Attention Is All You Need
A model that reads every word in a sentence at the same time by letting each word weigh every other word, replacing the slow step-by-step reading that came before.
Read at your level
Start where you're comfortable and climb as far as you like.
- For a 5-year-old
- For a high schooler
- For a college student
- For an industry pro
- For a PhD candidate
- For a peer researcher
Executive summary
Before this paper, the best translation models read a sentence one word at a time, passing a running summary forward like a game of telephone. That made them slow to train and forgetful across long distances. The Transformer throws out the step-by-step reading. Instead every word looks at every other word in one shot and decides how much each one matters, a trick called attention. Because the words no longer wait in line, the whole sentence runs through the model in parallel. The model trained faster and still beat the old state of the art, hitting 28.4 BLEU on English-to-German translation and 41.8 on English-to-French. The cost is that attention compares every word to every other word, so the work grows with the square of the sentence length, which gets expensive for very long inputs.
Try it
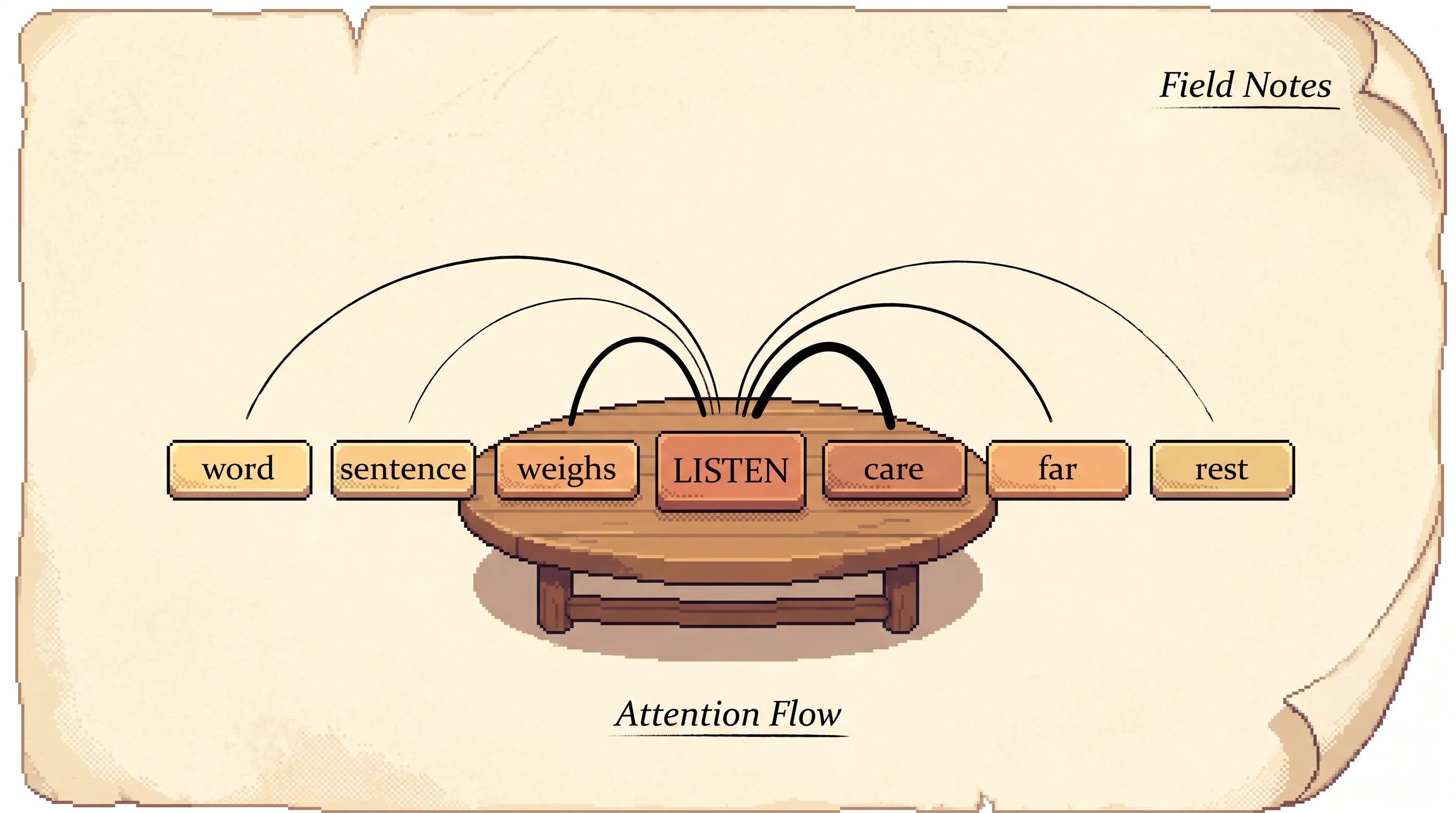
Load the Meaning preset, then step the query until it lands on the word it. Watch the weight jump to animal, the right answer, instead of the closer word street. Then load Softmax saturation, turn the scaling off, and watch the weight pile onto one word. Flip scaling back on and the other words come back to life.
