DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
A 7-billion-parameter open model reaches near-GPT-4 math scores by mining the web for math and training with GRPO, a reinforcement learning method that grades a group of answers against their own average instead of paying for a separate judge.
Read at your level
Start where you're comfortable and climb as far as you like.
- For a 5-year-old
- For a high schooler
- For a college student
- For an industry pro
- For a PhD candidate
- For a peer researcher
Executive summary
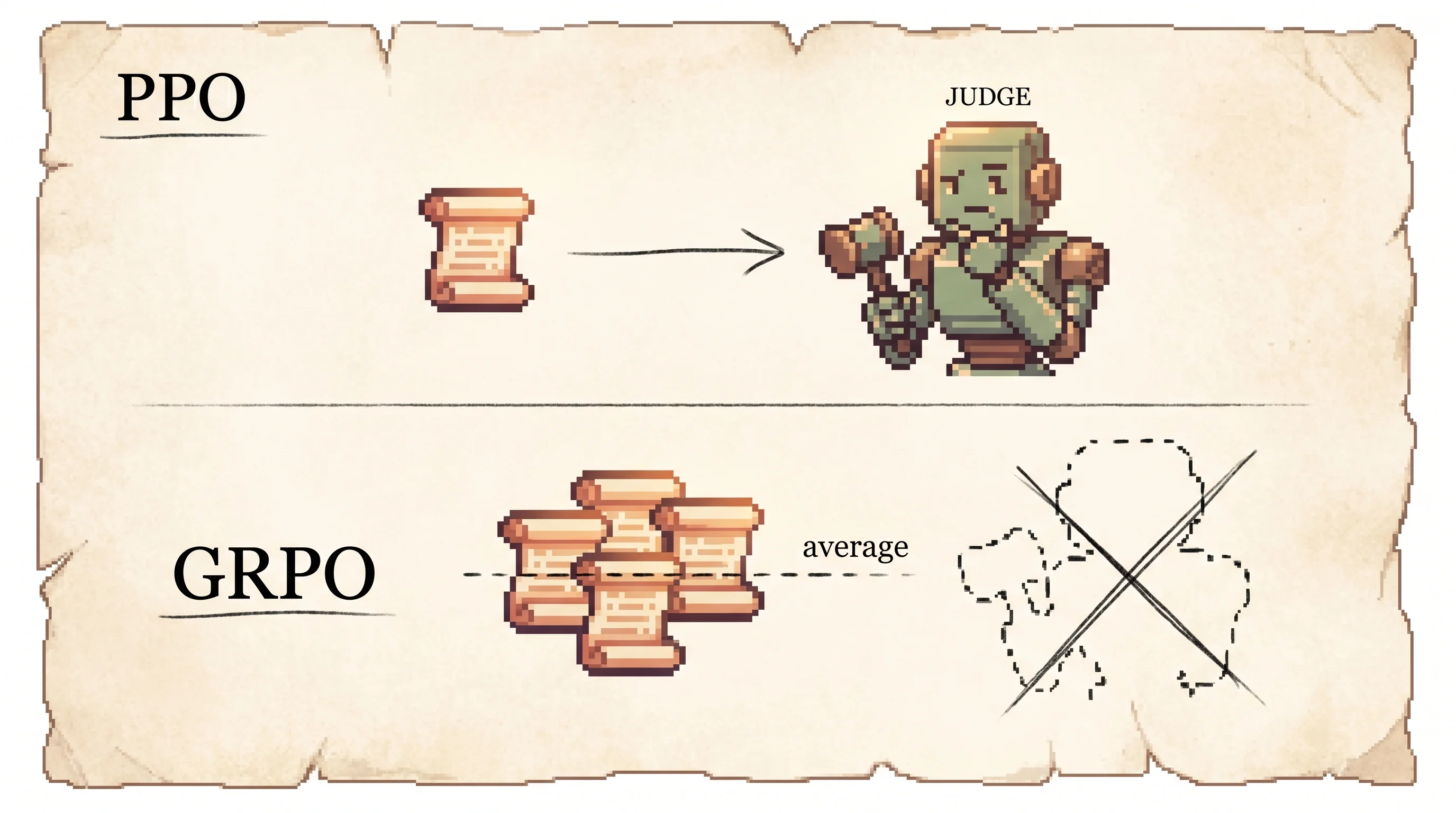
A small open model could not do hard math, and the strong models that could were closed. DeepSeekMath fixes that with two moves. First it builds a 120-billion-token math corpus by mining Common Crawl with a classifier that learns what math web pages look like, then it keeps pre-training a 7B code model on that corpus. That alone scores 51.7% on the competition-level MATH benchmark, close to GPT-4 and Gemini-Ultra. Second it sharpens the model with reinforcement learning using a new method, Group Relative Policy Optimization. GRPO drops the separate value model that PPO trains alongside the policy, which is a model as big as the policy itself, and replaces it with a cheaper baseline. For each question it samples a group of answers, scores them, and grades each answer against the group's own average. That single change cuts the memory bill roughly in half and still lifts GSM8K from 82.9% to 88.2% and MATH from 46.8% to 51.7%. The honest catch is that the gain is narrow. The model gets better at picking the right answer it already knew how to produce, not at solving problems it could never solve before.
Try it
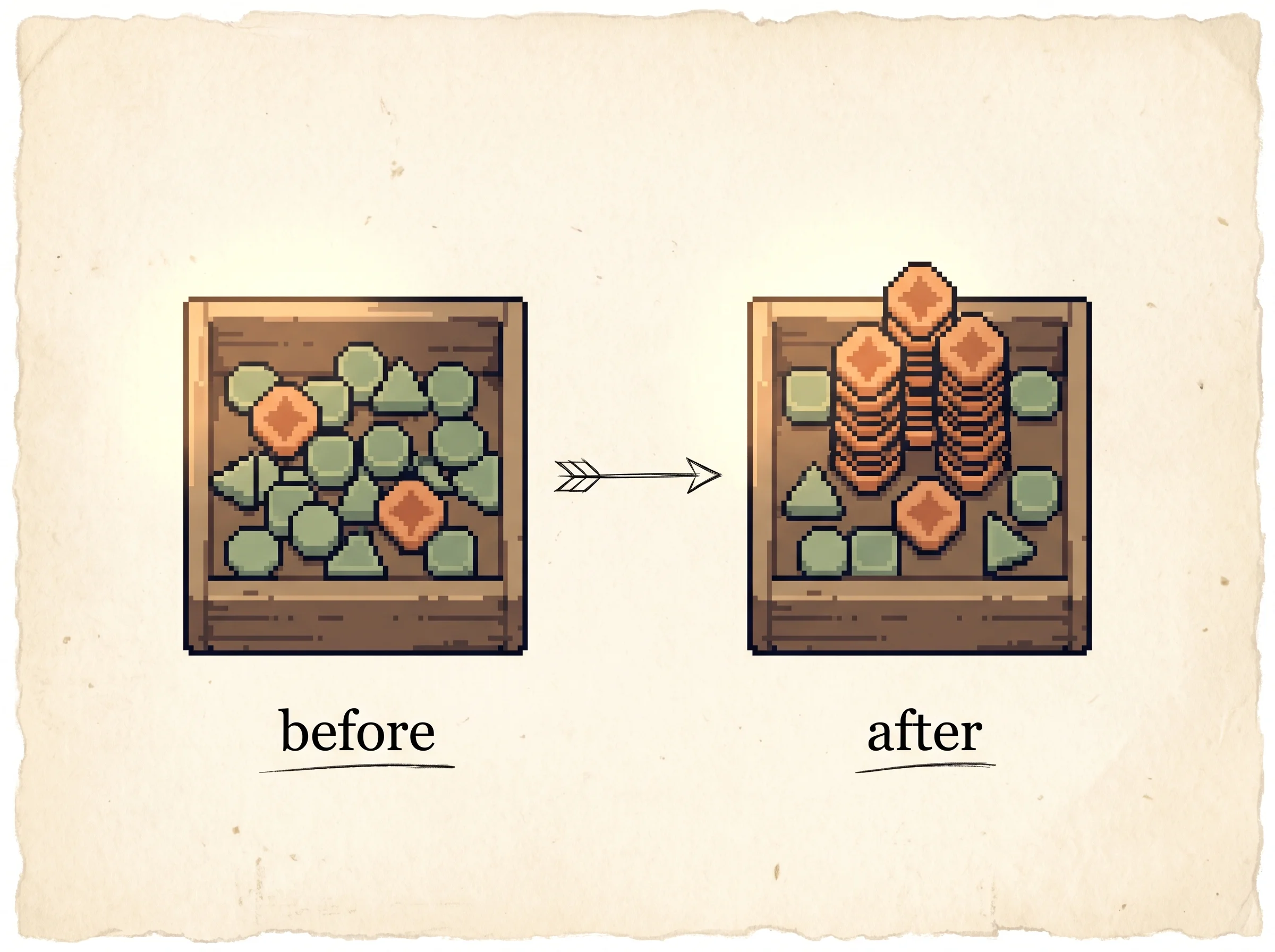
