WebArena: A Realistic Web Environment for Building Autonomous Agents
A self-hostable web world plus 812 everyday tasks that score an agent on whether the website actually reached the goal, and the best GPT-4 agent finishes only 14% of what humans finish 78% of.
Read at your level
Start where you're comfortable and climb as far as you like.
- For a 5-year-old
- For a high schooler
- For a college student
- For an industry pro
- For a PhD candidate
- For a peer researcher
Executive summary
People want AI agents that do real chores on the web, like ordering a chair or filing a bug report. The trouble is the tests. Most benchmarks judge an agent by comparing its clicks against one stored answer script, and they run on frozen snapshots of websites, so a correct agent that took a different path gets marked wrong. WebArena builds four full working websites you can host yourself, a shopping site, a forum, a code host, and a content manager, plus a map and other tools, and writes 812 tasks phrased the way a person would phrase them. Then it scores each run by reading the actual website afterward. Did the order really land in the cart? Does the README really list all three museums? That check passes any path that reaches the goal. Under this honest test the best agent, GPT-4 with reasoning, finishes 14.41% of tasks, while people finish 78.24%. The big remaining weakness is that there's a real gap, and the agents fail in dumb ways the paper traces but doesn't fix.
Try it
Load the Valid alternative path preset and step the agent to the end. The functional reward passes, then switch the scoring panel to Surface-form and watch the same correct run fail because its action string differs from the reference. Then load UA hint backfires and drag the seed: about half the seeds make the agent wrongly quit a task it could finish.
A feasible content task run a different but correct way. Watch the functional reward pass while the surface-form metric fails, because the action string no longer matches the reference.
homeclick(search) then type museumsclick(repo link): open the repoclick(Web IDE)type README: Carnegie, Mattress, Warhol
The UA hint tells the agent it may stop if a task looks impossible. It rescues unachievable tasks and trips feasible ones.
Step the agent, change the plan, or flip the UA hint to start the log.
This runs 3 tiny hand-built tasks across a stub of WebArena's shopping, repo, and information sites, where the real benchmark runs 812 tasks over four full self-hosted websites. The functional checks read the world state the actions wrote, exactly as the paper's reward functions do. Runs are deterministic: same preset and same seed produce the same trajectory. “Try another seed” resamples whether the UA hint trips the agent on the current feasible task. The 14.41% headline is GPT-4's end-to-end success rate, against 78.24% for humans.
For a 5-year-old
Imagine you ask a robot to make you a peanut butter sandwich. There are two ways to check if it did a good job.
The first way is to look at the sandwich. Is there bread? Is there peanut butter? Yes? Good robot. It doesn't matter if the robot spread the peanut butter left to right or right to left. The sandwich is what counts.
The second way is silly. You wrote down the exact steps you would use, and you only say "good robot" if the robot did every step in your exact order. If the robot made a perfect sandwich a different way, you say "bad robot" anyway. That's not fair, because the sandwich is fine.