The meaning head, scaling on. Step the query to 'it' and watch the weight land on 'animal', not the nearer 'street'.
Pronouns reach for an animate noun, verbs reach for their noun arguments, states reach for their subject.
| word | score | logit | weight |
|---|---|---|---|
| The | 0.00 | 0.00 | 5% |
| animal | 1.00 | 2.50 | 55% |
| didn't | 0.00 | 0.00 | 5% |
| cross | 0.00 | 0.00 | 5% |
| the | 0.00 | 0.00 | 5% |
| street | 0.00 | 0.00 | 5% |
| because | 0.00 | 0.00 | 5% |
| it | 0.00 | 0.00 | 5% |
| was | 0.00 | 0.00 | 5% |
| too | 0.00 | 0.00 | 5% |
| tired | 0.00 | 0.00 | 5% |
Step, click a word, or flip a control to start the log.
The attention math is exactly equation 1: softmax(Q·K / sqrt(dk))·V. Word vectors and per-head projections are hand-set so the patterns are legible; a trained model learns those numbers from data. The run is fully deterministic — same preset always produces the same weights. This shows 3 illustrative heads over 11words; the paper's base model runs 8 heads of width 64 over thousands of tokens.
For a 5-year-old
For someone brand new to all of this.
Imagine a class of kids sitting in a circle. The teacher reads a sentence out loud. "The puppy ran because it was happy." Now one kid has to figure out what the word "it" means. So that kid looks around the circle at every other kid at once. The kid looks hardest at the kid holding the word "puppy", because that's what "it" is talking about. The kid barely looks at the word "because".
That looking is the whole idea. Every word looks at every other word and decides who to look at hardest.
The old way was different. The old way was a whisper game. One kid whispers to the next, who whispers to the next, all the way down the line. By the end the message gets fuzzy and the first kid is far away. The new way skips the line. Everybody hears everybody at the same time, so nobody is ever far away.
Real words don't have eyes and they don't really look. The looking is math with numbers, where each word gets a score for every other word and the biggest score wins. But the feeling is the same. Everyone pays attention to everyone, all at once.
For a high schooler
If you've seen a bit of algebra and used a phone keyboard.
Your phone finishes your sentences. You type "see you" and it offers "later". It guesses the next word from the words you already typed. Models that do this used to read your words in order, one at a time, keeping a little memory that they updated at each step. The problem is that the memory blurs. By the time the model reaches the end of a long sentence, the start has faded.
Attention fixes the fading. Here's the one new word for this section. A query is the question one word asks, like "which earlier word do I depend on?" Every other word holds a key, which is like a name tag, and a value, which is the information it can hand over. The asking word compares its query against every key, gets a match score for each, and turns those scores into a set of weights that add up to one. Then it pulls back a blend of the values, leaning toward the words with the highest weights.
Here's a worked example with tiny numbers. Say the word "it" gives match scores of 9 to "animal", 1 to "street", and 0 to everything else. Run those through the weighting step and "animal" gets about 87 percent of the attention, "street" gets about 12 percent, and the rest split the crumbs. The word "it" walks away mostly carrying the meaning of "animal". That's how the model knows what "it" refers to.
Because every word does this on its own, they can all do it at the same time instead of waiting in a line.
For a college student
Assumes calculus, basic linear algebra, and a little machine learning.
You should care about this because nearly every large language model today is a Transformer, and this is the paper that defined it. The motivation was speed. Recurrent networks process token t only after token t-1, so a sentence of length n needs n sequential steps. You can't parallelize across positions inside one example, which wastes the hardware. The authors asked whether attention alone, with no recurrence, could relate any two positions in a constant number of steps. It can.
