Neural Machine Translation by Jointly Learning to Align and Translate
Instead of cramming a whole sentence into one fixed summary, the translator re-reads the source and decides which words to look at for every word it writes.

Read at your level
Start where you're comfortable and climb as far as you like.
- For a 5-year-old
- For a high schooler
- For a college student
- For an industry pro
- For a PhD candidate
- For a peer researcher
Executive summary
The first neural translators read the whole source sentence, squeezed it into one fixed-length vector, then wrote the translation from that one summary. That summary is a bottleneck. A short sentence fits, but a long one gets crushed, and the start fades by the time the model writes the end. This paper removes the bottleneck. At each output word, the decoder re-reads the source and scores every source word with a small trainable network, turns those scores into weights that sum to one, and reads back a weighted blend of the source. So instead of one frozen summary it gets a fresh, focused view for every word it writes. The model learns where to look with no alignment labels, just by training to translate. On English-to-French it matched a strong phrase-based system, and unlike the old neural model it held its quality on long sentences instead of falling apart. The cost is that it scores every source word for every output word, which is fine at 15 to 40 words but grows with sentence length.
Try it
Load the Reordered phrase preset, then step to the word zone and watch the bright weight jump ahead to Area, skipping over the two adjectives, the same reorder the paper shows. Then load Fixed-vector bottleneck, step through the long sentence, and watch every output word read the same flat blur. Flip the bottleneck off and the alignment snaps back to the right source word.
Soft attention on a sentence that lines up word for word. Play it and watch the bright cell walk straight down the diagonal.
Ellelisaitlavieillelettrelentement
source: She read the old letter slowly
Source and target line up almost one to one, so the alignment runs down the diagonal.
Off: the decoder re-reads the source for each word, the paper's RNNsearch.
| source word | energy | weight |
|---|---|---|
| She | 3.86 | 31% |
| read | 3.05 | 14% |
| the | 3.05 | 14% |
| old | 3.05 | 14% |
| letter | 3.05 | 14% |
| slowly | 3.05 | 14% |
Step, switch a sentence, or flip the bottleneck to start the log.
The alignment math here is the paper's additive model, energy e = v_a·tanh(W_a s + U_a h) softmaxed over the source into weights that sum to one, then the context c = Σ α h. The source annotations and what each output word reaches for are hand-set so the alignments are legible, where a trained model learns those from data. The run is fully deterministic. This runs a few short sentences; the paper's model runs 1000-unit RNNs over sentences of 30 to 50 words.
For a 5-year-old
Imagine you have a long letter to copy into another language. One way is to read the whole letter, fold it up, put it in your pocket, and write from memory. For a short note that works. For a long letter you forget the beginning by the time you reach the end, and your copy gets mushy.
A better way is to keep the letter open on the table. As you write each word, you glance back at the letter and find the one line you need right now. Write a word, glance back, write the next word, glance back. You never have to hold the whole thing in your head, so it doesn't matter how long the letter is.
That glancing back is the whole idea. For every word the translator writes, it looks back at the open letter and picks the parts that matter for that word.
The translator doesn't really have eyes and a letter on a table. The glancing is math with numbers, where every source word gets a score and the biggest scores win. But the feeling is the same. Keep the source in front of you and look back at the right spot for each word.
For a high schooler
You've used a translation app. You type a sentence and it gives you another language back. The early neural versions did something a little strange inside. They read your whole sentence, mashed it into one fixed list of numbers, and then wrote the translation using only that list. Think of it like reading a paragraph and then summarizing it in exactly 100 numbers, no matter how long the paragraph was. A short sentence survives. A long one loses detail, because 100 numbers can only hold so much.
This paper fixes that with one idea. Here's the one new word for this section. Alignment means matching each word you write to the source words it came from. Instead of one frozen summary, the model keeps every source word's information around. When it's about to write a word, it asks "which source words do I need for this one?" It scores each source word, turns the scores into weights that add up to 100 percent, and pulls back a blend that leans toward the highest-scoring words.
Here's a worked example with tiny numbers. Say the model is writing a French word and it scores the English word "doctor" at 9, "hospital" at 2, and everything else near 0. Run those scores through the weighting step and "doctor" gets about 91 percent of the attention, "hospital" gets about 8 percent, and the rest split the crumbs. So the model writes its word mostly from "doctor."
Because it does this fresh for every word it writes, the length of the sentence stops mattering. It never has to hold the whole thing in one summary.
