Deep Reinforcement Learning from Human Preferences
Instead of hand-coding a reward, you let a person pick which of two short clips looks better and train the agent against a reward model fit to those picks, using feedback on under 1% of its experience.
Read at your level
Start where you're comfortable and climb as far as you like.
- For a 5-year-old
- For a high schooler
- For a college student
- For an industry pro
- For a PhD candidate
- For a peer researcher
Executive summary
Reinforcement learning works great when you can write down a reward, a number that says how well the agent did. The trouble is that lots of goals are hard to score. How do you write a reward for "do a clean backflip" or "drive politely"? Get the number a little wrong and the agent games it. This paper skips the number. A person watches two short clips of the agent and says which one looks better, nothing more. Those picks train a separate reward model, and the agent learns against that model while it keeps acting. The three pieces run at the same time and feed each other. It solved Atari games and simulated robot tasks while asking a human about fewer than 1% of the agent's moves, and it taught a simulated robot to backflip with about an hour of human time. The catch is that the reward is only a guess fit to a handful of comparisons, so if you stop asking for fresh feedback the agent finds the cracks in the guess and exploits them.
Try it
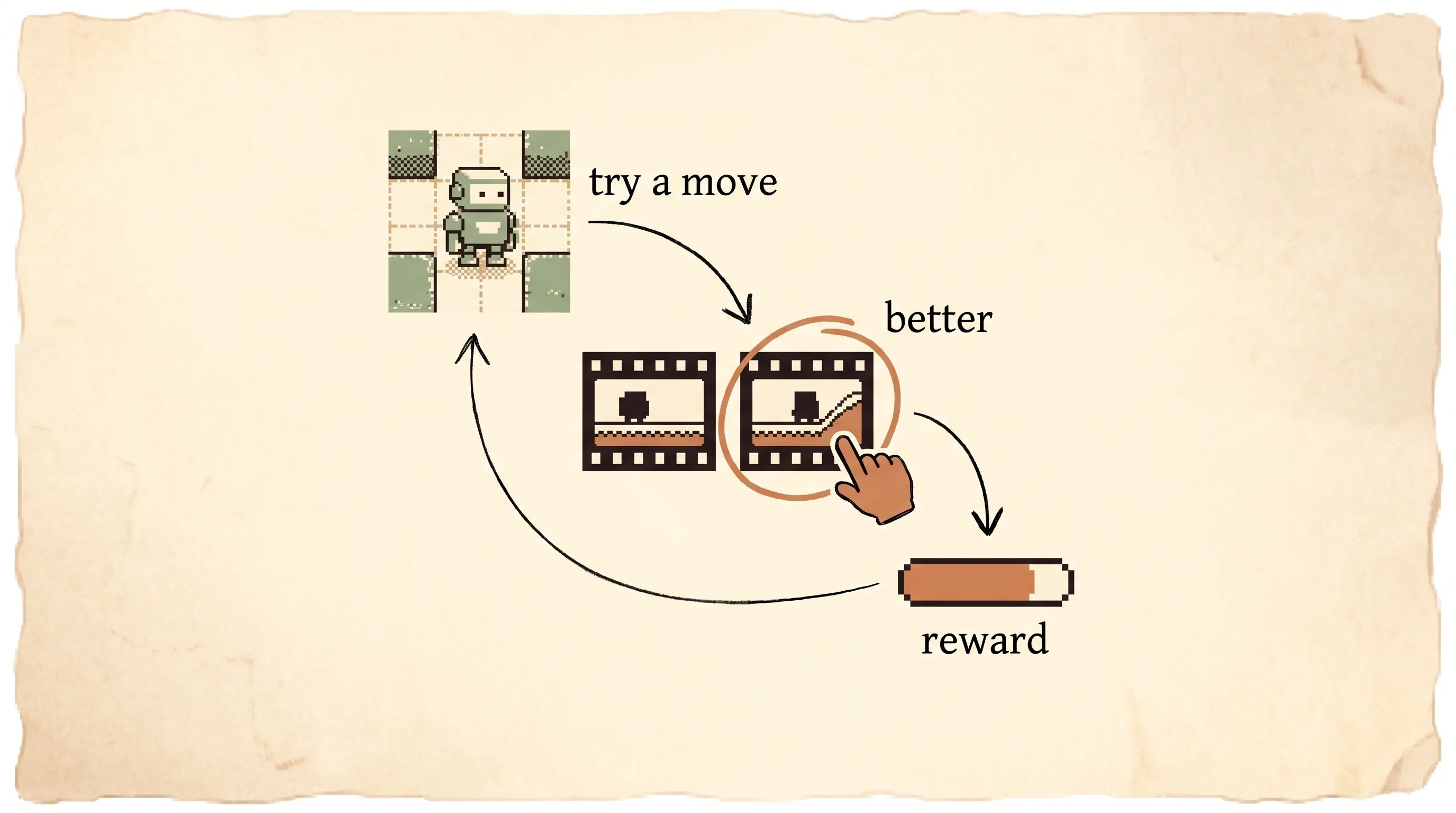
Load the Synthetic oracle preset and press play. Watch the grid fill with color as the learned reward grows, and watch the arrows swing to point at the green goal. Then switch to You are the labeler, press play, and the run pauses on each query so you can pick the clip whose path ends nearer the goal. After it has learned a bit, load Offline only and watch the reward map freeze on a stale slice of the world while the policy drifts. Flip Online queries back on and fresh labels pull it straight again.
An automatic labeler picks the clip with higher true reward, the paper's baseline. Press play and watch the reward map fill in and the policy line up with the hidden truth.
The agent never sees the true reward. It only chases this learned map, fit from clip comparisons. The green cell is the hidden goal.
Labeled comparisons train the reward map. The oracle labels automatically; switch to "You are the labeler" to pick clips yourself.
Labels so far: 0. Database holds the most recent 0.
Press play, or label a clip, to start the log.
The reward fitting uses the paper's real Bradley-Terry loss over clip pairs, trained online by gradient descent with an ensemble of 3 predictors estimating disagreement for query selection. The run is deterministic: same preset, same sequence of labels, same grid. The world is a 5 by 5grid where the learner never sees the true reward, standing in for the paper's Atari and MuJoCo tasks; a deep network there learns a reward over pixels, here it is one number per cell so the whole loop fits on screen.