The mechanism is scaled dot-product attention. Pack the queries, keys, and values into matrices Q, K, and V. Each row is one token's vector of dimension d_k (for queries and keys) or d_v (for values).
Attention(Q, K, V) = softmax( Q Kᵀ / sqrt(d_k) ) VRead it left to right. Q Kᵀ is every query dotted with every key, which gives an n by n grid of raw match scores. Dividing by sqrt(d_k) is the scaling step, and it matters more than it looks. Then softmax turns each row of scores into weights that sum to one. Multiplying by V replaces each token with a weighted blend of all the value vectors.
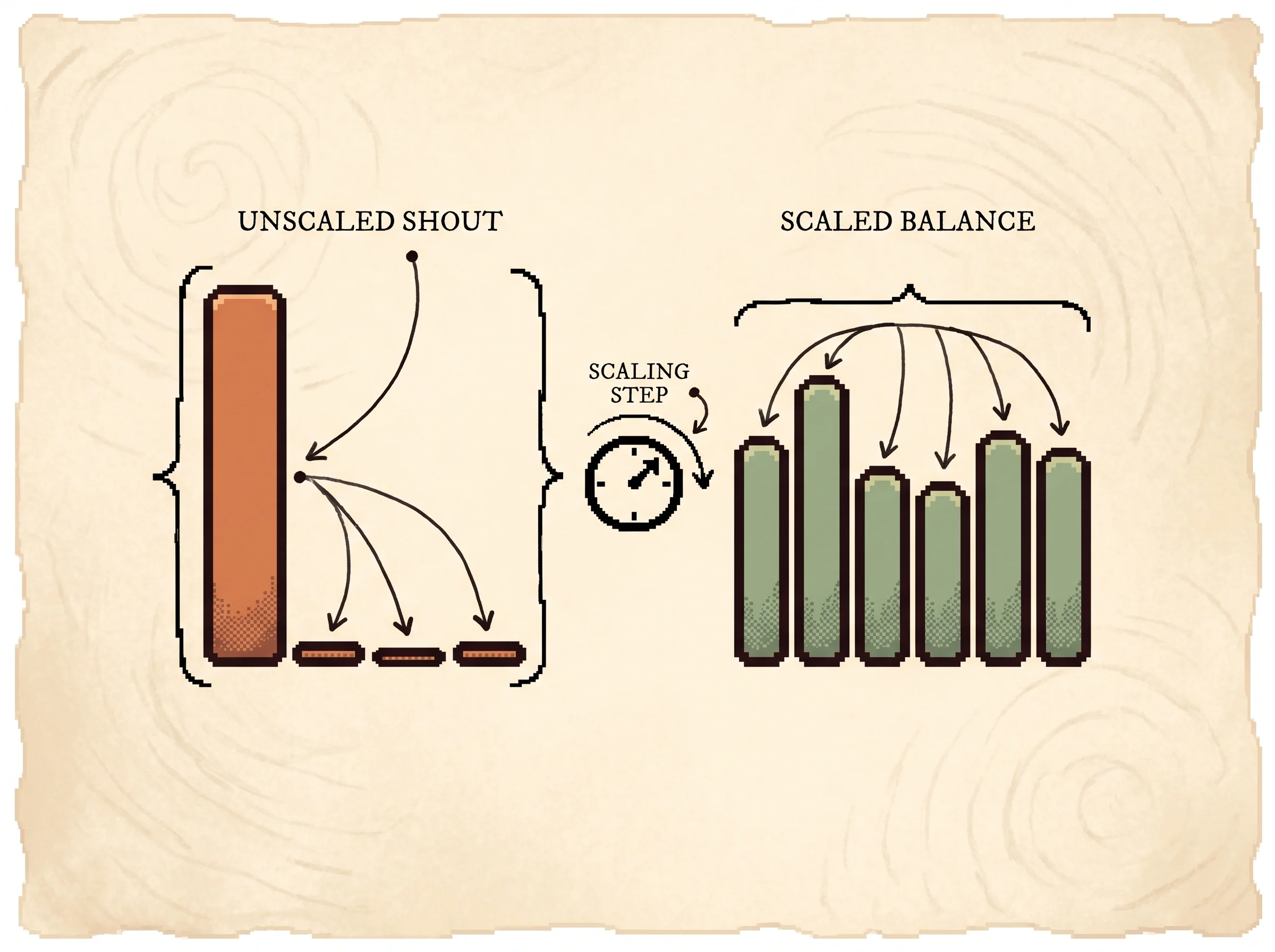
Why divide by sqrt(d_k)? If the query and key components are independent with mean 0 and variance 1, their dot product has mean 0 and variance d_k. So as d_k grows, the raw scores swing wider. Feed wide scores into softmax and it saturates, meaning almost all the weight lands on the single largest score and the gradient there goes nearly flat. Dividing by sqrt(d_k) rescales the variance back to 1 and keeps the weights spread out enough to learn from. The simulation above makes this concrete. Crank the score magnitude with scaling off and one bar swallows the rest. Turn scaling on and the distribution breathes again.