For a college student
You should care about this because it's the paper that introduced attention to sequence models, and attention is the engine under every modern translation and language model. The setup is an encoder-decoder for translation. An encoder reads the source sentence, a decoder writes the target one word at a time. The standard version of the day, from Cho et al. and Sutskever et al., squeezed the whole source into a single fixed-length vector c and conditioned every decoding step on that same c. The authors conjectured that this fixed c is a bottleneck, and that it's why quality drops on long sentences.
The fix is a context vector that changes for every output word. Let the source produce a sequence of annotations h_1, ..., h_Tx, one per source word. When the decoder is about to emit target word i, it builds its own context c_i as a weighted sum of those annotations.
c_i = sum_j alpha_ij * h_jThe weights alpha_ij come from a softmax over alignment energies, and the energy is a small feedforward network that scores how well source word j fits the decoder's state just before it emits word i.
e_ij = v_a^T tanh(W_a s_{i-1} + U_a h_j)
alpha_ij = exp(e_ij) / sum_k exp(e_ik)Read it inside out. W_a s_{i-1} is the decoder asking a question from its current state. U_a h_j is source word j offering its content. Add them, squash with tanh, score with v_a, and you get one number saying how relevant word j is right now. Softmax over all source words turns those numbers into weights that sum to one, and the weighted sum gives c_i.
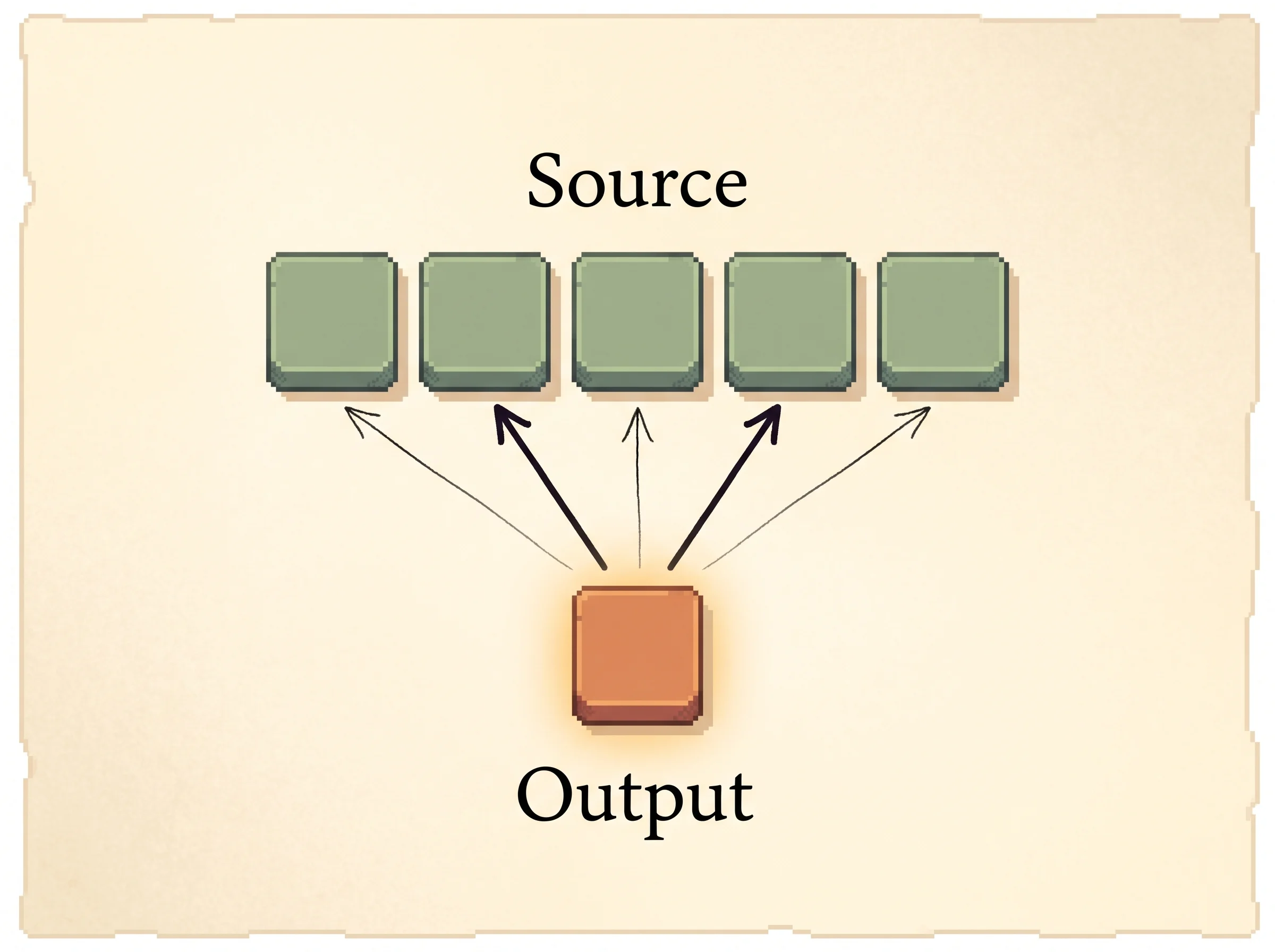
The whole alignment network is differentiable, so the gradient flows back through it. The model learns where to look just from the translation loss, with no alignment supervision. The old encoder-decoder is the special case where you freeze c_i to the last annotation for every i. Load the Fixed-vector bottleneck preset in the simulation to see that collapse. Every output word reads the same flat blur because there's only one summary to read.