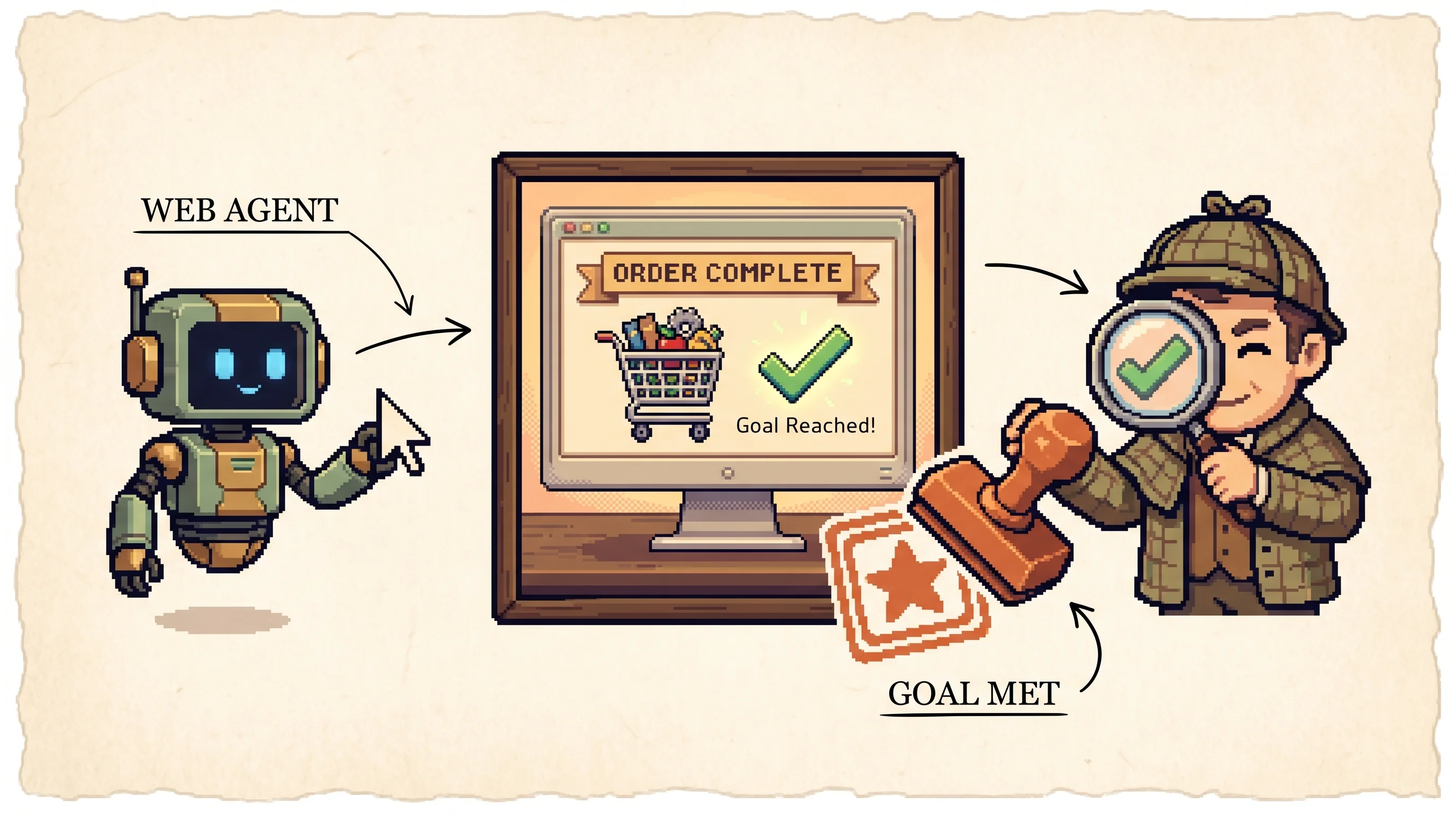
WebArena is a pretend internet where robots do little jobs, like buying a chair or writing a note. It checks the robots the first way. It looks at what really happened. Did the chair end up in the basket? That's all it asks.
Here's the funny part. The robots are not very good yet. A grown-up can finish almost 8 out of 10 jobs. The best robot finishes only about 1 out of 7. Robots have a lot of growing up to do.
For a high schooler
You've used a website to buy something or post a comment. That's a sequence of steps. You click, you type, you click again, and at the end the website changed. The item is in your cart, or your comment is on the page.
Now think about testing a robot that does this for you. The easy, lazy test is to save one correct sequence of clicks and check whether the robot clicked the same things in the same order. People built lots of agent tests this way. Two problems. First, real websites change, so a saved sequence goes stale. Second, and worse, there's usually more than one right way. You can find the cheapest chair by sorting the list or by scrolling and reading. Both are correct, but the lazy test only blesses one.
Here's the one new idea for this section. A functional correctness check ignores the clicks and looks at the result. After the robot finishes, the test reads the website's own memory. Is the chair actually in the cart? Is the file actually saved? If yes, the robot passes, no matter which path it took.