One worked path, end to end. Take "The animal didn't cross the street because it was too tired." The query for "it" matches the key for "animal" far better than the key for "street", so after softmax the output for "it" is mostly the value of "animal". The model has resolved the pronoun, and it did so by comparing "it" against all eleven words at once, not by walking back word by word.
The limitation falls straight out of the n by n grid. Memory and compute scale with n². For a paragraph that's fine. For a whole book it hurts, which is why later work spends so much effort making attention cheaper.
For an industry pro
What it solves, what it costs, and where it breaks.
The problem it solves for you is throughput during training. Recurrent models force a sequential dependency down the length of every sequence, so your GPUs sit idle waiting for step t-1 to finish. The Transformer removes that dependency inside the attention layer. Every position computes at once, so you saturate the hardware and finish sooner. The paper's base model trained in about 12 hours on 8 P100 GPUs and still beat models that cost an order of magnitude more compute.
Deployment cost has two faces. Training parallelizes beautifully, which is the headline win. Inference for generation does not, because the decoder still produces tokens one at a time, each one attending over everything written so far. And attention is quadratic in sequence length, so doubling the context roughly quadruples the attention cost. Budget for that when you size context windows.
The expected improvement over a recurrent baseline is real and not marginal. More than 2 BLEU over the previous best on English-to-German, at a fraction of the training cost. The failure mode to plan around is long inputs. The quadratic cost means very long documents either blow your memory or force you into one of the approximate-attention variants, which trade exactness for length. If your sequences are short to medium, you get the speed and quality with no asterisk.
For a PhD candidate
Assumes fluency with sequence models and the surrounding literature.
The contribution is dispensing with recurrence and convolution entirely and showing that self-attention alone suffices for state-of-the-art sequence transduction. Prior attention work, from Bahdanau onward, bolted attention onto a recurrent backbone. ByteNet and ConvS2S replaced recurrence with convolution but still paid a path length that grows with distance, linearly for ConvS2S and logarithmically for ByteNet. The Transformer's self-attention connects any two positions in O(1) sequential operations and O(1) path length, which is the crux of the Table 1 comparison and the reason long-range dependencies become easier to learn.
The methodological choices reward scrutiny. Multi-head attention exists because a single softmax-weighted average blurs together everything it attends to, so the authors project into h = 8 subspaces, attend in each, and concatenate. The ablation in Table 3 shows single-head is 0.9 BLEU worse, and too many heads also hurts, so there's a real sweet spot. Scaled dot-product over additive attention is a speed choice that depends on the sqrt(d_k) correction to stay trainable at scale. The sinusoidal positional encoding is a parameter-free way to inject order, and they show learned positional embeddings score nearly the same, so the choice rests on the hope of extrapolating to longer sequences rather than on a measured gain.
Threats to validity worth probing. The headline gains live on two WMT translation tasks plus one parsing task, all relatively short-sequence. The quadratic cost is acknowledged but not stressed against long-context tasks in this paper. And the claim that heads specialize into interpretable roles rests on a handful of attention visualizations, which is suggestive rather than systematic. The obvious follow-ups, most of which the field then chased, are cheaper attention for long sequences, what each head actually learns, and whether the encoder-decoder framing is even needed or whether a decoder-only stack does the job.
For a peer researcher
A horizontal conversation, delta first.
