Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Show a big language model a few worked examples that spell out their reasoning step by step, and it starts writing its own steps before answering, which lets it solve problems it gets wrong when asked to answer in one shot.

Read at your level
Start where you're comfortable and climb as far as you like.
- For a 5-year-old
- For a high schooler
- For a college student
- For an industry pro
- For a PhD candidate
- For a peer researcher
Executive summary
A language model that answers a math word problem in one shot often gets it wrong, because the problem needs several steps and the model has to nail them all at once. This paper changes the prompt, not the model. You hand the model a few examples where the answer is worked out step by step, and the model copies the habit. On a new problem it writes its own steps first, then the answer. That one change pushed a 540B model from 18 percent to 57 percent on the GSM8K grade-school math benchmark, beating a finetuned GPT-3 that used a separate verifier. The same trick helped on commonsense and symbolic problems too. The catch is that the skill only shows up in big models. Below about 100B parameters the model writes steps that read fine but contain a wrong number, and that one wrong number ruins the answer.
Try it
Load the Standard prompting fails preset and step it. The model blurts one number for the apples problem and gets it wrong. Switch the prompt mode to Chain of thought and step again. Now it writes 23 minus 20 is 3, then 3 plus 6 is 9, the right answer. Then load Too small to reason, step through the three-step problem, and watch a middle step come out wrong and drag the answer down with it. Click that broken step to fix it by hand, or drag the model scale up past 100B and watch the slip disappear.
Standard prompting on the apples problem. The model writes one answer and gets it wrong, with no steps to lean on.
The cafeteria had 23 apples. If they used 20 to make lunch and bought 6 more, how many apples do they have?
No reasoning steps. The model commits to one answer.
The baseline. The model jumps straight to one answer with no steps, so a multi-step problem usually comes out wrong.
This mode writes no natural-language reasoning before the answer, so a bigger model buys it nothing. It scores like the baseline.
Flip a mode, drag scale, or break a step to start the log.
The reasoning here is hand-set so each step has a known right value and a broken step poisons the ones after it, the way the paper's error analysis describes. A real model writes the words itself, and the emergence curve is sharper than this smooth stand-in. Each preset uses a fixed seed, so the same preset always produces the same run. This runs 3 short problems, where the paper tests thousands across five math, commonsense, and symbolic benchmarks.
For a 5-year-old
Imagine a kid named Sam doing a math problem in class. The teacher asks, "You had 23 apples, you used 20 for lunch, then you bought 6 more. How many now?"
One Sam just shouts a number. "27!" That's wrong. He grabbed numbers from the question and smushed them together without thinking.
The other Sam goes slow. He says it out loud one piece at a time. "23 apples, take away 20, that leaves 3." Then, "3 apples, add 6 more, that's 9." Nine. Right answer. He didn't think harder than the first Sam. He just said the little steps out loud instead of jumping to the end.
That's the whole trick. If you show a computer that talks, like the one behind a chatbot, a few examples of someone saying the little steps out loud, the computer starts doing it too. And when it says the steps out loud, it gets way more answers right.
But here's the funny part. A small computer brain tries to say the steps, and it says them in a nice voice, but it gets one of the steps wrong. Like it says "3 plus 6 is 8." And then the rest falls apart, the way one broken link breaks a whole chain. Only a really big computer brain says every step right.
For a high schooler
You've used a chatbot. You type a question, it types an answer. Behind it is a language model, a program that predicts the next word over and over until it has written a full reply. For an easy question it does fine. For a problem that needs several steps, like a math word problem, it often blows it. It writes one answer and the answer is wrong.
Here's the one idea for this section. The way you talk to the model is called the prompt. With few-shot prompting you put a few example questions and their answers right in the prompt, and the model copies the pattern for your real question. The normal version shows examples that jump straight to the answer. So the model jumps straight to an answer too, and on a hard problem it misses.
Chain-of-thought prompting changes the examples. Instead of showing question and answer, you show question, then the reasoning written out, then the answer. The model copies that. On your real question it writes out its own reasoning before it commits to a number.
Here's a worked example. "The cafeteria had 23 apples, used 20 for lunch, bought 6 more, how many now?" A model that jumps to the answer might write 27, because 23 and 6 are right there and adding feels natural. A model writing the chain goes "23 minus 20 is 3" then "3 plus 6 is 9." It gets 9 because it did the subtraction first, in its own words, before adding.
Writing the steps out gives the model room to do one piece at a time instead of holding the whole problem in its head at once.
For a college student
You should care about this because it's a near-free upgrade. You don't retrain anything, you don't add a single parameter, you don't collect a labeled dataset. You write a better prompt, and a large model jumps on benchmarks it used to fail. This paper is the one that named the technique and showed how far it reaches.