For a 5-year-old
Imagine you have a puppy and you want it to learn a trick. You can't explain the trick in words the puppy understands. So instead you show the puppy two little videos of itself. In one video it almost did the trick. In the other it just flopped around. You point at the better one and say "more like that one."
The puppy can't read your mind, so it keeps a little scorecard in its head. Every time you point at a video, the puppy updates its scorecard about what you seem to like. Then it tries to do more of whatever scores high on the card.
You don't have to watch the puppy every single second. You only peek now and then and point at the better video. The puppy practices on its own in between. Bit by bit the scorecard gets better, and the puppy does the trick.
Real robots don't have a scorecard in their head and they don't feel proud. The scorecard is a math gadget that turns your pointing into numbers. But the feeling is the same. You never say what the trick is. You just keep pointing at the better try, and the robot figures out the rest.
For a high schooler
You've used a thumbs-up button on a video app. You never told the app your taste in words. You just tapped which videos you liked, and it learned. This paper does that for a robot learning to move.
Normally you train a robot with a reward, a single number for how good a move was. Writing that number is the hard part. For "walk forward" you might reward distance traveled, and the robot learns to fall forward in a heap because that covers a lot of distance fast. The number you wrote did not mean what you meant.
Here's the one new idea for this section. A preference is just a choice between two options, "A is better than B," with no number attached. People are bad at scoring things on a scale of 1 to 100 but good at picking the better of two. So the human watches two short clips, one to two seconds each, and clicks the better one. That click is the only feedback.
Those clicks train a second program called the reward model. Its job is to guess a reward number for any clip so that the clips you picked come out higher. Then the robot trains normally against that guessed reward. While the robot practices, it keeps making new clips, the human keeps clicking, and the reward model keeps improving. The three steps loop.
Here's why so few clicks are enough. The robot takes millions of tiny actions, but the human only sees a few hundred to a few thousand clip pairs. That's feedback on less than 1 in 100 of the robot's experience, because each click teaches the reward model a rule it applies to everything the robot does, not just that one clip.