The delta against Bahdanau-style attention and against ConvS2S is that attention stops being an add-on and becomes the whole network. Strip the recurrence, strip the convolution, keep self-attention and position-wise feed-forward layers, add residuals and layer norm, and that's the model. The payoff is constant path length between any two tokens and full parallelism across positions, which the recurrent and convolutional families can't both have at once.
The choices read as deliberate tradeoffs rather than universal truths. Scaled dot-product trades the slight quality edge additive attention has at large d_k for matrix-multiply speed, and buys back the trainability with the sqrt(d_k) divisor. Multi-head trades a little per-head dimensionality for the ability to attend to several relationships at once, which the single-head ablation says is worth roughly a BLEU point. Sinusoidal positions trade a measured gain (there isn't one over learned embeddings) for a shot at length extrapolation.
What would change my mind on the central claim. If a recurrent or convolutional model matched both the training throughput and the quality at the same compute budget, the "attention is all you need" framing would weaken. It didn't happen. The quadratic cost is the honest soft spot, and the open question this paper leaves wide open, restricting attention to a neighborhood of size r to handle long inputs, is exactly where the next several years of work went.
How it works
The problem and why prior approaches failed. Sequence transduction means turning one sequence into another, like a sentence in English into German. The strong models were recurrent. They read left to right, carrying a hidden state h_t computed from h_{t-1} and the current token. That recurrence is the bottleneck. It forces n sequential steps for a length-n sequence, so positions can't compute in parallel, and it makes distant words hard to connect because their signal has to survive many steps of being overwritten. Convolutional models like ConvS2S and ByteNet parallelize but still need many layers to connect far-apart positions.