The motivation comes from two older ideas that each had a wall. People had trained models to produce natural-language reasoning steps, but that meant building a big set of high-quality worked solutions, which is expensive. Separately, few-shot prompting let a model pick up a task from a handful of examples in the prompt, with no training at all, but plain few-shot prompting did poorly on tasks that need real reasoning. Chain of thought takes the cheap half of each. You keep the no-training prompting, and you put worked reasoning into the few examples you show.
Concretely, each exemplar in the prompt is a triple of input, chain of thought, and output.
Q: Roger has 5 tennis balls. He buys 2 more cans of tennis balls.
Each can has 3 tennis balls. How many tennis balls does he have now?
A: Roger started with 5 balls. 2 cans of 3 tennis balls each is 6 tennis
balls. 5 + 6 = 11. The answer is 11.You give the model a few of these (the paper uses eight for the math tasks), then your real question with an empty answer slot. The model continues the pattern, writing a chain of thought for your question and then the answer.
Why does writing the steps help? A problem like "23 apples, use 20, buy 6" is two steps deep. A model forced to emit the answer in its next token has to compute both steps internally in one pass. Writing "23 minus 20 is 3" puts the intermediate result into the text, so the second step now reads off a number that's already there instead of recomputing it. Each step becomes a short, local prediction, which the model is good at, instead of one long leap, which it isn't.
The honest limitation shows up the moment you try a small model. Below roughly 100B parameters the model writes a fluent chain that contains a wrong step, and a wrong step early ruins everything after it.
In the simulation above, load Too small to reason and step through. The chain reads like real reasoning, but one value is off, and because the next step uses that value, the answer comes out wrong. Drag the scale slider up and the slip vanishes. That sharp turn-on with scale is the paper's headline finding, not a side note.
For an industry pro
The problem this solves for you is multi-step reasoning failures on a model you can't retrain. If you're calling a large model through an API and it flubs problems that need a few steps of arithmetic or logic, you don't need a new model or a finetuning run. You change the prompt to include a few worked examples, and the model starts reasoning on your inputs.
Deployment cost is close to zero on the engineering side. No training, no data pipeline, no infra change. You write maybe eight exemplars by hand. The runtime cost is real though. The model now writes a paragraph of reasoning before the answer, so every call burns more output tokens and takes longer. On a multi-step task that's worth it; on a one-step task it isn't, and the paper shows the gain shrinks to nothing or goes slightly negative on the easiest single-step problems.
The expected improvement is large where it lands. On the hardest math benchmark in the paper, GSM8K, chain of thought roughly tripled the solve rate of the biggest model. On the easiest single-step set, it did nothing or hurt a little. So the operating envelope is clear. Use it for genuinely multi-step problems on a large model, skip it for short lookups, and don't reach for it on a small model at all.
The failure mode to plan around is the scale floor. Chain of thought is an ability that only appears above roughly 100B parameters. Run it on a small model and you get worse results than plain prompting, because the model writes confident reasoning with a broken step in it. If you're constrained to a small model, this technique is not your lever.
For a PhD candidate
The contribution is showing that multi-step reasoning is elicitable from an off-the-shelf large model purely through the prompt, with no gradient updates, and that this ability is emergent with scale. Prior rationale work, from Ling et al. through Cobbe et al., trained or finetuned models to produce intermediate steps, paying the annotation and training cost. Few-shot prompting from Brown et al. avoided training but failed on reasoning tasks and didn't improve much with scale. This paper combines them by putting rationales into the few-shot exemplars, and the combination clears both walls at once.
The methodological choices are worth scrutiny, and the paper does the work itself through three ablations on the same model and tasks. If the benefit were just emitting the final equation, then prompting for the equation alone should match it; it doesn't on GSM8K, because translating the words into an equation is the hard part. If the benefit were just spending more serial compute, then emitting a row of dots equal to the equation length should match it; it doesn't, scoring like the baseline. If the benefit were just surfacing knowledge from pretraining, then putting the chain after the answer should match it; it doesn't, because the answer is already committed. Together these isolate the cause to sequential natural-language reasoning produced before the answer.
In the simulation, switch among the Equation only, Variable compute (dots), and Reasoning after answer modes at 540B. None of them solves the problem, which is the point of the ablation made live: only the real chain reaches the answer.
Threats to validity worth probing. The error analysis that explains the scale story is a manual read of 50 chains, which is suggestive rather than systematic. The emergence claim rests on a handful of model families and sizes, so the exact threshold is soft. And the paper is careful to say chain of thought mimics reasoning without settling whether the network is "reasoning," which leaves the mechanism open. The obvious follow-ups, most of which the field then chased, are sampling many chains and voting, getting reasoning out of smaller models, and pushing past hand-written exemplars toward zero-shot triggers.
