CRMArena: Understanding the Capacity of LLM Agents to Perform Professional CRM Tasks in Realistic Environments
A benchmark that drops AI agents into a realistic Salesforce org and finds that even the best ones solve fewer than two-thirds of everyday customer-service tasks.
Read at your level
Start where you're comfortable and climb as far as you like.
- For a 5-year-old
- For a high schooler
- For a college student
- For an industry pro
- For a PhD candidate
- For a peer researcher
Executive summary
Companies want to hand routine customer-service work to AI agents, but nobody had a fair way to test whether the agents are ready. Most agent benchmarks use toy databases and simple click-through tasks that look nothing like real work. CRMArena fixes that. The authors built a fake but realistic shoe company inside a real Salesforce org, filling 16 connected record types (accounts, orders, cases, agents, knowledge articles) with data that mirrors how a real business is wired together. Then they wrote nine tasks that real service managers, agents, and analysts do every day, checked by Salesforce experts who rated the setup realistic 90% of the time. When they turned the best AI agents loose on it, the agents struggled. The top model solved 57.7% of tasks with ReAct prompting and 64.3% even when handed custom tools. The catch is that the work is a chain of dependent steps, and a single wrong call early on derails everything after it.
Try it
Load the Reasoner clears it preset and step through it to watch a strong agent thread the dependent calls and submit the right answer. Then load Weak model stalls and step again, and watch a small model botch an early call and run out of turns. The sharp one is Tools backfire (weak), the same weak model now handed task-specific functions. Run it and the clean tools still don't save a model that can't call them. While any run is going, hit Drop result to delete a tool's output mid-turn, or Pull function on a task-specific run to yank the wrapper the current step needs, and watch the chain react.
o1 under ReAct on a clean chain. Step it and watch the agent thread the dependent calls and submit the right answer.
A strong reasoning model. It clears long dependency chains and recovers from most errors, the best overall in the paper.
A thought before every action. The reasoning step lifts both tool choice and error recovery.
Step or play to watch the agent work the chain turn by turn.
Step, strike, or flip a control to start the log.
Each task is a chain of dependent tool calls graded by exact match, exactly as the paper frames it as a POMDP. The per-step success odds are illustrative, hand-set so the relative ordering of models matches Table 2 of the paper; a real run queries a live Salesforce org with thousands of objects across 4of the paper's 9 tasks. Each preset fixes the random seed so the same preset always produces the same run — switch presets or change a control to start a fresh chain.
For a 5-year-old
Imagine a new helper at a toy store. A kid walks up and says, "Show me the red truck I bought last summer." The helper can't just guess. First the helper has to find the kid's name in the big book. Then find the list of toys that kid bought. Then look through that list for a red truck. Then point to the right one. That's four steps, and each step needs the answer from the step before it.
If the helper gets one step wrong, like flipping to the wrong kid's page, every step after that is wrong too. The helper ends up pointing at the wrong toy.
Some helpers are really good at this. They keep their place, fix little mistakes, and find the truck. Some helpers get confused fast and give up. This is a test to see which AI helpers are good at the toy-store job and which ones aren't.
Real stores don't use a paper book. The records live in a computer system, and the helper is a computer program that asks the system questions. But the job is the same. Look something up, use what you found to look up the next thing, and keep going until you can answer.
For a high schooler
You've used a chatbot that can do things, like book a flight or pull up your order. Those are called agents. An agent reads what you want, then takes actions to get it done, like searching a database or calling a function. The question this paper asks is simple. Can these agents do a real office job, not a demo?
To find out, the authors built a pretend company inside Salesforce, which is the software a huge number of companies use to track customers. Here's the one new word for this section. A record is one row of saved information, like one customer or one order or one support case. The pretend company has 16 kinds of records, and they're linked. A support case points to a customer, who points to their orders, which point to products. Real data is tangled like this, and that tangle is what makes the job hard.