One worked path, end to end. English "the European Economic Area" becomes French "zone economique europeenne", which flips the order. When the model writes "zone" it needs "Area", which sits at the end of the English phrase, so the weight jumps ahead past the two adjectives, then walks back over them for the next words. The simulation's Reordered phrase preset is exactly this. The soft alignment handles the reorder with no special rule, because it's free to put weight wherever the energies point.
The limitation is cost. Computing e_ij for every source-target pair is O(Tx * Ty) runs of the alignment network. For sentences of 15 to 40 words that's cheap, but it grows with length, which the authors flag for other tasks.
For an industry pro
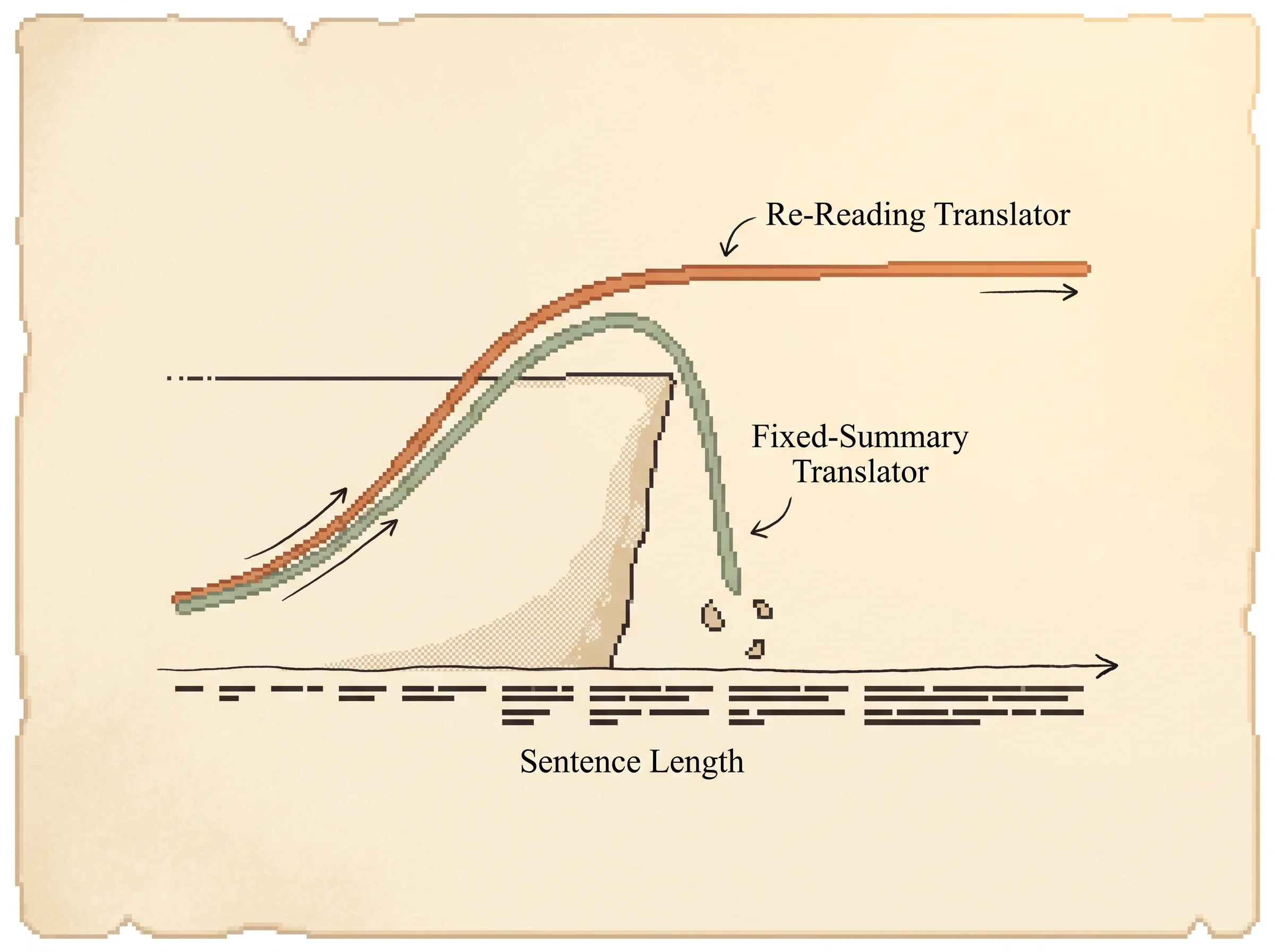
The problem this solves is long-input quality. The fixed-vector encoder-decoder squeezes the whole source into one vector and writes from it, so quality falls off as inputs get longer. The paper shows the basic model dropping hard past 30 words while the attention model stays flat out to 50 and beyond.
What it costs you is compute per output word. The model scores every source position for every target position, so attention is roughly quadratic in sequence length. At translation scale that's a rounding error next to the RNN itself. At very long inputs it becomes the thing you budget for, which is why later work spent years making attention cheaper.
The expected improvement is real. On English-to-French, the attention model (RNNsearch) hit 28.45 BLEU on the full test set after long training, against 17.82 for the basic encoder-decoder at the same sentence length, and it landed near Moses, a phrase-based system that also used a 418-million-word monolingual corpus the neural models never saw. The shorter-context attention model even beat the longer-context bottleneck model, which tells you the bottleneck, not the sequence length, was the binding constraint. The failure mode to plan around is rare and unknown words. The model uses a 30,000-word shortlist and maps everything else to a single unknown token, so out-of-vocabulary terms still hurt.
For a PhD candidate
The contribution is replacing the fixed-length context vector of the encoder-decoder with a per-step, attention-weighted context, and showing the alignment can be learned jointly with translation from the end task alone. Prior neural MT, Cho et al. and Sutskever et al., encoded the source into one vector and decoded from it, and Cho et al. had already shown that quality degrades with source length. This paper names that fixed vector as the cause and removes it.