For a peer researcher
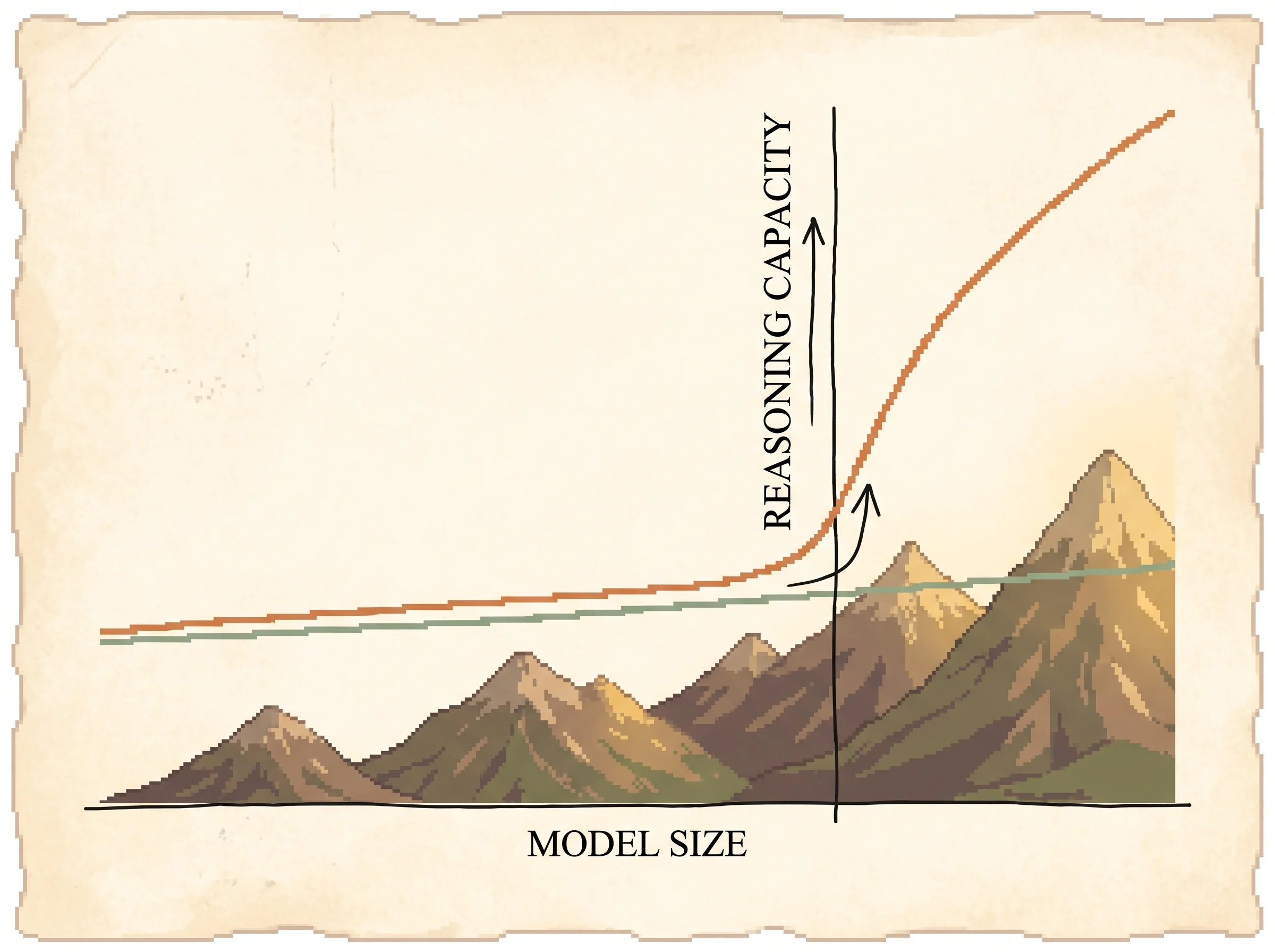
The delta against trained-rationale methods is that you drop the training entirely and put the rationales in the prompt, and the delta against vanilla few-shot is that the in-context examples carry worked reasoning instead of bare answers. The payoff is a method that needs no parameter updates and that turns a flat scaling curve into a sharply rising one on reasoning tasks. Standard prompting's scaling curve is close to flat on GSM8K; chain of thought's climbs steeply past 100B.
The choices read as deliberate. The three ablations exist to kill the three competing explanations, equation-extraction, raw extra compute, and knowledge-surfacing, and each one fails to reproduce the gain, which is what licenses the claim that the benefit is sequential natural-language reasoning. The robustness checks matter too. Different annotators, different exemplars, and exemplars sampled straight from the training set all beat standard prompting, so the effect doesn't hang on one person's prose style.
What would change my mind on the central claim. If the gain showed up in the dots ablation, the story would collapse into "more compute," and if it showed up with the chain placed after the answer, it would collapse into "knowledge retrieval." Neither happened. The honest soft spot is that emergence is shown, not explained, and that the analysis of why scale fixes broken steps is a small manual study. The open question the paper leaves wide, how to induce reasoning in smaller models, is exactly where the next wave of work went.
