ReAct: Synergizing Reasoning and Acting in Language Models
An agent that thinks and acts in the same breath, writing a reasoning note then taking a real action so each one fixes the other's blind spot.
Read at your level
Start where you're comfortable and climb as far as you like.
- For a 5-year-old
- For a high schooler
- For a college student
- For an industry pro
- For a PhD candidate
- For a peer researcher
Executive summary
Before this paper, people used a language model in one of two ways. They asked it to reason out loud, which is chain-of-thought, and got fluent steps that sometimes made up facts. Or they asked it to take actions in a tool or a game, which is acting, and got an agent that fetched real information but couldn't plan or recover when it got lost. ReAct does both in one trace. The model writes a thought, takes an action, reads what the action returned, then writes the next thought, and keeps looping. The thought decides what to do next and the action checks the thought against the real world. On question answering and fact-checking with a Wikipedia API, this almost erased the hallucination that sinks chain-of-thought. On two interactive tasks, ALFWorld and WebShop, it beat agents trained on thousands of examples by 34 and 10 points of success rate while using one or two examples in the prompt. The catch is that a bad search still derails the reasoning, and big tasks need more examples than a prompt can hold.
Try it
Load ReAct grounds the answer and step through it. Each thought triggers a search, each search hands back a real page, and the next thought builds on it until the agent finishes on the verified answer. Now load CoT hallucinates and watch the same question go wrong, the model guessing a device it never checked. Then go back to ReAct, press play, and the moment the agent finishes its first thought hit Kill next search. The reasoning loses the fact it was about to stand on, and the run stalls.
ReAct on the Apple Remote question. Step it and watch each thought trigger a search, each observation feed the next thought, until it finishes on the grounded answer.
Figure 1's headline question. CoT hallucinates an Apple TV answer; ReAct searches its way to Front Row and the real answer.
Step the run, switch a mode, or inject a fault to start the log.
The agent walks the paper's own HotpotQA and Fever trajectories one step at a time. The Wikipedia stub here returns a few canned pages, where the paper hits the live API; the reasoning, the action format (search/lookup/finish), and the failure modes follow the paper. Killing a search reproduces its search-error mode, corrupting memory reproduces the CoT hallucination mode, and editing a thought is the human-in-the-loop correction from Figure 5.
For a 5-year-old
Imagine a detective trying to solve a mystery. A bad detective just sits in a chair and guesses. "I bet the butler did it." He sounds sure, but he never checked, so he's often wrong.
A good detective does two things over and over. First he writes a note to himself. "I should go look in the kitchen." That's thinking. Then he gets up and actually walks to the kitchen and opens the drawers. That's acting. When he sees what's really in the kitchen, he writes a new note. "There's no knife here, so I should check the garden next." Then he walks to the garden.
Thinking tells him where to go. Looking tells him what's really there. He keeps switching between the two until he knows the answer for sure, because he saw it with his own eyes.
The detective isn't a person here. It's a computer that writes sentences. Its notes are just words it makes up, and its "walking to the kitchen" is really looking something up on a website. But the trick is the same. Guessing alone gets you a wrong answer that sounds nice. Looking alone gets you lost. Doing both, a little thinking then a little looking, gets you the real answer.
For a high schooler
You've used a chatbot that explains its reasoning. You ask a tricky question and it says "let me think step by step," then walks through it. That's called chain-of-thought, and it works well, until the model needs a fact it doesn't actually know. Then it makes one up. The made-up fact sounds just as confident as a real one, and the whole answer goes wrong from there. That made-up fact has a name. We call it a hallucination, a statement the model produces that isn't true and isn't checked.
ReAct fixes this by letting the model do something besides think. It can also act, which here means it can search a website and read what comes back. So a single answer becomes a back-and-forth. The model writes a thought, takes an action, reads the result, writes the next thought, and repeats.
Here's a worked example. The question is "what device, besides the Apple Remote, can control the program the Apple Remote was built for?" A guessing model says "the Apple Remote controls Apple TV, and Apple TV is controlled by your iPhone," and answers iPhone. That's wrong, and it's a guess. ReAct instead searches "Apple Remote," reads that it was built to control a program called Front Row, searches "Front Row," and reads that Front Row is also controlled by the keyboard function keys. So the answer is keyboard function keys, and every step came from a page it actually read.