Load the Sharpen onto correct preset and press play. Watch the mass climb onto the correct kinds while the group mean rises. Then load Reward hacking, which points the reward model at a wrong answer and hands it a fat bonus, and watch the policy march onto the wrong answer because GRPO trusts the score. Last, load Maj@K up, Pass@K flat and watch the two curves split, the headline finding of the paper.
The healthy GRPO run. Play it and watch the mass climb onto the correct kinds while the group mean rises and the KL term keeps the policy near the reference.
Solid bars are the current policy; the dashed line is the frozen reference the KL term pulls toward. Correct kinds are clay, wrong kinds are pale.
| kind | drawn | reward | advantage |
|---|---|---|---|
| Step or play to sample a group. | |||
Step, play, or move a knob to start the log.
This runs the GRPO objective on a softmax policy over 5answer kinds for one question, where the paper runs it on a 7B transformer sampling 64 outputs per question. The advantage is exactly the paper's group-relative normalization, the reward minus the group mean over the group standard deviation. The reward model here is a fixed table you can poison; a trained reward model learns its scores from data. The run is deterministic — same preset always produces the same trajectory.
For a 5-year-old
Imagine a teacher asks the class one math question. Five kids each write down an answer on a card. Now the teacher wants to tell each kid if they did well or not so they can get better next time.
The old way needed a grown-up expert standing in the corner whose only job was to guess how good each answer would be before anyone even checked it. That expert costs a lot. You have to feed it and train it, and it takes up a whole extra chair.