Here's a worked example. A customer says, "Show me the running shoes I bought last year." The agent has to do four things in order. Find the customer's record. Pull their order history. Match "running shoes" to the one product they actually bought. Return that order. Notice that step three needs the list from step two, which needs the ID from step one. Drop the ball on step one and the rest is garbage.
The agents got graded pass or fail on each task, so a near-miss counts as a miss. The best agent passed 57.7% of the time. That's the score of a student who studied but still flunks four questions out of ten.
For a college student
You should care about this because agents are moving from demos into real workplaces, and the gap between "works in a screenshot" and "works on the job" is where money gets lost. Prior agent benchmarks made that gap invisible. WorkBench, Tau-Bench, and WorkArena use databases with few objects and shallow links, and tasks like filling a form or filtering a list. CRMArena was built to be hard in the way real work is hard.
The setup has two pieces. First, a synthesized organization. The authors used an LLM-driven pipeline to generate data matching Salesforce's Service Cloud schema, 16 object types with an average of 1.31 dependencies per object, the highest of any comparable benchmark. They added latent variables, hidden factors like a customer's shopping habit or an agent's skill, so the data has the kind of buried causal structure real data has. They deduplicated it, ran format and content verifiers on it, then uploaded the clean version into a real Salesforce org without the latent variables, which makes the agent infer them the way a real worker would.
Second, nine tasks across three personas. A service manager routes cases and tracks team performance, a service agent answers customers, and an analyst spots trends. Each task is posed as a natural-language query with a ground-truth answer computed from the database.
The key idea is to frame each task as a POMDP, a partially observable Markov decision process. The agent can't see the whole database. It only sees what it queries.
(U, S, A, O, T, R) actions a in A, observation o in O, reward r in {0, 1}
A = { execute <query>, submit <result> }The agent issues a query, reads the observation, queries again, and eventually submits. The reward is 1 if the submitted answer exactly matches the ground truth, 0 otherwise. Knowledge QA is graded with F1 since it's open-ended text, but everything else is exact match.
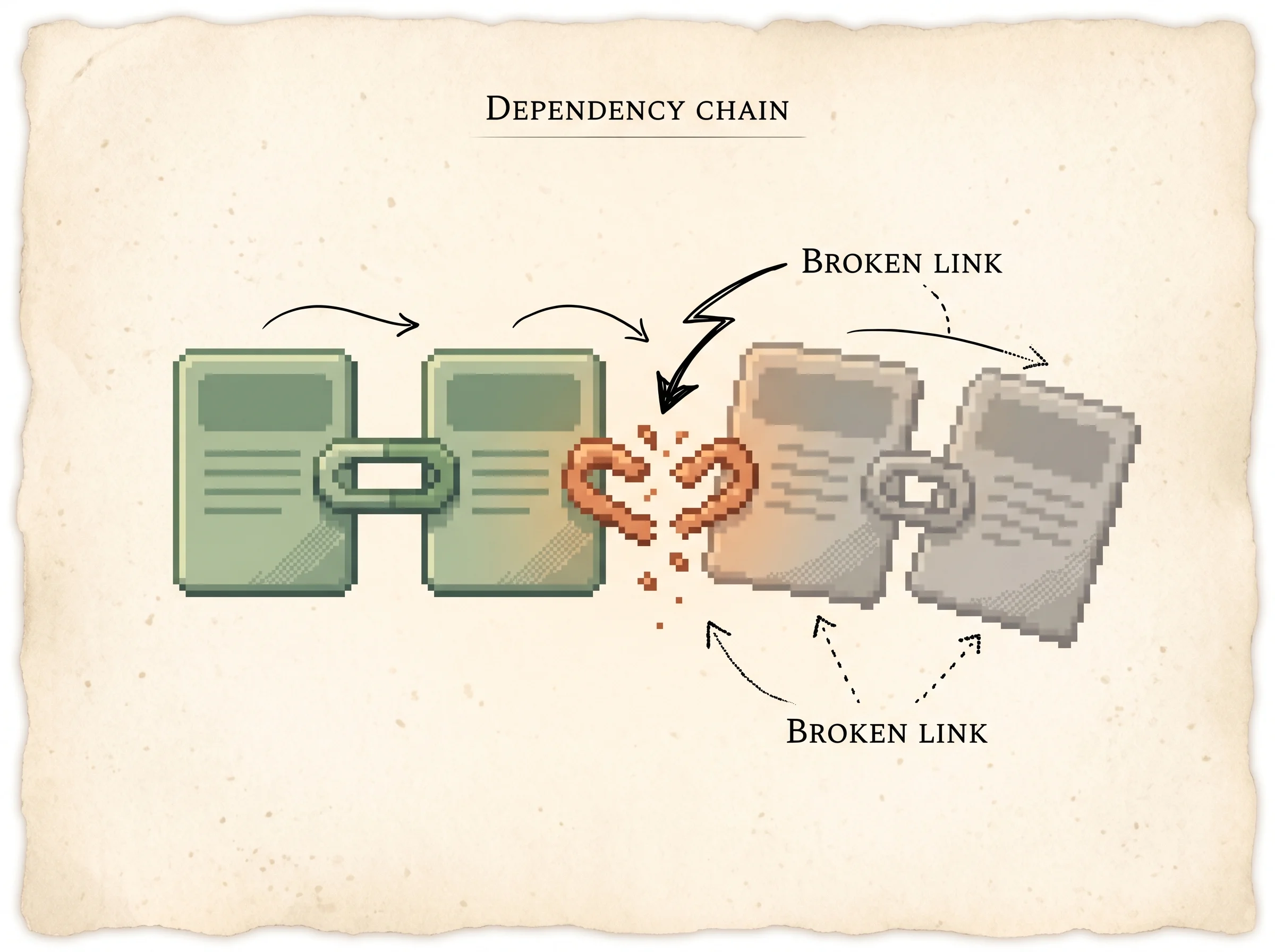