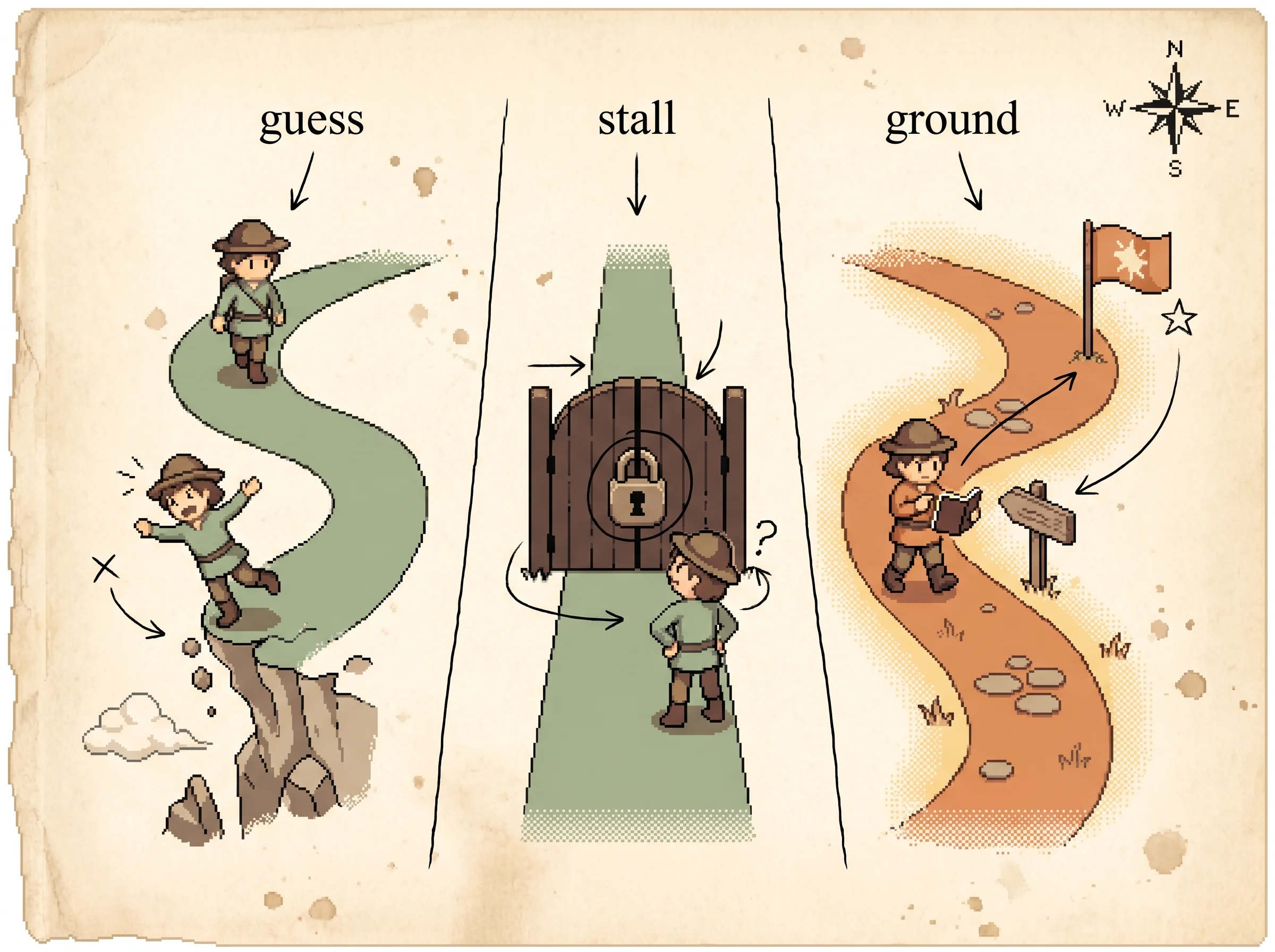
Thinking without checking walks off a cliff. Checking without thinking stalls at a gate it can't open. Doing both reaches the flag.
For a college student
You should care about this because it's the blueprint for almost every tool-using AI agent built since. The setup is an agent that reads an observation from an environment and picks an action from some action space, following a policy. The hard part is that the map from a long messy history to the right next action is implicit. Chain-of-thought helps the model reason about that map, but it reasons in a closed box. It never touches the world, so it can't pull in a fact it's missing or notice that a step went wrong.