The methodological choices reward scrutiny. The alignment is soft, a full distribution over source positions, not a hard pick, so the model is differentiable end to end and trains with plain backprop, no latent-variable machinery and no EM. The energy is additive, v_a^T tanh(W_a s_{i-1} + U_a h_j), a one-hidden-layer MLP, rather than a dot product, which the later Transformer would switch to for speed. The encoder is a bidirectional RNN, so each annotation h_j summarizes the whole sentence with a focus on the words around position j, which matters because the alignment then has both left and right context to score against. The decoder uses gated (GRU) hidden units and a deep maxout output layer.
Threats to validity worth probing. The headline result is one language pair, English-to-French, with sentences mostly in the 15 to 40 word range, so the long-sentence claim is shown but not stressed to the extreme. The alignment quality is argued from four hand-picked heatmaps in Figure 3, which is suggestive rather than systematic. And the comparison to Moses is honest but asymmetric, since Moses leans on a large monolingual corpus the neural models lacked. The obvious follow-ups, most of which the field then chased, are cheaper alignment for long inputs, better handling of rare and unknown words, and whether the recurrent backbone is even needed once you have attention.
For a peer researcher
The delta against the standard encoder-decoder is that the context stops being a single fixed vector and becomes a learned, per-target-step convex combination of source annotations. The alignment model is trained jointly, with no alignment labels and no separate alignment stage, because the soft weights are differentiable and the whole thing backprops as one network.
The choices read as deliberate tradeoffs. Soft over hard alignment buys differentiability and joint training at the cost of attending to everything a little, which is the right trade when you want one clean gradient path. Additive energy over a dot product buys a slightly richer scoring function at the cost of a matrix multiply you can't fuse as cleanly, a trade the Transformer would later reverse for throughput. A bidirectional encoder buys two-sided context per annotation at the cost of needing the full sentence before decoding, fine for translation, awkward for streaming.