WebArena is a set of four real, working websites you can run on your own computer, plus 812 jobs written in plain English, all graded this fair way. When they tested the strongest AI, GPT-4, it finished 14.41% of the jobs. People finished 78.24%. That gap is the whole point. These are jobs people do every day, and the AI flubs most of them.
For a college student
You should care about this because it's the benchmark that made "can an LLM actually use a website" a measurable question instead of a vibe. Before it, agent benchmarks leaned on two shortcuts that quietly inflated scores. They ran on cached pages or simplified mock sites, and they scored by matching the agent's action sequence against a single reference. Both shortcuts reward the wrong thing.
WebArena fixes both. It ships four fully functional open-source web apps in Docker containers, a shopping site, a Reddit-style forum, a GitLab, and a CMS, populated with real scraped data, plus a map, a calculator, a scratchpad, and a Wikipedia. Because you host it, runs are reproducible and free of CAPTCHAs and live drift. The environment is a deterministic state machine.
E = ⟨S, A, O, T⟩
T : S × A → S (deterministic)S is the website's full state, A is the action space (click an element, type, scroll, switch tabs, navigate a URL, go back), O is what the agent observes (the URL plus the page content as a DOM tree, a screenshot, or an accessibility tree). The agent gets a natural-language intent i, and at each step picks an action from its observation and history. The transition is deterministic, so the same actions on the same start state always produce the same world.
The grading is the contribution. For information-seeking tasks the agent returns an answer â, scored against a reference a* by exact match, must-include, or a fuzzy LLM-judged match. For tasks that change the site, the reward reads the resulting state.
r_func(s_1..s_T) measure end state and intermediate states
r_surface compare action string to the reference scriptWebArena uses r_func. It writes a small program per task that queries the database, calls an API, or runs a JavaScript selector to read the page, then checks the result against the intent. So "post asking whether I need a car in NYC" is verified by locating the latest post, reading its subreddit and body, and checking the URL is /f/nyc and the body contains "a car in NYC". Any path that produces that post passes.