The dependency chain is why this is hard. A task isn't one lookup, it's a sequence where each call's arguments come from the previous call's result. Break a link early and every step downstream inherits the error. Step the Reasoner clears it preset in the simulation to watch a model walk the chain, then load Weak model stalls to watch one snap an early link and never recover.
The agents got two kinds of tools. General-purpose tools are raw SOQL and SOSL queries, the agent has to compose the database query itself. Task-specific tools are 27 hand-written Python wrappers that do common operations cleanly. You'd expect the wrappers to help everyone. They don't, and that's the most interesting result.
For an industry pro
The problem this solves for you is evaluation honesty. Before you put an agent on real CRM work, you need a number that predicts production behavior, not a benchmark that scores 95% and then falls over on your actual org. CRMArena is the realistic stand-in. It runs on a true Salesforce org with deeply linked objects and tasks that domain experts signed off on, and 90% of those experts rated the environment realistic or better.
The headline number is the warning. The best agent, an o1-class reasoning model under ReAct, solved 57.7% of tasks. Hand every agent custom function-calling tools and the ceiling moves to 64.3%. So even in the friendliest setup, a third of routine service tasks fail, and the failures are silent wrong answers, not error messages.
The deployment cost has a sharp edge you need to plan around. Custom tools are not a free win. Strong models (gpt-4o, claude-3.5-sonnet) score higher when you give them function-calling tools. Weak models score lower with the same tools, because they can't call the functions cleanly and the extra schema just trips them up. The paper measured this directly by pulling functions out one at a time. For gpt-4o, removing a calculation function dropped its score by up to 26.7 points, the function was clearly helping. For weaker models the same removal sometimes raised the score, meaning the function was a net drag. Run the Tools backfire (weak) preset and you'll see a weak agent fail just as often with the fancy tools as without them.

Cost matters too. The paper found gpt-4o the most cost-effective across frameworks, lowest cost per instance and fewest turns. The expensive reasoning models score higher but burn far more tokens. The practical read is to use a strong general model with good function-calling, write tools only if your model is strong enough to use them, and budget for a real failure rate. Watch the consistency too. The pass^k metric, the chance an agent gets the same task right on all k tries, drops fast as k grows for every framework. An agent that passes once may flunk the next identical request, which is a problem when you're running the same workflow thousands of times a day.