What would change my mind on the central claim. If the basic encoder-decoder matched the long-sentence quality once you scaled the fixed vector, the bottleneck story would weaken. It didn't. The RNNsearch-30 beating RNNenc-50 is the cleanest evidence that the fixed vector, not capacity or length, was the binding constraint. The honest soft spot is the quadratic alignment cost and the unknown-word handling, and the open question the paper leaves wide open, scaling this to long documents and to large vocabularies, is exactly where the next few years of work went.
How it works
The problem and why prior approaches failed. Translation here is modeled as p(y | x), the probability of a target sentence given a source. The neural encoder-decoder reads the source x = (x_1, ..., x_Tx) into a single vector c, then decodes the target one word at a time conditioned on c and the words so far. The trouble is that c is fixed-length. A neural net has to compress everything it might need about the source into that one vector, regardless of source length. Cho et al. showed empirically that quality drops sharply as sentences get longer, which is what you'd expect if a long source overflows a fixed summary.
The key idea. Don't compress the source into one vector. Keep an annotation per source word, and let the decoder build a fresh context for every word it writes by attending over those annotations. The context follows the output, so nothing has to survive in one frozen summary.
Methodology. The encoder is a bidirectional RNN. The forward RNN reads left to right, the backward RNN reads right to left, and the annotation for source word j concatenates both.
h_j = [ forward_h_j ; backward_h_j ]So h_j carries the whole sentence with a focus on the words around position j. The decoder defines each target word's probability with its own context c_i.
p(y_i | y_1, ..., y_{i-1}, x) = g(y_{i-1}, s_i, c_i)
s_i = f(s_{i-1}, y_{i-1}, c_i)The context is the attention-weighted sum of annotations, and the weights come from the additive alignment network softmaxed over the source.
c_i = sum_j alpha_ij * h_j
alpha_ij = exp(e_ij) / sum_k exp(e_ik)
e_ij = v_a^T tanh(W_a s_{i-1} + U_a h_j)Every piece, the encoder, the decoder, and the alignment network (v_a, W_a, U_a), trains together by maximizing the log-probability of correct translations. Switch the simulation to the Monotonic copy preset and play it to watch the bright weight walk straight down the diagonal when source and target line up. Then switch to Reordered phrase to watch it jump when they don't.
Results with effect sizes. On WMT'14 English-to-French, the attention model RNNsearch-50 scored 26.75 BLEU on the full test set and 28.45 after extended training, against 17.82 for the basic RNNenc-50. On sentences with no unknown words it reached 36.15 BLEU, close to Moses at 35.63, even though Moses used a 418-million-word monolingual corpus the neural models never saw. The attention model trained on shorter sentences (RNNsearch-30 at 21.50) still beat the bottleneck model trained on longer ones (RNNenc-50 at 17.82), which isolates the fixed vector as the cause. On long sentences the basic model's BLEU fell off a cliff past length 30 while the attention model stayed flat past 50.
Limitations and open questions. The alignment costs O(Tx * Ty) network evaluations, fine for 15-to-40-word sentences but growing with length. The 30,000-word vocabulary maps everything else to one unknown token, so rare words stay a weak point. The alignment quality is shown through a handful of heatmaps, not measured against gold alignments.
My assessment
The authors got the core call right, and the field's whole trajectory says so. Attention, born here as a fix for a translation bottleneck, turned out to be the load-bearing idea of modern deep learning. Three years later the Transformer would throw out the RNN entirely and keep only attention, and every large language model since descends from that move. This paper is where the mechanism first appears, fully formed, soft and differentiable and trained from the end task with no alignment labels.
What they undersold is how general the idea was. The framing is all machine translation, and the evidence is one language pair, so they pitch attention as a cure for the fixed-vector bottleneck rather than as a new primitive for relating any two sequences. That's a limit of what two WMT tasks could show, not a mistake. The honest soft spots they named, the quadratic alignment cost and the unknown-word problem, defined the next several years of research, from large-vocabulary tricks to the efficient-attention line that runs through to FlashAttention. The additive energy was the part time replaced, swapped for a scaled dot product once throughput mattered more than the extra expressiveness. None of that dents the core. Letting the model choose where to look, and learning that choice from the task alone, was the right idea, and it stuck.