Here's why the distinction bites. Take "buy the ergonomic chair with the best rating." One agent sorts by rating then adds to cart. Another scrolls, reads ratings, and adds the same chair. Both end with the chair in the cart and the checkout page reached. Functional scoring passes both. Surface-form scoring passes only the one whose clicks matched the saved script, and fails the other for the crime of being correct differently. The simulation above makes this concrete. Run the alternative path, watch the functional light go green, then flip to surface-form and watch it go red on the identical correct run.
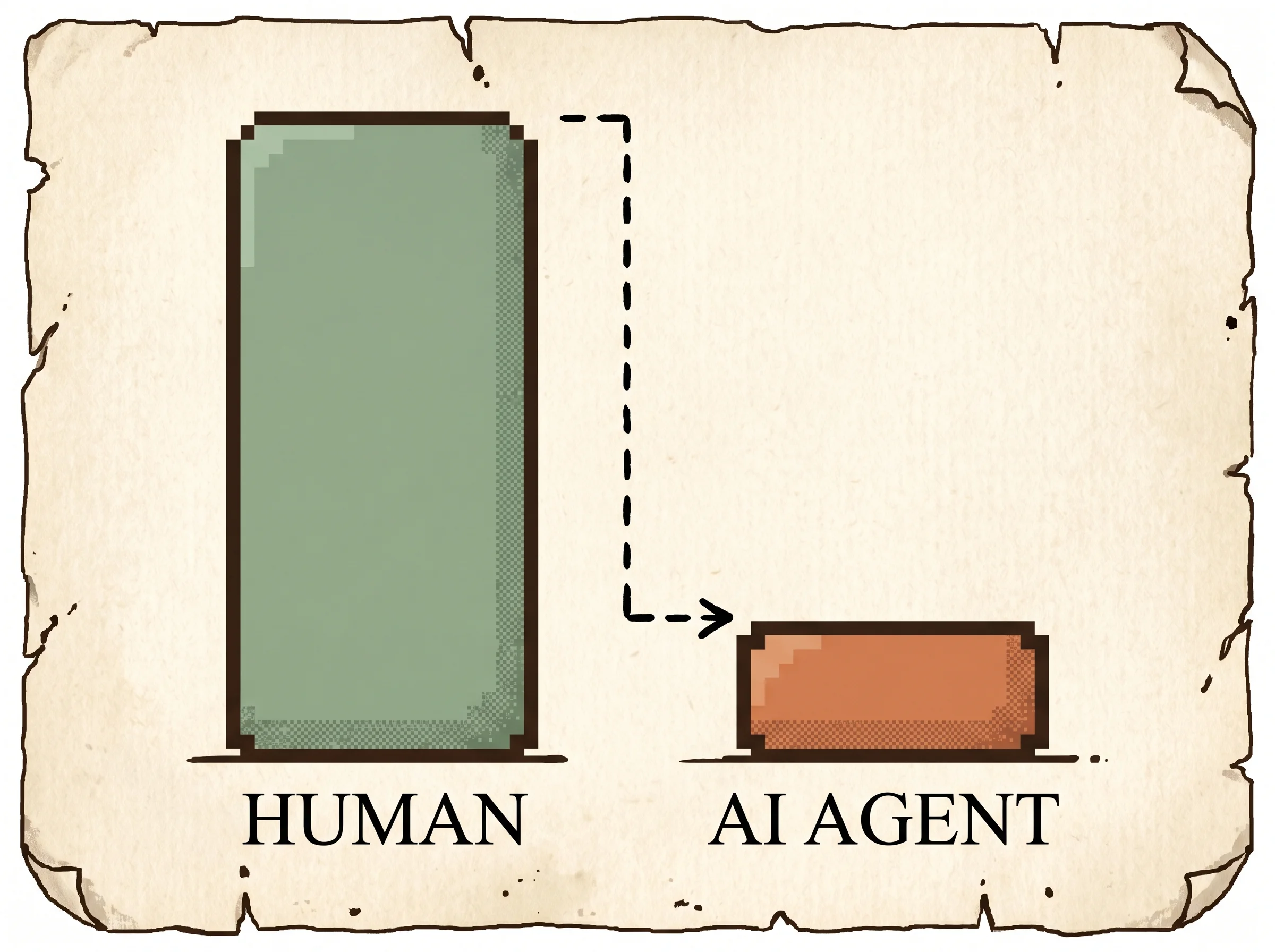
The headline result is a gap. GPT-4 with chain-of-thought reasoning hits 14.41% end-to-end. Humans hit 78.24%. Reasoning before acting helps a little (about 2.34 points over no reasoning). The limitation is that the paper measures the gap precisely and explains some of it, but the agents it tests stay far below useful.
For an industry pro
The problem this solves for you is honest evaluation of web agents before you ship one. If you're judging an agent by string-matching its actions against a golden trajectory, you're both over-penalizing correct alternative paths and over-fitting to stale page layouts. WebArena gives you a self-hosted, reproducible environment and outcome-based scoring, so a passing score means the task actually got done.
Deployment cost is low to stand up and real to use. The four sites plus tools run in Docker, you reset to a deterministic state with provided scripts, and you point your agent at the accessibility tree (compact) or the raw DOM or screenshots, depending on whether your model is text or vision. The scoring programs ship with the tasks, so you're not writing graders. The cost that matters is interpreting results. The accessibility-tree observation keeps context small, but long pages still blow context windows, and the action space uses element IDs so you sidestep coordinate-grounding noise.
The expected reality check is blunt. The best configured agent, GPT-4 with reasoning, finishes 14.41% of tasks end-to-end. That's against 78.24% for humans on the same tasks. The failure modes are the useful part. The biggest one is an instruction artifact. When you tell the agent it may stop on impossible tasks (the unachievable hint), GPT-4 then wrongly declares 54.9% of feasible tasks impossible and quits. Remove the hint and feasible-task success rises, but now the agent hallucinates answers on the genuinely impossible ones. You can't win both with prompt wording alone.