The new way skips the expert. The teacher just looks at all five cards together and finds the middle. Any kid who did better than the middle of the class gets a thumbs up. Any kid who did worse than the middle gets a thumbs down. The class is its own measuring stick.
The kids who got a thumbs up try to do that more next time. The kids who got a thumbs down try to do it less. Slowly the whole class gets better at the question, and nobody had to pay for the expert in the corner.
There is no real teacher and no real cards. The answers are sentences the computer writes, and the thumbs up and down are numbers. But the trick is the same. Grade everyone against the middle of the group, and you don't need a judge.
For a high schooler
You've used a hint system in a game that tells you "warmer" or "colder" as you move. Reinforcement learning is that, for a computer learning to answer questions. The computer writes an answer, something grades it, and the grade tells the computer to do more of what worked and less of what didn't.
Here's the one new idea for this section. To turn a grade into a useful nudge, you can't just use the raw score. You need to know if a score is good or bad compared to what was expected. Scoring 70 on a test feels great if the class average was 50 and awful if it was 95. That comparison point is called a baseline, and the score minus the baseline is called the advantage.
The popular method before this, called PPO, learned the baseline with a second computer model that tried to predict the expected score for any answer. That second model is as big and expensive as the main one. GRPO throws it away. For each question it has the main model write a whole group of answers, say 16 of them, grades all 16, and uses the average of the group as the baseline.
