
for step in range(max_tokens):
logits = model(context) # score every token in the vocabulary
logits = logits / temperature # sharpen or flatten the distribution
logits = keep_top_k(logits, k) # truncate to the k most likely
probs = softmax(logits)
next_token = sample(probs) # draw one token
context = context + [next_token]Methodology. The model is a Transformer decoder, the same family as GPT-1, with layer normalization moved to the input of each sub-block and an extra normalization after the final self-attention block. Residual weights at initialization are scaled by 1 over the square root of the number of residual layers. The context window is 1024 tokens and the vocabulary is 50,257 byte-level BPE tokens. They trained four sizes.
| Parameters | Layers | d_model |
|---|---|---|
| 117M | 12 | 768 |
| 345M | 24 | 1024 |
| 762M | 36 | 1280 |
| 1542M | 48 | 1600 |
The data is WebText, the text behind 45 million outbound Reddit links with at least 3 karma, cleaned and de-duplicated to about 8 million documents and 40 GB, with Wikipedia removed to avoid overlap with evaluation sets. Tasks are framed as prompts. Translation conditions on example pairs in the format english = french. Summarization appends TL;DR: after the article. Question answering appends the document and question and a final A:. The prompt is the entire interface.

That the prompt carries the task is testable, and the authors test it. Removing the TL;DR: hint drops summarization performance by 6.4 ROUGE points, which says the model really is keying off the natural-language instruction. In the simulation, load the summary preset and toggle the hint off mid-run to watch the same drop, the output drifting from a summary back toward the article's own words.
Results with effect sizes. On language modeling, GPT-2 set state of the art on 7 of 8 datasets zero-shot, including a jump on LAMBADA from 99.8 to 8.6 perplexity and on the Children's Book Test to 93.3 percent on common nouns. On CoQA reading comprehension it reached 55 F1, matching or beating 3 of 4 supervised baselines that used 127,000+ training examples. On the Winograd Schema Challenge it improved the state of the art by 7 percent. Question answering was weak in absolute terms at 4.1 percent on Natural Questions, but that is 5.3 times the smallest model, and the probabilities GPT-2 assigned to its answers were well calibrated, 63.1 percent accuracy on the 1 percent it was most confident about. Summarization barely beat random-3 sentence selection, and translation reached 5 BLEU, worse than a bilingual dictionary lookup.
Limitations and open questions. Absolute zero-shot performance is low on most tasks, so this is a research result, not a usable system. The model still underfits WebText, train and test perplexity falling together with size, which says more capacity should keep helping but also that they had not reached the model's limit. The train-test overlap analysis shows a small consistent inflation, roughly 0.5 to 1 F1 on CoQA, that they flag rather than hide. The open question they name is the fine-tuning ceiling, whether adding supervised fine-tuning on top closes the gap to specialized systems.
My assessment
The authors got the central bet exactly right, and the field's whole shape since has confirmed it. The bet was that you don't need clever task-specific machinery, you need scale and diversity, because the tasks are already sitting in the data. The log-linear scaling curve was the load-bearing result, and it was honest in a way that's easy to miss, the model underfit its own training data, which is the clearest possible signal that the curve points up and the ceiling is higher. Reading this in 2019 you should have concluded that bigger was the move, and the few-shot scaling work that followed did exactly that and proved it.
Where the paper undersells itself is the same place every foundational paper does. The framing is cautious and task-by-task, and the absolute numbers are weak enough that a skeptic could dismiss the whole thing as a curiosity, a model that gets 4 percent on trivia. The authors couldn't lean harder than the evidence allowed, and the evidence was a set of low scores connected by a promising line. The genuinely clever, slightly janky decisions are worth admiring, the Reddit-karma filter as a stand-in for a quality model, byte-level BPE so no string is ever out of vocabulary, dropping Wikipedia to keep the evaluations clean. None of those are deep theory. They are practical calls that made the experiment work. The weakest claim is that zero-shot is the right setting at all, and the field quietly agreed, moving to few-shot prompting and then to instruction tuning, both of which keep this paper's core insight and just feed the model a better prompt. Attention scaled, and so did next-token prediction.