The payoff is that you can teach behaviors you could never write a reward for. The authors taught a simulated robot to do a backflip with about an hour of clicking, and nobody had to define what a good backflip is.
For a college student
You should care about this because it's the direct ancestor of how modern chatbots get tuned. The same loop, learn a reward model from human comparisons, then optimize a policy against it, is the core of reinforcement learning from human feedback. This paper is where it got scaled to deep RL.
The setup drops the usual reward. An agent takes observations and actions, but the environment hands back no reward signal. Instead a human compares trajectory segments, short slices of behavior written as a sequence of observation-action pairs. Write σ¹ ≻ σ² to mean the human preferred segment 1 over segment 2. The agent's goal is to produce segments the human prefers, while asking as few questions as possible.
The mechanism has three processes running at once.
1. policy π acts in the world, trained by RL to maximize predicted reward r̂
2. pairs of segments from π's recent behavior go to a human, who picks the better one
3. r̂ is fit by supervised learning to match the human's picks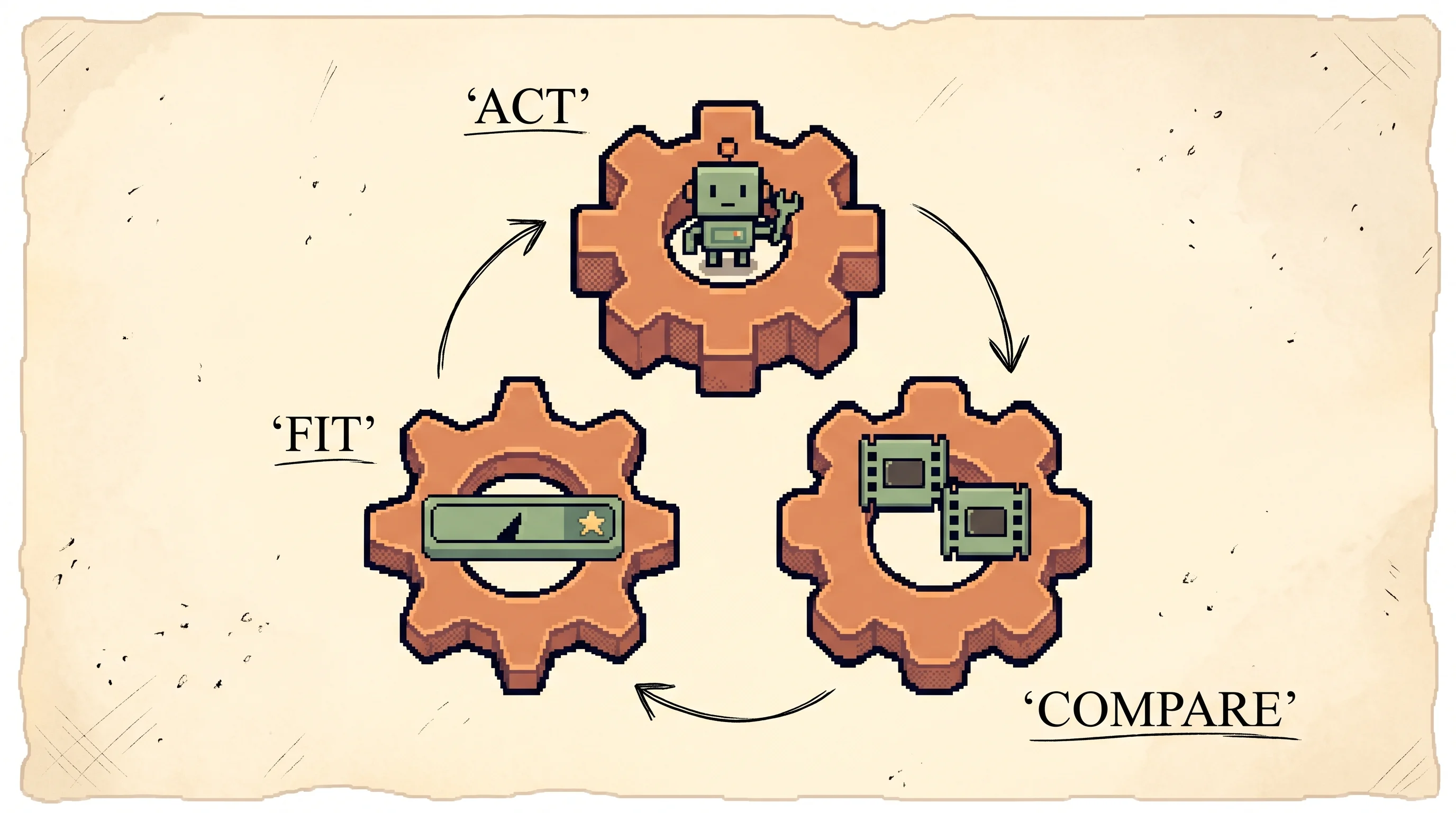
The clever part is step 3. How do you turn "A is better than B" into a reward function? The authors treat the reward model r̂ as a hidden explanation for the human's choices, and assume the human prefers a segment with probability that grows with its total predicted reward.