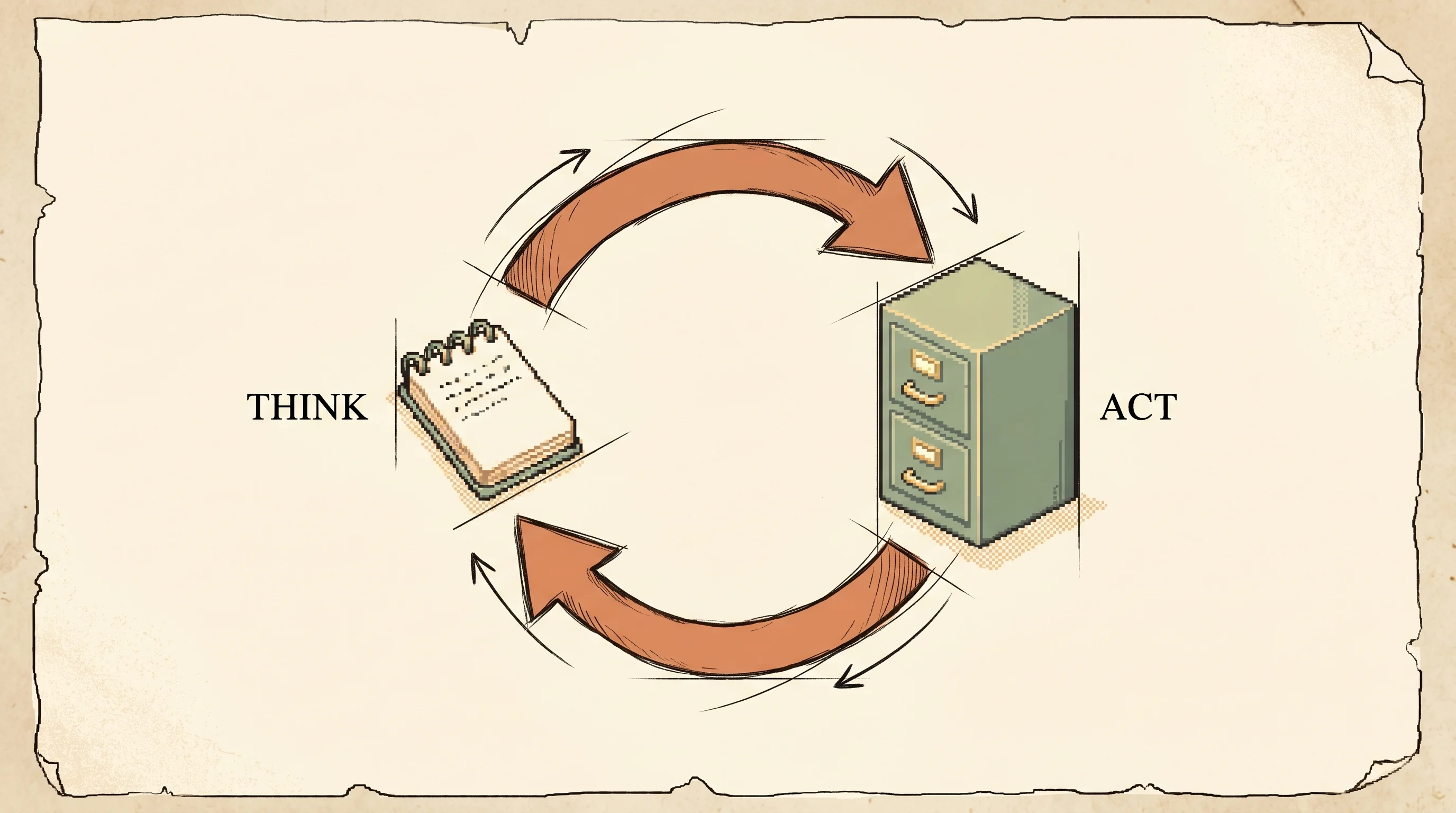
The idea is one line. ReAct grows the action space. On top of the real actions the environment understands, it adds a "thought" action whose space is free-form language. A thought doesn't change the environment and gets no observation back. It just updates the running context the model conditions on. So the context grows by interleaving three kinds of lines.
Thought: free-form reasoning that updates the plan, no environment feedback
Action: a real action, e.g. search[entity] or lookup[string] or finish[answer]
Obs: what the environment returned for that actionFor the Wikipedia tasks the action space is deliberately weak, three verbs. search[entity] returns the first few sentences of a page or suggests similar titles, lookup[string] finds the next mention of a string on the current page, and finish[answer] ends the task. The authors kept it weak on purpose, to force the model to retrieve through explicit reasoning the way a person would, rather than leaning on a strong retriever.
One worked path, end to end, is the Colorado orogeny question. "What is the elevation range for the area the eastern sector of the Colorado orogeny extends into?" The agent searches Colorado orogeny, reads that it's mountain building in Colorado, notices the page never mentions the eastern sector, looks up "eastern sector," reads that it extends into the High Plains, searches High Plains, finds the page is ambiguous, reformulates to "High Plains (United States)," reads that the High Plains rise from about 1,800 to 7,000 feet, and finishes there. Each thought decides the next action, each observation corrects the next thought, and the reformulation step is the model reasoning its way out of a dead end. No single chain-of-thought leap could do that, because the facts live on three different pages.