For a PhD candidate
The contribution is an expert-validated, high-connectivity agent benchmark grounded in a real enterprise system, plus the empirical finding that tool augmentation interacts with model capability rather than helping uniformly. Position it against the work-agent benchmarks. WorkBench and WorkArena test web and workplace tasks but with low object connectivity and shallow tasks. Tau-Bench adds user simulation but stays simple on the data side. CRMArena's delta is fidelity, 16 objects at 1.31 dependencies each, latent variables that inject hidden causal structure, and a real Salesforce backend rather than a mocked sandbox, all rated realistic by ten practicing CRM professionals.
The methodological choices reward scrutiny. Generating data with an LLM and then validating it with format and content verifiers is a reproducible recipe for synthetic-but-realistic enterprise data, and uploading a latent-variable-free version to the org forces the agent to infer the hidden structure rather than read it off. The POMDP framing is clean, with a binary terminal reward and exact-match grading that removes scoring ambiguity for the structured tasks. The three agentic frameworks (Act, ReAct, Function Calling) crossed with the two toolsets (general vs task-specific) give a real factorial over scaffolding, and the function-ablation table isolates which function categories help which models.
The sharpest result is the capability-dependent value of tools. The authors categorize functions by functionality (query vs calculation) and dependency (independent vs dependent on prior outputs), then remove each category and measure the delta. A negative delta means the function was useful. For gpt-4o, calculation-dependent functions show a delta of -26.7, strongly useful. For gpt-4o-mini and claude-3-sonnet, several deltas are positive, the function hurt. An intriguing exception is deepseek-r1, a strong reasoner whose tool-calling lags because of weak instruction adherence and poor adjustment to feedback, which separates reasoning skill from tool-use skill. And o1 in ReAct beats every model in Function Calling, suggesting function calling is unnecessary once reasoning is strong enough.
Threats to validity worth probing. The data is synthetic, so any bias in the generating LLM propagates, though the authors report a manual bias inspection that found nothing. The current setup links each case to one issue and one product, a simplification that makes some tasks tractable. The pass^k consistency analysis is the honest soft spot for the whole field, since it shows none of the three frameworks lets the top model reliably solve tasks under repeated trials.
For a peer researcher
The delta against WorkArena, Tau-Bench, and WorkBench is fidelity plus expert validation. CRMArena is the only one of the set that pairs a real-world environment (a live Salesforce org) with realistic work tasks and gets both signed off by domain experts. The connectivity gap is concrete, 1.31 dependencies per object against 0.86 for the next best, with 16 objects against 5 to 7. The latent variables are the underrated piece, since they're what let tasks like Transfer Count Understanding and the false-presupposition queries exist at all.
The choices read as deliberate tradeoffs. Exact-match grading buys unambiguous rewards at the cost of penalizing semantically-correct-but-differently-formatted answers, which is fine for IDs and counts and is why KQA gets F1 instead. Uploading without latent variables trades away an easy oracle for realism, since real workers don't get to see the hidden cause either. Synthetic data trades a privacy and scale win for a generator-bias risk they checked but can't fully rule out.
What would change my mind on the central claim that current agents aren't ready. If an agent cleared the high-70s under repeated trials, not single-shot, the "not ready" framing would weaken. The pass^k curves say that hasn't happened, since consistency decays at nearly the same rate across all three frameworks for the top model. The capability-dependent tool result is the finding I'd most want replicated on other model families, because it predicts that the standard advice to give agents more tools is wrong below some capability threshold, and that threshold is where most deployed open models live.
How it works
The problem and why prior approaches failed. Companies want LLM agents to handle routine CRM work, but there was no honest way to tell if an agent could. The existing benchmarks fell short on two fronts. Their data was too simple, with few object types and shallow links between them, so an agent never had to navigate the tangle of a real database. And their tasks were too easy, mostly navigating pages or filtering lists rather than the multi-step reasoning a real service job demands. An agent could ace those benchmarks and still fail on day one of real work.