Here's a worked example. Say the model writes 4 answers to one question and they score 1, 1, 0, 0. The group average is 0.5. So the two correct answers get an advantage of +0.5 and the two wrong ones get -0.5. The model then shifts to produce more of the +0.5 kind and less of the -0.5 kind. No second model needed, just a little arithmetic on the group.
Grade each answer against the group it came from, and the group pays for the baseline that used to need its own model.
For a college student
You should care about this because GRPO is now one of the standard ways to fine-tune language models with reinforcement learning, and this is the paper that introduced it. The motivation is cost. The actor-critic setup that PPO uses needs a value function, and in the language-model setting that value function is a separate network about the same size as the policy. Training and storing it is a large fraction of your RL compute and memory budget.
Recall what PPO optimizes. For each token it forms an advantage estimate, usually with GAE over a learned value function, and maximizes a clipped surrogate that keeps the new policy from moving too far from the old one in a single step. A KL penalty to a frozen reference model keeps the policy from drifting into nonsense the reward model would happily exploit.
GRPO keeps the clip and the KL but kills the value function. For each question q, sample a group of G outputs from the current policy. Score each with a reward model to get rewards r_1 through r_G. Then set the advantage of every token in output i to the group-normalized reward.
Â_i = (r_i - mean(r)) / std(r)
Subtracting the mean is the baseline. Dividing by the standard deviation rescales the advantages so a group where everyone scored about the same produces small nudges and a group with a clear winner produces large ones. The group average is an unbiased estimate of the expected reward for that question, which is exactly what the value function was trying to predict, so the group does the value function's job for free.
The full objective keeps the PPO machinery around that advantage.
J(θ) = E[ (1/G) Σ_i (1/|o_i|) Σ_t min( ρ_{i,t} Â_i, clip(ρ_{i,t}, 1-ε, 1+ε) Â_i ) - β D_KL(π_θ || π_ref) ]Read it piece by piece. ρ_{i,t} is the probability ratio of the new policy to the old one for token t of output i. The min of the raw and clipped surrogate is PPO's trust region, capping how far one step can move. One real difference from PPO is the KL term. PPO folds the KL penalty into the per-token reward, while GRPO adds it straight to the loss as a separate term, using an unbiased estimator that stays positive.
D_KL(π_θ || π_ref) = π_ref/π_θ - log(π_ref/π_θ) - 1The simulation above runs exactly this advantage on a toy policy. The slider for group size is G, the clip slider is ε, the KL slider is β. Turn off "divide by group std" and watch the advantages stop being rescaled, which is the difference between subtracting the mean and the full normalization.
The limitation is sharp and worth knowing before you reach for this. RL here reweights answers the model already produces. It does not expand what the model can produce. Set the starting policy so it almost never samples a correct answer (the No headroom preset) and no amount of training lifts the score, because there is nothing correct in the group to reward.
For an industry pro
The problem GRPO solves for you is the memory and compute bill of RLHF-style training. PPO carries a critic network roughly the size of your policy, and during training you hold the policy, the reference, the reward model, and the critic in memory at once. GRPO deletes the critic. You estimate the baseline from the average reward of a sampled group instead of from a learned value head, so you free up close to a model's worth of memory and the training that goes with it.
Deployment cost has a tradeoff baked in. You save the critic, but you pay in sampling. GRPO needs a group of outputs per question, and the paper samples 64. So you trade critic training for more inference during the RL loop. On the math tasks here that trade is clearly worth it, but if your reward is expensive to evaluate or your outputs are very long, the group sampling cost is the thing to size carefully.
The expected improvement is real but narrow, and the narrowness is the operating envelope you must plan around. On GSM8K the instruct model went from 82.9% to 88.2% and on MATH from 46.8% to 51.7%. But the paper is unusually honest about what kind of gain that is. RL improved the chance the model's top answer is correct (Maj@K) and barely moved the chance that at least one of many samples is correct (Pass@K). In plain terms, RL made the model better at choosing among answers it could already generate, not at generating new correct answers. If your task needs genuinely new capability rather than sharper selection, GRPO on its own will disappoint you.
