Voyager: An Open-Ended Embodied Agent with Large Language Models
A Minecraft agent that learns forever by having GPT-4 write code for each new task, debug it against the game, and save the working programs as reusable skills that compose into harder ones.
Read at your level
Start where you're comfortable and climb as far as you like.
- For a 5-year-old
- For a high schooler
- For a college student
- For an industry pro
- For a PhD candidate
- For a peer researcher
Executive summary
Before Voyager, language-model agents could plan a task or two, but they didn't keep getting better on their own. Voyager drops a GPT-4 agent into Minecraft with no goal and no human help and lets it learn for hours. Three parts make that work. A curriculum looks at what the agent has and picks a good next task. GPT-4 writes JavaScript to do that task, runs it in the game, reads the error, and rewrites it until a checker says it worked. The working program gets saved in a skill library, and harder programs later just call those saved skills. Because skills stack, the agent climbs the Minecraft tech tree fast. It found 3.3 times more unique items than the best prior agents, walked 2.3 times farther, hit tech-tree milestones up to 15.3 times faster, and was the only one to mine a diamond. The cost is that it leans on GPT-4, which is about 15 times pricier than GPT-3.5 and still sometimes gets stuck or chases items that don't exist.
Try it
Load the Full Voyager preset and press play. Watch the agent climb tier by tier while the skill library on the right fills up, the green-barred skills being the ones built by reusing earlier skills. Now switch to No skill library and reset. The early tiers still go fine, but the hard tiers crawl because every program gets written from scratch. Then load No self-verification and watch the unverified count climb while the agent keeps committing programs that didn't really finish the job.
Every part on. The automatic curriculum climbs the tech tree, GPT-4 writes the code, the skill library composes, and self-verification gates every commit.
Empty. Verified skills land here and become callable for harder tasks.
A green bar marks a skill composed from earlier skills. The number is how many it reused.
Hover or click any item to read its prerequisites. Clicking forces the curriculum to attempt that task next.
Step the loop or flip a control to start the log.
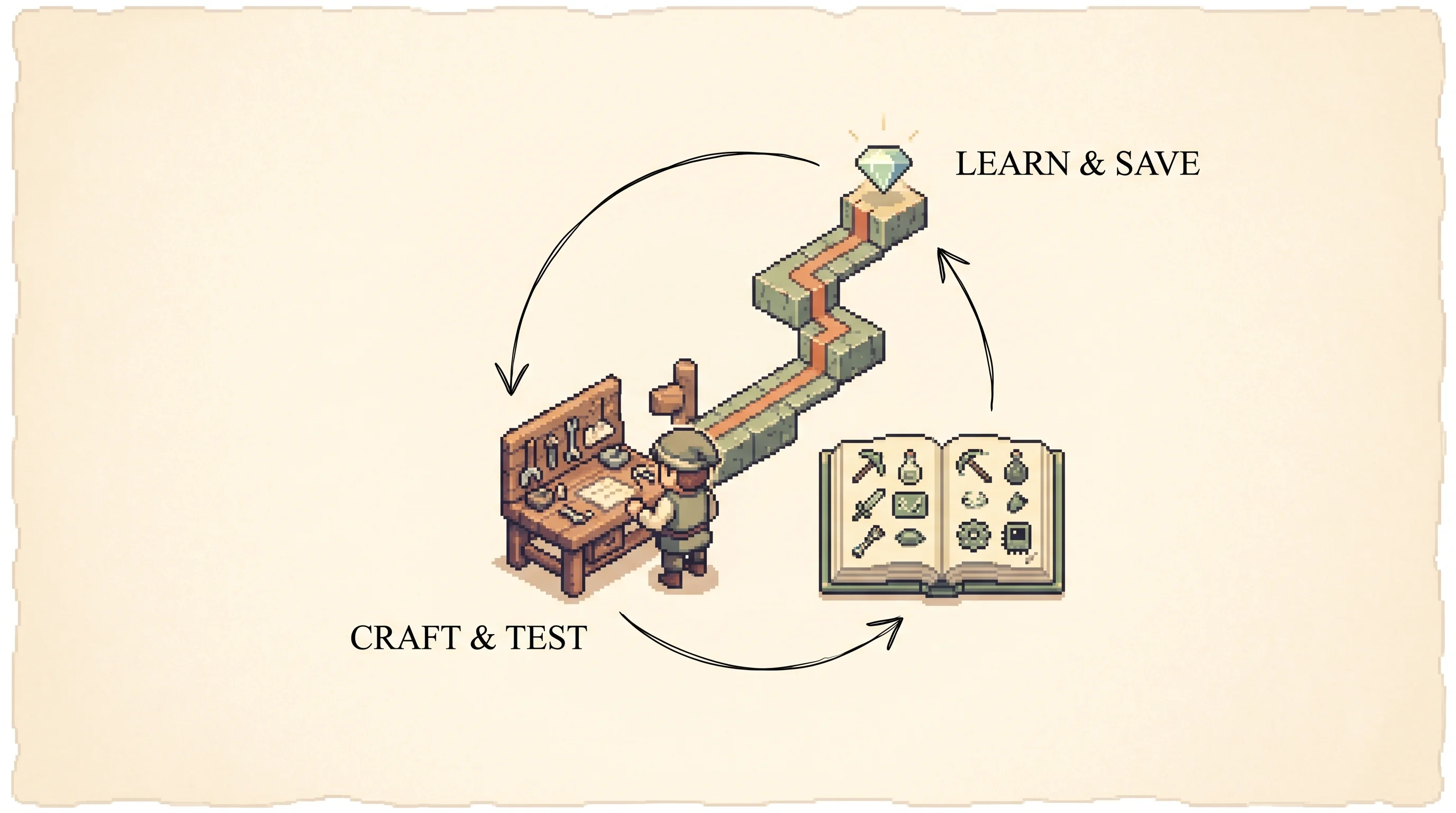
The loop is the paper's real control flow: the curriculum proposes a task, relevant skills are retrieved, the coder writes a program with up to four rounds of refinement from environment feedback and execution errors, a self-verification critic gates the commit, and a verified program joins the skill library keyed by its description. The world is a small 15-item tech tree and GPT-4's coding is modelled as a per-round success chance that rises with retrieved skills; the real agent plays Minecraft through Mineflayer and queries GPT-4 over thousands of items. Each preset uses a fixed seed so the same preset always produces the same run; playback speed is animation pace only.