The key idea. Build the test on a real Salesforce org filled with realistic, deeply connected data, and pose tasks that real CRM professionals actually do. Then frame each task as a POMDP where the agent only sees what it queries, chains tool calls to gather what it needs, and submits one answer that gets graded pass or fail.
Methodology. The data generation pipeline runs in stages. An LLM generates records matching the Salesforce Service Cloud schema across 16 object types. Because a product can pair with dozens of price-book entries, producing tens of thousands of rows, the pipeline uses mini-batch prompting with a batch size of 10 and feeds prior entries back in to avoid duplicates. Then it runs a two-phase deduplication and dual-layer verification.
format verifier -> does every entry have all required fields?
content verifier -> is the entry feasible and not too similar to others?Mini-batches that fail get discarded and regenerated. The pipeline also injects latent variables, hidden factors like ShoppingHabit and Skill, that shape the data the way unseen causes shape real data. The clean data, minus the latent variables, gets uploaded to a Simple Demo Org so the agent has to infer the hidden structure.
The nine tasks span three personas. Service Manager gets New Case Routing, Handle Time Understanding, and Transfer Count Understanding. Service Agent gets Named Entity Disambiguation, Policy Violation Identification, and Knowledge Question Answering. Service Analyst gets Top Issue Identification, Monthly Trend Analysis, and Best Region Identification. The query generation is a four-step process, a seed query with placeholders, ground-truth computation on the database, ID mapping from the generated data to the real org, and LLM paraphrasing for diversity. They also added false-presupposition queries, where the right answer is "None," to test whether an agent invents an answer that doesn't exist. About 30% of queries per applicable task are unanswerable, totaling 1,170 instances across nine tasks. Load the False-presupposition preset to watch a strong model hold back while the chain confirms there's nothing to find.
Results with effect sizes. The best model, o1 under ReAct, scored 57.7% overall. Equipped with task-specific functions, the ceiling rose to 64.3%. gpt-4o was the most cost-effective, lowest cost per instance and fewest turns. Stronger models gained from function calling while weaker ones lost from it, and the function-ablation table showed deltas as large as -26.7 (strongly helpful) for gpt-4o on calculation functions but positive (harmful) deltas for weaker models on the same functions. Open models like llama-3.1 closed much of the gap to the proprietary models, sometimes scoring higher, and showed more scope to recover from execution feedback. The pass^k consistency dropped at nearly the same rate across all three frameworks, so no scaffold made the top model reliable under repeated trials.
Limitations and open questions. The data is synthetic, so generator bias is a risk the authors checked manually but can't fully eliminate. The current org simplifies real CRM by linking each case to one issue and one product. The benchmark covers three personas and skips others like sales reps. The open challenge stands, build agents that reliably clear these tasks, since that translates directly to business value in a system enterprises already run.
My assessment
The authors got the most important thing right, which is realism you can trust. Building on a real Salesforce org with expert-validated data is the move that makes the benchmark worth caring about, and the 90% realism rating from practicing professionals is the kind of validation most agent benchmarks skip. The dependency-chain structure is what makes the tasks honest, since it punishes the brittle multi-step reasoning that breaks real deployments, and the false-presupposition queries are a smart way to catch agents that hallucinate answers.
The finding that lands hardest is the capability-dependent value of tools. The reflex in the field is to give agents more tools, but this paper shows that below some skill threshold, tools hurt. That inverts standard advice for exactly the open models most teams can afford to run, and it's the result I'd want replicated first. The honest soft spot the authors name themselves is the pass^k consistency, which says even the top model can't reliably repeat a success, and that's the real blocker for production, not the headline average. Where the paper is thinnest is generality, since synthetic data and a simplified org mean the absolute numbers should be read as directional rather than exact. None of that dents the core contribution. CRMArena turned "can agents do real work" from a vibe into a number, and the number is sobering.