How it works
The problem and why prior approaches failed. Sequence models that answer in one shot struggle on tasks that decompose into several steps, like grade-school math word problems. Two earlier ideas each hit a wall. Training a model to emit reasoning steps works but needs a large set of hand-written rationales, which is costly. Few-shot prompting needs no training but does poorly on reasoning and barely improves with scale. Neither gives you cheap reasoning on a model you didn't train.
The key idea. Put the reasoning into the few-shot examples. Each exemplar becomes a triple of input, chain of thought, and output, where the chain of thought is a short series of natural-language steps that lead to the answer. A large model shown a few of these will produce its own chain of thought on a new problem before answering. No weights change.
Methodology. The setup is plain few-shot prompting with the exemplars augmented by reasoning. For the math tasks the authors hand-wrote eight chain-of-thought exemplars and reused them across benchmarks. They tested five model families (GPT-3, LaMDA, PaLM, UL2 20B, Codex) at sizes from 0.4B to 540B, decoding greedily. The comparison is always against standard prompting on the same model, same examples, same task.
The reason writing steps helps is that it moves each intermediate result into the text. Take "23 apples, use 20, buy 6."
Standard: the model must output the final number in one prediction.
it grabs salient numbers and lands on 27. wrong.
Chain: "23 - 20 = 3" <- first step, written out
"3 + 6 = 9" <- reads the 3 from the line above
"The answer is 9." <- rightEach line is a short local prediction the model is good at, and the second line reads its input off the first instead of recomputing it. That threading is also the weak point. If the first line comes out as "23 minus 20 is 4," the second line faithfully computes "4 plus 6 is 10," and the answer is wrong even though the second step did its job. One bad link breaks the chain. Load any chain-of-thought mode in the simulation and click a step to break it; the wrong value flows straight to the answer.
Why scale matters. The authors read 50 chains from a small model that got the answer right and 50 from one that got it wrong. Most wrong answers came from a chain that was fluent but had a calculator slip, a missing step, or a semantic misunderstanding. Scaling the model up fixed most of those step-level errors. So reasoning here is an emergent ability. The chain-of-thought gain is near zero for small models and turns on sharply once the model is big enough to keep each step sound.
The ablations. Three control conditions rule out the easy explanations.
Equation only output just the equation, no words -> barely helps on GSM8K
Variable compute (dots) output dots = equation length -> scores like baseline
Reasoning after answer answer first, then the chain -> scores like baselineEquation-only fails because turning the words into an equation is the hard part. Dots fail because raw extra compute without reasoning buys nothing. Reasoning-after fails because the answer is already committed before the reasoning runs. Only natural-language reasoning produced before the answer gives the gain.
Results with effect sizes. On GSM8K, PaLM 540B went from 18 percent with standard prompting to 57 percent with chain of thought, beating the prior best of 55 percent (a finetuned GPT-3 with a verifier). The gain was largest on the hardest, most multi-step datasets and smallest or negative on single-step ones. Chain of thought also helped commonsense reasoning, where PaLM 540B beat the prior state of the art on StrategyQA (75.6 vs 69.4 percent) and beat an unaided sports enthusiast on sports understanding (95.4 vs 84 percent), and it helped symbolic tasks, where it enabled length generalization to inputs longer than any exemplar.
Limitations and open questions. Chain of thought emulates reasoning without answering whether the network reasons. There's no guarantee the written chain is faithful, so it can produce a correct-looking chain with a wrong answer or the reverse. And the ability only appears at large scale, which makes it costly to serve. Inducing reasoning in smaller models is left open.
My assessment
The authors got the central call right, and the years since have been blunt about it. Chain of thought became the default way to get reasoning out of a large model, and almost every later trick, self-consistency voting, tree search over chains, zero-shot "let's think step by step," scratchpads, builds directly on it. The method's strength is how little it costs. No training, no data, no new parameters, just a better prompt, and the gain on hard tasks is large.
The part the paper handles best is the ablation discipline. It would have been easy to show the headline number and stop. Instead they killed the three obvious alternative explanations one at a time, which is what turns "this prompt helps" into "this prompt helps because of sequential natural-language reasoning." That's the difference between a trick and a finding.
Where the paper is honestly thin is the why behind emergence. It shows reasoning turns on with scale and gives a small manual error analysis as the mechanism, but it doesn't explain why a 540B model keeps a step sound that a 8B model drops. It also can't promise the chain is faithful, which later work confirmed as a real problem, since models can reach the right answer through a wrong chain or write a clean chain to a wrong answer. None of that dents the core result. Showing the steps, on a model big enough to get them right, was most of what unlocked reasoning.