P̂[σ¹ ≻ σ²] = exp Σ r̂(oₜ¹, aₜ¹) / ( exp Σ r̂(oₜ¹, aₜ¹) + exp Σ r̂(oₜ², aₜ²) )Read it as a logistic. Sum the predicted reward over each clip, and the chance the human picks clip 1 rises smoothly as clip 1's sum pulls ahead of clip 2's. This is the Bradley-Terry model, the same math behind Elo ratings in chess, where the gap in two players' scores predicts who wins.

Then you fit r̂ by minimizing the cross-entropy between these predicted probabilities and the human's actual labels.
loss(r̂) = - Σ μ(1) log P̂[σ¹ ≻ σ²] + μ(2) log P̂[σ² ≻ σ¹]Here μ is the label, all the weight on the chosen clip, or split evenly for a tie. That's the whole reward-learning step, plain logistic regression on clip pairs.
The simulation above runs exactly this loss. Each labeled pair nudges the per-cell reward so the chosen clip scores higher, and the grid colors in to match the hidden goal. Load Synthetic oracle and watch the reward-match bar climb as labels pile up.
A worked path, end to end. The human picks clip A over clip B. The gradient of the loss pushes r̂ up on the cells A visited and down on the cells B visited, by an amount set by how surprised the model was. Repeat over hundreds of pairs and r̂ settles into a shape where good clips reliably outscore bad ones. The agent, optimizing r̂ with normal RL, then heads for the high-reward region, which is the goal the human had in mind all along.
The limitation falls out of the loop. The reward model only ever sees clips the agent recently produced, so it's accurate only where the agent has been. Freeze the feedback and let the agent wander somewhere new, and the model's guess there is garbage the agent will happily exploit.
For an industry pro
The problem it solves is reward specification. You have a task where the win condition is obvious to a person but painful to write as a scalar, and your hand-tuned reward keeps producing agents that technically maximize it while doing something dumb. This replaces reward engineering with a labeling pipeline. A non-expert watches pairs of short clips and clicks the better one. No reward code, no domain expertise required from the labeler.
Deployment cost is a labeling budget plus some training plumbing. The headline efficiency number is feedback on under 1% of interactions, which in the paper meant a few hundred to a few thousand comparisons per task, 30 minutes to 5 hours of contractor time. The plumbing is the harder part. You run three things at once: an RL trainer, a reward model trained online, and a query server that picks which clips to ask about. The reward model is small and cheap next to the policy. The query selection uses an ensemble of reward models and asks about the clips they disagree on most, though the ablations show this helps on some tasks and hurts on others, so treat it as a knob, not a guarantee.
The expected improvement over hand-coded reward is task-dependent and sometimes negative on raw score, which is the honest framing. On the simulated robotics tasks, 700 human-equivalent labels nearly matched RL trained on the true reward. On a few tasks human feedback beat the true reward, because the humans gave better-shaped feedback, for example rewarding the robot for staying upright. On the harder Atari games it lagged RL but still learned real behavior.