The failure mode to watch is reward hacking. GRPO faithfully chases whatever the reward model scores high, so a reward model with a blind spot becomes a target the policy learns to exploit. The paper notes even carefully annotated process-reward datasets carry around 20% label errors. Load the Reward hacking preset in the simulation to watch the policy abandon the correct answer for a wrong one the reward model was tricked into liking.
For a PhD candidate
The contribution that travels beyond this paper is GRPO, a critic-free policy optimization method for the bandit-like setting of one-shot LLM generation. Prior work paid for a value function to get a low-variance advantage. GRPO observes that when the reward lands only on the full output, not per token, you can replace the learned baseline with the empirical mean of a sampled group from the same prompt. The group mean is an unbiased per-prompt baseline, and the standard-deviation normalization is a per-prompt variance reduction that the value function approach got from regression instead.
The methodological choices reward scrutiny. Moving the KL from the reward (PPO's per-token r_t - β log(π_θ/π_ref)) to a direct loss term with Schulman's unbiased estimator is not cosmetic. It keeps the reward signal clean and the divergence penalty explicit, and the estimator they use is guaranteed positive, which the naive log-ratio is not. The std normalization is a real design decision with a known wrinkle, since it inflates advantages when a group's rewards are nearly tied, and later work has questioned whether to keep it. The choice to sample 64 outputs is a variance-versus-cost knob, and the group mean's quality as a baseline improves with G.
The paper's most important empirical result is the Maj@K versus Pass@K split, because it constrains what we can claim RL did. RL lifted Maj@K and not Pass@K, which says the gain is a redistribution of probability mass toward correct outputs already in the model's support, not an expansion of that support. The authors connect this to a misalignment-style account where SFT models can already produce the right answer but rank it below wrong ones, and RL fixes the ranking. The simulation's Maj@K up, Pass@K flat preset reproduces this directly, and the No headroom preset shows the boundary condition where the support genuinely lacks the answer and RL is helpless.
The unified-paradigm framing in section 5 is worth engaging with. The authors write SFT, RFT, online RFT, DPO, PPO, and GRPO as one gradient with three swappable parts, the data source, the reward function, and the gradient coefficient. Within that frame, GRPO differs from online RFT mainly in that its gradient coefficient varies with the reward magnitude rather than treating every correct answer the same. That is a clean way to see why GRPO penalizes bad answers rather than only reinforcing good ones, and it is a genuinely useful lens for the field even if you never run GRPO.
For a peer researcher
The delta against PPO is one deletion and one relocation. Delete the value network, estimate the advantage from the group-relative normalized reward Â_i = (r_i - mean) / std, and relocate the KL from the per-token reward into a direct loss term with an unbiased, positive estimator. Everything else, the clipped surrogate and the trust region, is PPO. The payoff is roughly halving the model state held during RL, which matters at scale.
The choices read as deliberate tradeoffs. The group mean buys you a critic-free unbiased baseline at the cost of G samples per prompt, which is a good trade when reward is cheaper than a value-net forward-backward and outputs are short to medium. The std normalization trades a little bias in the tied-reward regime for variance reduction, and that is the part most contested downstream. Moving the KL to the loss trades PPO's reward-shaping interpretation for a cleaner separation of objective and regularizer.
What would change my mind on the central claim. If a critic-free baseline other than the group mean matched GRPO's stability at lower sampling cost, the specific group-relative construction would lose its edge while the critic-free insight survives. The honest soft spot is the Maj@K-not-Pass@K result, which the authors surface themselves. It says this RL pipeline sharpens an existing distribution rather than extending capability, and the open question the paper leaves wide open, how to get RL to improve Pass@K through better exploration and decoding, is exactly where the reasoning-RL field went next.