The operating envelope to plan around: short, single-site tasks are the agent's best case; long-horizon tasks that cross sites and require backtracking are where it collapses. If you're building on top of an LLM agent today, treat web automation as assistive with a human checkpoint, not autonomous, and use WebArena to track whether your stack is closing the gap.
For a PhD candidate
The contribution sits at the intersection of three axes that prior benchmarks each compromise on: dynamic interaction, environment realism, and functional-correctness evaluation. MiniWoB++ and WebShop give dynamic interaction but on simplified or synthetic sites. Mind2Web and Form/QAWoB use realistic pages but freeze them as static states and score surface-form action matching. WebArena is the first to hit all three at once, and the gain is methodological, not architectural.
The reward design rewards scrutiny. For state-changing tasks they define r_prog(s), a per-task program that reads intermediate and final states (a database query, an API call, a document.querySelector on the rendered page) and checks the trajectory ends in the intended configuration. This is a genuine advance over trajectory matching because it admits the full equivalence class of correct paths, which is exactly the set that surface-form scoring collapses. The chosen alternative they rejected, comparing to multiple reference trajectories, doesn't scale because the number of valid paths is unbounded. Reading the world is the only metric that generalizes.
The threats to validity are worth naming. The 78.24% human number comes from five CS grad students on a sampled task per template, and 50% of human failures are intent misreadings, so the "human ceiling" is itself soft and partly a task-clarity artifact. The unachievable-task design, borrowed from unanswerable-QA work, interacts badly with prompt wording: the UA hint flips GPT-4 into calling 54.9% of feasible tasks impossible. That's a confound between calibration and capability that the benchmark surfaces but can't separate with prompting alone. And the per-template consistency analysis (Table 3) shows GPT-4 reaches 100% on only 4 of 61 templates, suggesting brittle, non-systematic competence rather than a smooth difficulty gradient.
The follow-up questions the paper opens: how much of the gap is planning versus grounding versus failure recovery; whether memory and search-based planning (it points at backtracking and skill reuse) move the number; and whether the accessibility-tree observation discards signal that a screenshot model could exploit. These became the next two years of web-agent work.
For a peer researcher
The delta against Mind2Web and the WoB lineage is that evaluation stops trusting the trajectory and starts reading the world. Mind2Web scores action overlap against a reference on static pages; WebShop is functional but synthetic; WebArena is functional and realistic and interactive at once. The reward r_prog over s_1..s_T is the move, because it scores the equivalence class of correct executions rather than one privileged path, which is the only definition that survives the unbounded branching of real web tasks.
The design choices read as deliberate tradeoffs. Element-ID-based actions over raw coordinates trade away vision-grounding realism for a clean n-way classification that makes cross-agent comparison fair on step count. The accessibility-tree observation trades visual fidelity for compactness so text models fit the context. Deterministic Docker hosting trades live-web authenticity for reproducibility, which is the right call given the benchmark's purpose.
What would change my read of the headline. The 14.41% is one prompt regime away from a different story: the UA hint costs feasible-task accuracy by inducing a 54.9% false-impossible rate, so the gap conflates capability with prompt-induced miscalibration. If a calibration fix recovered most of those feasible tasks without re-introducing hallucination on the impossible ones, the capability gap would look smaller than 14-to-78 suggests. The honest soft spot is the human baseline itself, five annotators with 50% of failures from intent misreading, which makes 78.24% a noisy ceiling. The open problem the paper plants, and where the field went, is failure recovery and search-based planning rather than single-shot action prediction.
How it works
The problem and why prior approaches failed. People want agents that follow a plain-English request and carry it out on the web. To know if an agent works, you need a fair test. Prior tests failed two ways. They simplified the environment, running on cached pages or mock sites that miss real-world complexity, so an agent that passes there may flop on a live site. And they graded by surface form, comparing the agent's action sequence to one stored reference. That penalizes any correct alternative path and rewards memorizing trajectories instead of accomplishing goals.