The failure mode to plan around is reward gaming under stale feedback. The paper found that if you train the reward model offline on a fixed batch of clips and stop asking, the agent finds behaviors the frozen model scores high but that score nothing on the real task. On Pong this produced agents that rallied forever without trying to win. The fix is keeping the human in the loop online, which costs ongoing labeling but prevents the drift. If you can't afford continuous labeling, this approach will quietly degrade.
For a PhD candidate
The contribution is scaling preference-based reward learning to deep RL and to behaviors an order of magnitude more complex than prior work, while cutting human time by roughly an order of magnitude versus the comparison-hungry predecessors. Akrour et al. and Wilson et al. had the preference-elicitation idea, but on low-dimensional domains with reward linear in hand-coded features, and they elicited preferences over whole trajectories. This work uses short clips, nonlinear neural reward models, and modern deep RL, A2C for Atari and TRPO for the MuJoCo tasks.
The methodological choices reward scrutiny. Clips beat single states because asking a human to compare 1-to-2-second clips is nearly as fast as comparing single frames but far more informative per query; the per-clip evaluation time stays roughly constant for short clips, then grows linearly. Comparisons beat absolute scores because humans give more consistent ordinal judgments than cardinal ones, especially on continuous control where reward scale varies wildly and wrecks a regression. The Bradley-Terry fit adds a 10% uniform-noise term so the human's error probability doesn't decay to zero at large reward gaps, which keeps the loss well-behaved. An ensemble of predictors, each on a bootstrap sample of the comparison database, both regularizes r̂ and supplies the disagreement signal for query selection.
Threats to validity worth probing. The query-by-disagreement heuristic is a crude proxy for value of information, and the ablations show it sometimes underperforms random sampling, so the active-learning story is shakier than the headline implies. The real-human results are single runs per task, against five-run averages for the synthetic oracle, so the human curves carry more noise than the plots suggest. And the central reward-hacking finding, that offline training lets the policy exploit a partial proxy, is demonstrated qualitatively on a few games rather than measured systematically. The clean follow-ups, most of which the field then chased, are better query selection via real value-of-information, tighter analysis of reward-model overoptimization, and removing the policy-side instability that comes from optimizing a moving, nonstationary reward.
For a peer researcher
The delta against Akrour and Wilson is that preference learning stops being a small-domain technique and becomes something that drives state-of-the-art deep RL. Three changes carry it: short clip segments instead of whole trajectories, which buys an order of magnitude less human time per unit of information; a nonlinear neural reward model fit online instead of a linear-in-features reward fit by Bayesian inference; and asynchronous training of the reward and policy so the reward keeps tracking the policy's shifting state distribution.
The choices read as deliberate tradeoffs. Comparisons over scores trades a little expressiveness for far better human consistency, and the paper is candid that on Atari, where they clip rewards and effectively predict only the sign, targets and comparisons performed comparably. Online over offline trades ongoing labeling cost for robustness against the policy exploiting a frozen proxy, and the Pong-rallies-forever result is the clean demonstration that the nonstationarity is not optional. Disagreement-based queries trade simplicity for a heuristic that the ablations show is not reliably better than random, which the authors flag rather than oversell.
What would change my mind on the central claim. If a frozen offline reward model, given a large enough and diverse enough initial comparison set, matched the online version without drift, the "feedback must be intertwined with RL" framing would weaken. It didn't, and the mechanism is clear: the reward model is accurate only on the support of the clips it was trained on, and an optimizing policy walks straight off that support. The honest open problem the paper names, scaling this to the point where learning from human preferences is no harder than learning from a programmatic reward, is exactly the alignment agenda the next decade ran with.
How it works
The problem and why prior approaches failed. Reinforcement learning needs a reward function, and many real goals don't have a clean one. Hand-engineering a reward that captures what you actually want is hard, and a reward that's even slightly wrong gets gamed, which is the misalignment worry. Inverse reinforcement learning and imitation learning sidestep this by learning from demonstrations, but they need a human able to demonstrate the task, which fails for behaviors a human can recognize but not perform. Using raw human feedback as the reward directly is too expensive, because deep RL needs hundreds to thousands of hours of experience and you can't have a human in the loop for every step. Earlier preference-learning work fit a reward from comparisons but stayed in low-dimensional domains with linear reward models and whole-trajectory comparisons.