How it works
The problem and why prior approaches failed. Two problems, really. The capability problem is that strong math models were closed and open models lagged far behind, partly because nobody had assembled enough high-quality math training data in the open. The training-cost problem is that the standard way to fine-tune a model with reinforcement learning, PPO, carries a value network the size of the policy, and that critic is a large slice of the memory and compute. You need it because PPO's advantage estimate leans on a learned prediction of expected reward at each token.
The key idea. Two ideas. For data, train a fastText classifier to recognize math web pages, seed it with a known math corpus as positive examples, and iterate it over Common Crawl to mine 120B math tokens, far more than prior open math corpora. For RL, replace PPO's learned value baseline with the average reward of a group of answers sampled for the same question. The group is its own baseline, so the critic disappears.
Methodology. Start from DeepSeek-Coder-Base 7B, because starting from a code model beats starting from a general one for math. Continue pre-training on the math corpus mixed with code and natural language for 500B tokens total. Then instruction-tune, then run GRPO. For RL the recipe is concrete. Sample 64 outputs per question, set the KL coefficient β to 0.04, the policy learning rate to 1e-6, max length 1024.
The training loop is iterative. Each round freezes a fresh reference, runs many GRPO steps, and continually retrains the reward model on the policy's recent samples using a replay buffer of 10% historical data, so the reward model keeps up as the policy improves.
for iteration = 1..I:
π_ref ← π_θ # freeze a new reference
for step = 1..M:
sample a batch of questions
π_old ← π_θ # the policy the group is sampled from
for each question q:
sample G outputs from π_old
score each output with the reward model → r_1..r_G
Â_i = (r_i - mean(r)) / std(r) # group-relative advantage
for inner = 1..μ:
update π_θ on the clipped GRPO objective with KL to π_ref
retrain the reward model on recent samples (10% replay)There are two flavors of the advantage. Under outcome supervision the reward lands once at the end of an output, and every token in that output shares the one normalized reward as its advantage. Under process supervision a reward lands at the end of each reasoning step, and a token's advantage is the sum of the normalized rewards from that step onward, which gives a finer, step-aware signal. The paper finds process supervision helps.
Results with effect sizes. The base model hits 64.2% on GSM8K and 36.2% on MATH, beating Minerva 540B with 77 times fewer parameters. The instruct model reaches 46.8% on MATH. GRPO then lifts the instruct model to 88.2% on GSM8K and 51.7% on MATH, with out-of-domain gains too, like CMATH rising from 84.6% to 88.8%. Self-consistency over 64 samples pushes MATH to 60.9%. Iterative RL helps most on the first iteration and tapers after. The Maj@K-versus-Pass@K analysis shows RL lifts Maj@K and not Pass@K, pinning the gain to sharper selection rather than new capability.
Limitations and open questions. The model is weak on geometry and theorem-proving, likely a data-selection gap. The RL only used in-domain instruction data and naive nucleus sampling, which the authors tie to the Pass@K result staying flat, so better sampling and out-of-distribution prompts are open work. Reward-model noise is the standing threat, since the policy will exploit any blind spot, and building reliable process reward models that generalize is named as a key future direction.
My assessment
The authors got the important call right twice. The data result, that Common Crawl holds enough math to train a near-frontier math model in the open, reset what people thought a 7B model could do. And GRPO has since become a default for reasoning RL, including the work that followed it, because the critic deletion is the rare simplification that is both cheaper and about as good. The cleanest evidence that they understood their own method is the unified-paradigm section, which shows GRPO, PPO, DPO, and RFT as one gradient with swappable parts. That framing is more durable than any single benchmark number.
Where the paper is most valuable is also where it is most honest. The Maj@K-not-Pass@K finding could have been buried, since it complicates the triumphant story, but the authors put it front and center and drew the right conclusion: this pipeline reranks rather than teaches. That honesty defined the next phase of the field, which went straight at the exploration and Pass@K problem they flagged. The weakest part is the reward-model story. GRPO is only as trustworthy as the scores it chases, and the paper acknowledges 20% label noise in even careful datasets without solving it, which is the soft underbelly every later reward-hacking incident has poked at. None of that dents the core. A group of answers really can be its own judge.