The key idea. Replace recurrence with self-attention, where every position attends to every other position in the same layer. The path between any two tokens is now one hop, and all positions compute at once. Stack these layers and you get the Transformer.
Methodology. The model is an encoder-decoder, each a stack of N = 6 identical layers, with d_model = 512. An encoder layer has two sub-layers, multi-head self-attention then a position-wise feed-forward network, each wrapped in a residual connection and layer norm.
LayerNorm(x + Sublayer(x))The decoder adds a third sub-layer that attends over the encoder's output, and it masks its own self-attention so position i can only see positions up to i. That mask is what keeps generation honest, since a word can't peek at the future it hasn't produced yet. Load the Causal mask preset in the simulation to see the weights snap into a triangle.
The attention itself is equation 1 from earlier, run in parallel across h = 8 heads.
MultiHead(Q, K, V) = Concat(head₁, ..., head₈) Wᴼ
head_i = Attention(Q Wᵢ_Q, K Wᵢ_K, V Wᵢ_V)Each head gets its own learned projections into a d_k = d_v = 64 subspace, attends there, and the eight results are concatenated and projected back. Different heads end up doing different jobs.
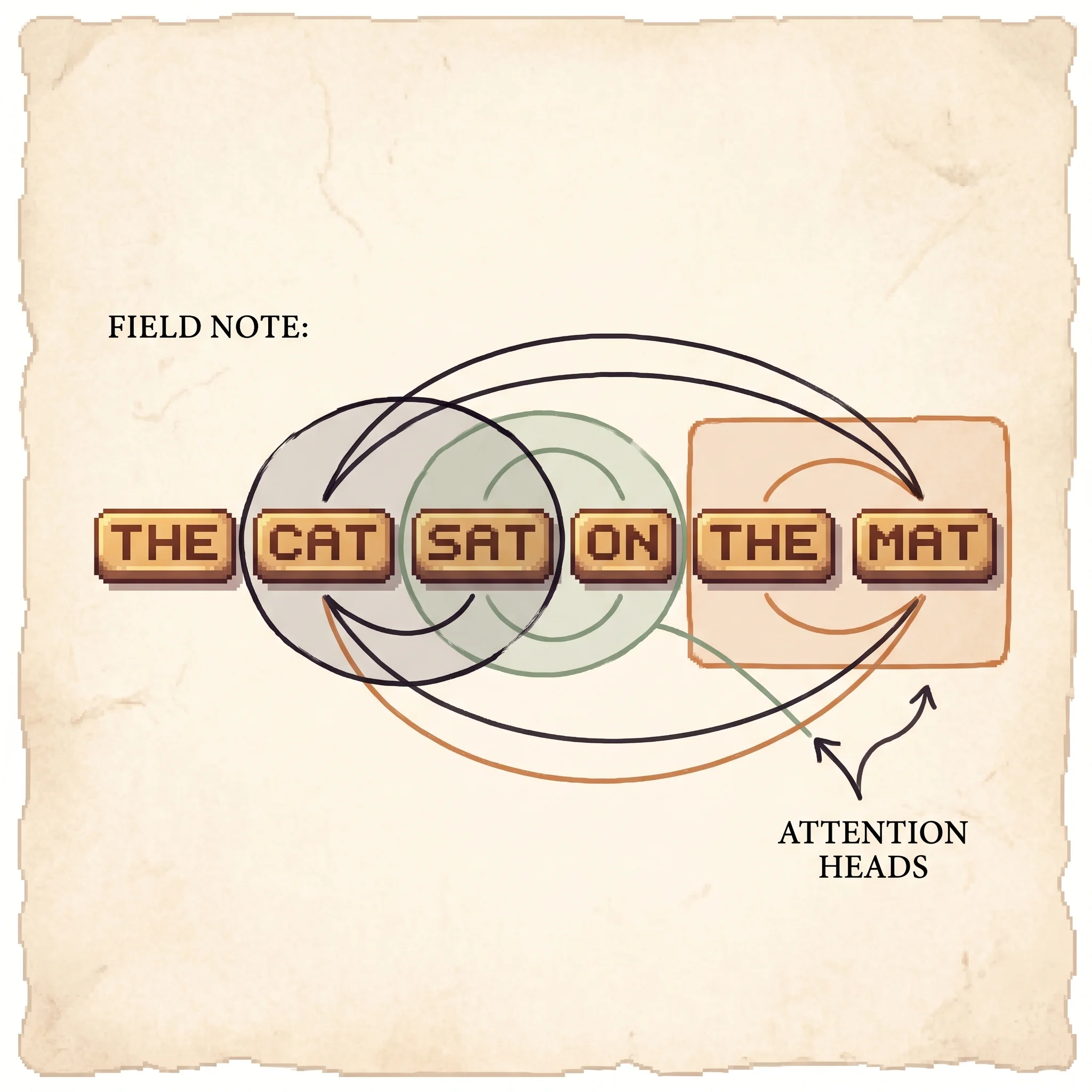
In the simulation, switch between the Meaning and Neighbors heads on the same sentence. One head links a pronoun to its noun. The other leans on whichever words sit physically close, and it does that just by reading the position stamp, with nobody teaching it to.
That position stamp is the last piece. With no recurrence and no convolution, the model has no built-in sense of word order, so the authors add a positional encoding to each input. They use sines and cosines of different frequencies.
PE(pos, 2i) = sin(pos / 10000^(2i/d_model))
PE(pos, 2i+1) = cos(pos / 10000^(2i/d_model))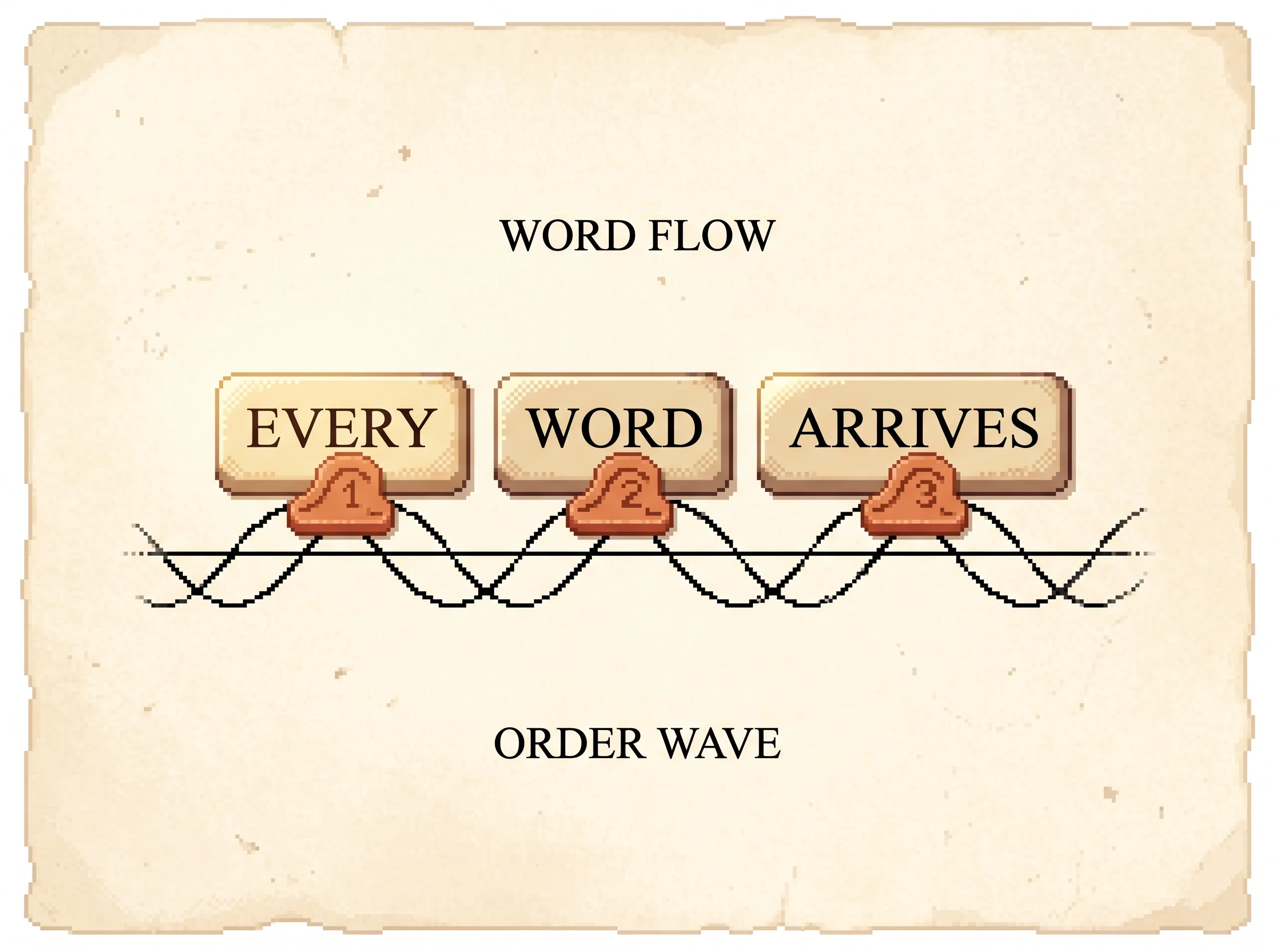
Each position gets a unique fingerprint of wave values, and because nearby positions have similar fingerprints, the model can learn to attend by relative position. The neighbor head in the simulation runs on exactly this signal.