The whole thing runs with no training. The model is frozen and the format is taught by one to six worked examples in the prompt.
For an industry pro
The problem this solves for you is the gap between a model that talks and a model that does. Chain-of-thought gives you fluent reasoning that hallucinates, which is unusable for anything where the facts have to be right. A plain tool-calling agent grounds its facts but flails when a tool returns nothing useful, because there's no reasoning layer deciding what to try next. ReAct is the cheap fix. You let the model emit a reasoning step between tool calls, and that step plans, tracks progress, and recovers from a bad result.
Deployment cost is low, which is the headline. It's a prompting pattern, not a new model and not a training run. You write one to six example trajectories that interleave thoughts, tool calls, and tool outputs, and the model copies the format. The numbers back the effort. On the Apple-Remote-style multi-hop questions, the failure-mode breakdown is stark. Chain-of-thought hallucinated in 56% of its failures. ReAct hallucinated in 0%. On the ALFWorld household task it hit 71% success against 37% for the trained baseline, and it beat the WebShop shopping agent by 10 points, both while learning from a handful of examples instead of thousands.
The failure mode to plan around is the search. ReAct's quality lives and dies on retrieval. When a search comes back empty or off-topic, it derailed the reasoning in 23% of the error cases, and the agent can get stuck repeating the same thought and action. So the operating envelope is this. Give it a retriever or tool that mostly returns relevant results and it shines. Point it at a flaky tool and it inherits the flakiness, plus a tendency to loop. The paper's own fix is worth copying. When ReAct can't answer within a step budget, fall back to chain-of-thought, and when chain-of-thought isn't confident, fall back to ReAct. The combination beat either alone.

For a PhD candidate
The contribution is showing that reasoning and acting, studied as separate threads, work better fused into one trajectory, and that the fusion is a prompting pattern over a frozen LLM rather than a new architecture. The closest prior work splits cleanly. Chain-of-thought reasons but never grounds, so it propagates its own errors. SayCan and WebGPT act but treat the LLM as a policy over actions, with reasoning either absent or pushed into an external affordance model. Inner Monologue gets closest by injecting environment feedback between actions, but its "monologue" is limited to observed environment state and what's left to do, not the open-ended planning ReAct allows.
The methodological choices reward scrutiny. The thought action is defined as a no-op on the environment that only edits context, which is the clean abstraction that lets one policy emit both kinds of token without a mode switch. The Wikipedia action space is intentionally crippled to exact-match search, weaker than a neural retriever, because the goal was to test reasoning-driven retrieval, not retrieval quality. The density of thoughts is task-dependent and the authors let the model decide it. For multi-hop QA, thoughts and actions alternate one to one. For the long-horizon ALFWorld and WebShop tasks, thoughts appear sparsely, only at decision points, because forcing a thought before every low-level action would bloat the trajectory past the context window.
The threats to validity are honest in the paper. The headline QA gains are not on raw EM, where ReAct trails chain-of-thought with self-consistency, but on the combination and on trustworthiness. The interpretability claim that thoughts let a human inspect and correct the agent rests on a small human-in-the-loop study where editing two thoughts flipped a failed ALFWorld run to a success, which is suggestive rather than systematic. And the structural constraint of grounding every claim raises ReAct's reasoning-error rate above chain-of-thought's, because the model has less freedom to formulate steps. The open questions the field then chased are obvious from here. Scaling the example trajectories past the context limit, which pushed people toward fine-tuning and retrieval over a trajectory bank, and combining ReAct with reinforcement learning, which is exactly where later agent work went.
For a peer researcher
The delta against chain-of-thought is grounding, and against tool-using policies like WebGPT and SayCan it's open-ended reasoning, in one trajectory and with no training. Strip it down and ReAct is one move. Augment the action space with a language-only "thought" action that's a no-op on the environment and only mutates the context the policy conditions on. Everything else is the existing few-shot recipe.
The choices read as deliberate tradeoffs. The deliberately weak exact-match Wikipedia API trades retrieval strength for a clean test of whether reasoning can drive retrieval, and the answer is that it can, but it makes the agent brittle to non-informative search, the 23% derail mode. The grounding constraint trades flexibility for trustworthiness. ReAct's hallucination rate falls to roughly zero while its reasoning-error rate climbs above chain-of-thought's, since the model can't freely reformulate steps that aren't anchored in an observation. The task-dependent thought density trades uniformity for fitting the context budget, dense for reasoning-heavy QA and sparse for action-heavy control.