For a 5-year-old
Imagine a kid playing a building game. The kid wants to make cool stuff, but they have to learn the easy things first. First you chop a tree to get wood. Then you turn wood into sticks. Then you use sticks to make a pickaxe. Then the pickaxe lets you dig stone, and stone makes a better pickaxe, and on and on.
Here's the clever part. Every time the kid figures out how to make something, they write it down in a recipe book. So the next time they need sticks, they don't have to figure it out again. They just flip to the page. And to make a big thing like a pickaxe, they flip to the wood page and the stick page and snap them together. The book keeps getting fatter, and the kid keeps making bigger things.
Voyager is a robot kid like that. Nobody tells it what to do. It picks its own next thing to try, writes down what works, and uses the old pages to build new ones. Real robots don't have hands or a paper book. The recipe book is little computer programs, and the robot writes them by asking a very smart helper called GPT-4. But the feeling is the same. Learn a little, write it down, then use it to learn the next thing.
For a high schooler
You know how a video game has a tech tree? You can't build the iron sword until you have iron, and you can't get iron until you have a stone pickaxe, and so on. Voyager is a computer agent that plays Minecraft and climbs that whole tree by itself, with no human telling it what to do.
Here's the one new idea for this section. Voyager doesn't move the character with button presses. It writes a little program for each task. A program is just a list of instructions, like "find wood, then chop it, then turn it into planks." When the agent wants to do something new, it asks GPT-4 (the same kind of model behind ChatGPT) to write that program. Then it runs the program in the game and sees what happens.
The program almost never works the first time. Maybe it says "I need 2 more planks" or it crashes with an error. So the agent feeds that complaint back to GPT-4 and asks for a fix. It does this a few times until a checker agent looks at the result and says "yes, you actually made the iron pickaxe." Only then does the agent save that program.
That saving step is the whole trick. Say it took 30 lines of code to learn how to make a stick. Once it's saved, making a stick is one line: just call the saved program. So the next big task, like an iron pickaxe, is short to write because it reuses the stick program and the iron program and the table program. The agent gets faster as it goes instead of slower.
Voyager learns this way for hours and ends up far ahead of older agents. It picked up 3.3 times as many different items and was the only one to reach a diamond.