Results with effect sizes. On WMT 2014 English-to-German the big Transformer scored 28.4 BLEU, more than 2 BLEU over the best prior result including ensembles. On English-to-French it set a new single-model state of the art at 41.8 BLEU after 3.5 days on 8 GPUs, a small fraction of the compute earlier models burned. The base model trained in 12 hours and still beat all previously published single models. On English constituency parsing, a task far from translation, a 4-layer Transformer hit 91.3 F1 trained only on the 40K-sentence WSJ set, beating models built for that task.
Limitations and open questions. Self-attention costs O(n² · d) per layer, so it's faster than recurrence only while n stays below d, and it gets expensive for long sequences. The authors float restricting attention to a neighborhood of size r to bring that down, and leave it as future work. They also note the interpretability of heads is observed, not proven.
My assessment
The authors got the big call right, and history has been blunt about it. Nearly every frontier language model since is a Transformer, mostly a decoder-only descendant of this one. The two ideas that carried the most weight were the cheap ones. Scaled dot-product attention is almost trivial to implement on a GPU, and the sqrt(d_k) divisor, a single line, is what kept it trainable as models grew. Multi-head attention earned its keep too, and the ablations are honest about the sweet spot rather than overselling more heads.
Where the paper undersold its own work is telling. The framing is all machine translation, and the title is a translation flex, yet the real prize turned out to be that this architecture scales with data and compute better than anything before it. The authors couldn't have known that from two WMT tasks, so it's less a miss than a limit of what the evidence then showed. The honest soft spot they named, the quadratic cost, defined the next decade of research, from sparse and linear attention to FlashAttention's exact-but-memory-aware rewrite. The positional encoding was the weakest brick, sinusoids with no measured edge over learned embeddings, and the field has since churned through rotary and relative schemes. None of that dents the core. Attention really was most of what you needed.