What would change my mind on the central claim. If a pure chain-of-thought variant with a strong external verifier matched ReAct's trustworthiness without interleaving actions, the synergy framing would weaken to "just add a verifier." It didn't, because the interleaving is what lets the model choose what to retrieve next based on what it just read, which a post-hoc verifier can't do. The honest soft spots are the context limit, which caps how many demonstrations you can show and is why the paper's own fine-tuning experiments point the way forward, and the dependence on retrieval quality, which the next several years of agent work spent improving.
How it works
The problem and why prior approaches failed. A task-solving agent reads observations from an environment and emits actions, and the mapping from a long history to the right action is implicit and hard. Two families attacked this separately. Chain-of-thought prompting makes the model reason in language before answering, which helps on arithmetic and commonsense, but it reasons in a closed loop over its own internal state. It never gathers new information, so when it lacks a fact it fabricates one, and the fabrication propagates. Action-generation agents interact with a real environment but use the LLM as a policy that predicts actions, with no abstract reasoning to decompose a goal, track subgoals, or recover from a surprise. So one family hallucinates and the other gets lost.
The key idea. Add a thought to the action space. Formally the action space becomes the real actions plus the whole space of language. A thought in language space doesn't affect the environment and produces no observation. It only updates the context the model conditions on for its next move. So a trajectory interleaves thoughts that plan and actions that touch the world.
loop until the model emits finish:
Thought_t = reason over the current context (plan, track, recover)
Action_t = an environment action chosen given the new context
Obs_t = the environment's response to Action_t
context = context + Thought_t + Action_t + Obs_tMethodology. The base model is a frozen PaLM-540B prompted with a few human-written trajectories, one to six per task. For HotpotQA and Fever the action space is a small Wikipedia API, search[entity], lookup[string], and finish[answer], and reasoning is dense, alternating with actions roughly one to one. The thoughts do real work, decomposing the question ("I need to search x, then find y"), extracting facts from an observation, doing commonsense or arithmetic, reformulating a failed search, and synthesizing the final answer. For the interactive ALFWorld and WebShop tasks, where a solution can run more than 50 actions, thoughts appear sparsely at decision points so the trajectory fits the context window. To squeeze more out of the QA setup, the authors add a fallback. When ReAct can't finish within a step budget, hand off to chain-of-thought with self-consistency, and when self-consistency is shaky, hand back to ReAct.
Results with effect sizes. On HotpotQA the raw exact-match numbers are close, Standard 28.7, chain-of-thought 29.4, Act 25.7, ReAct 27.4, with the best result from the ReAct and self-consistency combination at 35.1. The real win shows in the failure analysis. Chain-of-thought's false-positive rate from hallucination is 14% against ReAct's 6%, and hallucination makes up 56% of chain-of-thought's failures versus 0% of ReAct's. On Fever, ReAct scores 60.9 against chain-of-thought's 56.3. The interactive tasks are where ReAct dominates. On ALFWorld its best run hits 71% success against 37% for the trained BUTLER baseline, an absolute gain near 34 points, consistent across six trials. On WebShop it adds 10 points of success over the prior best, learning from one or two examples against thousands.
Limitations and open questions. A non-informative search derails the reasoning, accounting for 23% of ReAct's errors, and the agent can fall into repeating the same thought and action. Forcing every claim to be grounded also raises the reasoning-error rate above chain-of-thought's. And the prompting setup is capped by the context window, so complex tasks with large action spaces need more demonstrations than fit, which the paper's preliminary fine-tuning experiments begin to address.
My assessment
The authors got the core call right, and the field has been blunt about it. ReAct is the skeleton of the modern tool-using agent. The think-then-act-then-observe loop is what sits under web agents, coding agents, and retrieval-augmented systems, and the abstraction that made it work is almost embarrassingly small, a thought is just an action that returns nothing and edits the context. That's the kind of idea that looks obvious only after someone writes it down.
What the paper undersold is the same thing it was honest about. The raw QA accuracy barely moved, and a reader skimming the HotpotQA table could miss the point. The point was never the headline metric. It was that the failure modes changed shape, hallucination going to zero, and that the agent became inspectable, because a human can read the thoughts and edit them. That inspectability turned out to matter more than two points of exact match, since it's what lets people trust and correct an agent in the loop. The soft spot they named, brittleness to bad retrieval, is real and still with us, and the context-window limit they flagged is exactly what pushed the next wave toward fine-tuning on trajectory banks and toward pairing ReAct with reinforcement learning. None of that dents the core. Letting a model think and act in the same trace, so each one catches the other's mistakes, was most of what an agent needed.