The key idea. Build a real, reproducible web environment and grade by functional correctness. Run four full open-source web apps with real data, give the agent natural-language intents, let it act, and afterward read the website's actual state to decide if the task got done. The environment is deterministic, so runs reproduce.
Methodology. The environment is a state machine E = ⟨S, A, O, T⟩ with deterministic transition T : S × A → S. The agent observes the URL, open tabs, and page content (DOM, screenshot, or accessibility tree), and acts in a compound space that mirrors a keyboard and mouse.
element ops: click(elem), hover(elem), type(elem, text), press(key), scroll(dir)
tab ops: tab_focus(i), new_tab, tab_close
navigation: goto(url), go_back, go_forwardElements are addressed by an ID prepended during a DOM or accessibility-tree traversal, so click [1582] clicks the element labeled [1582] Add to Cart. That turns element selection into a clean classification problem and removes coordinate ambiguity.
Tasks come from 241 templates instantiated into 812 intents, written to be high-level (more than one or two actions), creative (with constraints that make them unique), and parameterized so the same template yields several distinct execution traces. They split into information-seeking, site navigation, and content-and-config, plus deliberately unachievable tasks (the site genuinely lacks the data), where the correct answer is N/A.
Scoring has two families. For answers, r_info(â, a*) uses exact match, must-include, or a fuzzy LLM-judged match. For state changes, r_prog(s) runs a per-task program that reads the resulting world and checks the intended properties hold.
# r_prog for "post asking whether I need a car in NYC"
url = locate_latest_post_url(s)
body = locate_latest_post_body(s)
pass = must_include(url, "/f/nyc") and must_include(body, "a car in NYC")In the simulation, the functional checks listed in the scoring panel are exactly these state reads, run against the world the agent's actions produced.
Results with effect sizes. GPT-4 with chain-of-thought reasoning reaches 14.41% end-to-end success without the unachievable hint, against 78.24% for humans. Reasoning adds about 2.34 points over direct action prediction. GPT-3.5 trails far behind (around 6%), and the older text-bison model underperforms GPT-3.5 at 5.05%. With the UA hint on, GPT-4 wrongly labels 54.9% of feasible tasks impossible, which is why removing the hint raises feasible-task success but loses the ability to correctly answer N/A on the genuinely impossible ones. Across 61 templates, GPT-4 reaches 100% success on only 4, and GPT-3.5 on none, so competence is brittle even within a template.
Limitations and open questions. The human baseline rests on five annotators with half their failures from misreading the intent, so 78.24% is a soft ceiling. The UA-hint effect tangles calibration with capability. And the paper measures the gap and dissects the failures (early stopping, hallucination, repeated invalid actions, step-limit exhaustion) but leaves the fixes, memory, search-based planning, and failure recovery, as future work.
My assessment
The authors got the most important call right, and it's a methods call, not a model. Scoring by reading the world instead of matching the trajectory is the correct definition of success for open-ended tasks, because the set of correct paths is unbounded and only the outcome is well-defined. That single choice is why the benchmark aged well while trajectory-matching benchmarks didn't, and it's the reason a passing WebArena score means something.
The honest reporting is the other thing they got right. A weaker paper would have buried the UA-hint artifact. Instead they ran the ablation, showed that telling GPT-4 it may give up makes it wrongly quit 54.9% of feasible tasks, and named it as a confound. That single finding is more useful than the headline number, because it says the gap is partly miscalibration, not pure incapability, and points at where prompting hits its ceiling.
Where the work is thin is the human baseline and the breadth of agents. Five grad students with half their errors from intent misreading make 78.24% a noisy ceiling, and the agents tested are all few-shot prompted LLMs with no memory, no search, and no real failure recovery, so the 14.41% measures the floor of the era more than the limit of the approach. The paper knows this and says so. History agreed with the framing: WebArena became the standard web-agent testbed, and the next wave of work, memory, backtracking, and search-based planning, went straight at the failure modes it catalogued.