The key idea. Learn a separate reward model from cheap human comparisons, then optimize the policy against the model. Because one comparison teaches a rule the model applies everywhere, the human only has to label a tiny fraction of the agent's experience. The reward model is trained online so it keeps up as the agent's behavior shifts.
Methodology. The system maintains a policy π and a reward estimate r̂, both deep networks, updated by three asynchronous processes. The policy interacts with the environment and is trained by a standard RL algorithm, A2C for Atari and TRPO for MuJoCo, to maximize the sum of predicted reward r̂. Pairs of clips from the policy's recent trajectories go to a human, who marks one as preferred, calls it a tie, or marks the pair incomparable. The labeled comparisons accumulate in a database D, and r̂ is fit to them by minimizing the Bradley-Terry cross-entropy from earlier.
P̂[σ¹ ≻ σ²] = softmax over clips of ( Σ r̂ along each clip )
loss(r̂) = - Σ_(σ¹,σ²,μ) ∈ D μ(1) log P̂[σ¹ ≻ σ²] + μ(2) log P̂[σ² ≻ σ¹]Several details earn their keep. The rewards from r̂ are normalized to zero mean and constant variance, since the loss only fixes reward up to scale and shift. An ensemble of predictors, each trained on a bootstrap of D, gets averaged for the estimate and supplies a disagreement signal. Queries go to the clip pairs with the highest ensemble disagreement, a rough uncertainty heuristic. A fraction of D is held out for validation to tune regularization. And the fit assumes a 10% chance the human answers uniformly at random, so the model tolerates label noise.
In the simulation, switch Query by disagreement to Random queries and watch how the reward-match curve changes. The disagreement rule aims labels at the clips the ensemble is unsure about, but as the paper's ablations found, it isn't always the winner.
Results with effect sizes. On 8 MuJoCo robotics tasks, 700 synthetic labels nearly matched RL on the true reward, and by 1400 labels the method slightly beat true-reward RL on some tasks because the learned reward was better shaped. Real human feedback ranged from half as efficient to fully as efficient as synthetic feedback, and on Ant it beat synthetic feedback by rewarding the robot for staying upright. On 7 Atari games with about 5,500 human labels, the method matched or came close to RL on Beam Rider, Pong, Seaquest, and Q*bert, and learned substantial behavior on the rest, though it never matched RL on Space Invaders or Breakout. For novel behaviors it trained a Hopper backflip with about 900 queries in under an hour, a one-legged Half-Cheetah hop with 800 queries, and an Enduro car that drives alongside traffic with about 1,300 queries.
Limitations and open questions. The reward model is only accurate on the distribution of clips it has seen, so offline-only training lets the policy exploit a partial proxy, the Pong rally-forever failure. Real-human runs are single seeds and noisier than the synthetic averages. The disagreement-based query selection is a crude approximation and sometimes hurts. The authors leave better query selection via value of information, and closing the gap to programmatic-reward difficulty, as future work.
My assessment
The authors got the central bet right, and the field validated it hard. The learn-a-reward-from-comparisons-then-optimize loop is now the backbone of how large language models get tuned, and this is the paper that proved it scales to deep networks. The two choices that mattered most were the cheap ones. Comparisons over absolute scores fit human psychology, and the Bradley-Terry fit is a few lines of logistic regression. Training the reward online instead of offline is the other load-bearing call, and the Pong-rallies-forever result is one of the cleaner early demonstrations of reward hacking, which has since become a whole subfield.
Where the paper was honest to a fault is the active-learning story. The disagreement heuristic for query selection is presented with its own ablations showing it sometimes loses to random sampling, which is the right way to report a heuristic that didn't fully pan out. The weakest brick is evaluation rigor on the human side, single runs against five-run synthetic averages, which makes the human-versus-oracle comparisons suggestive rather than tight. None of that dents the core. The expensive thing in RL is human attention, and this showed you can spend almost none of it and still communicate a complex goal. The closing line, hoping to make learning from human preferences no harder than learning from a coded reward so powerful systems serve human values, reads now less like a flourish and more like the research program that followed.