For a college student
You should care about this because it shows a path to capable agents that needs no gradient updates at all. The model weights never change. All the learning lives in text and code that the agent writes, runs, and stores. That's a different axis from the usual "train a bigger network."
The setup. Minecraft has no fixed goal, which makes it a clean test for open-ended learning. Voyager controls the character through the Mineflayer JavaScript API, so its actions are programs, not low-level joystick commands. It talks to GPT-4 through plain API calls. Three components run in a loop.
First, the automatic curriculum. GPT-4 looks at the agent's current state (inventory, equipment, nearby blocks, biome, health, and the list of tasks already done or failed) and proposes the next task, with a standing instruction to favor novel, reachable goals. The point is to keep the next task hard enough to learn from but not impossible.
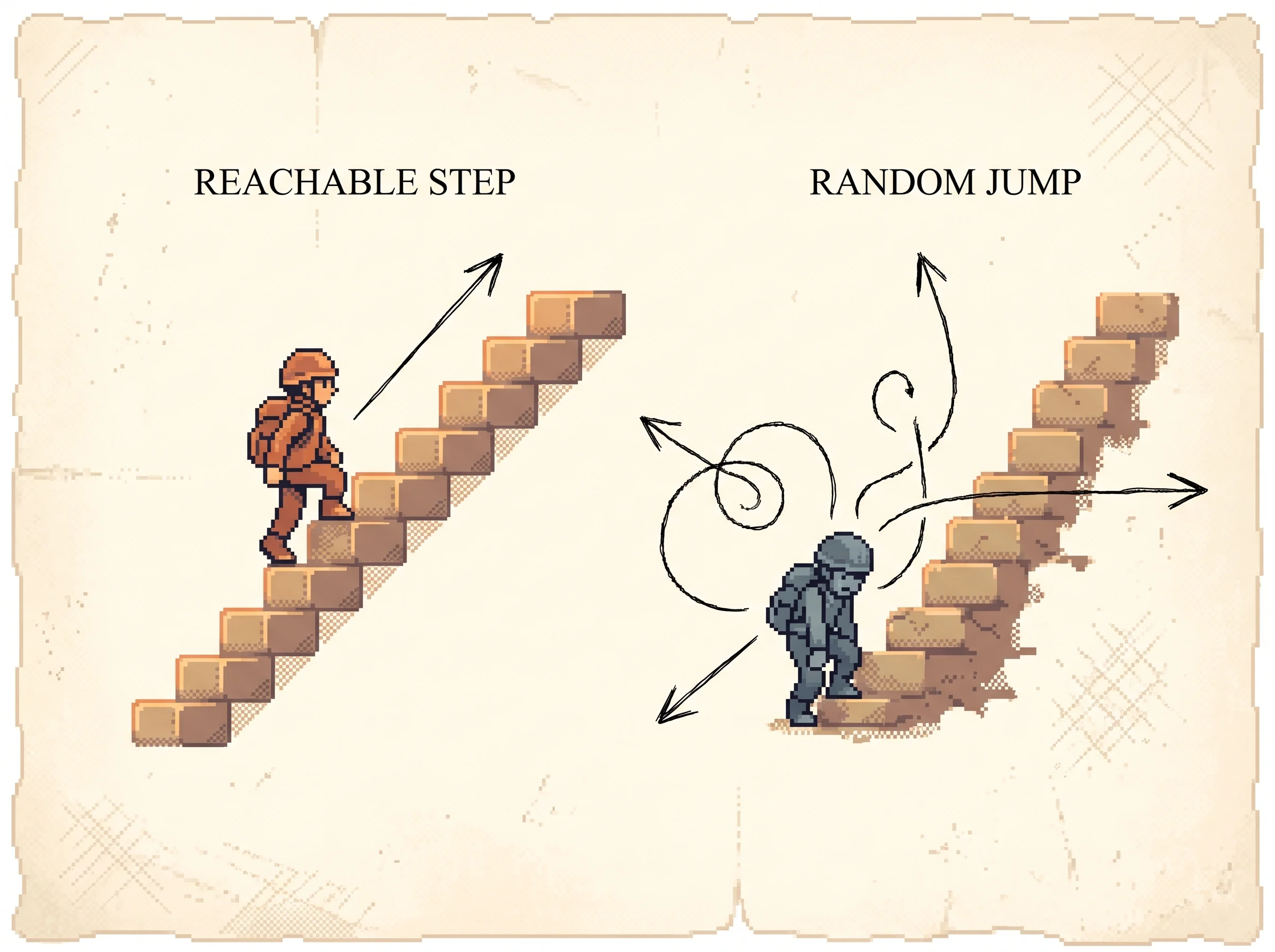
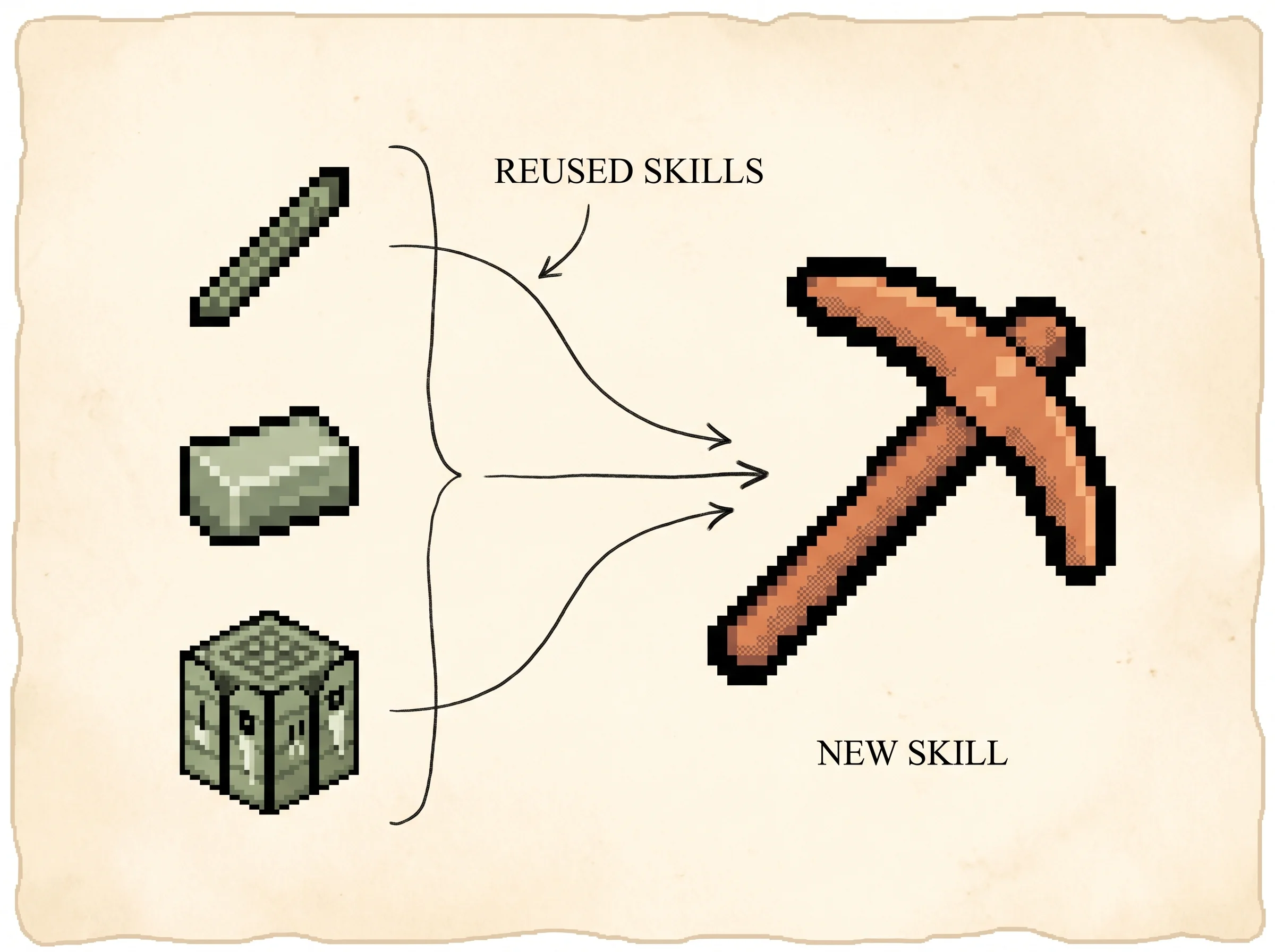
Second, the skill library. Each verified program is stored in a vector database. The key is an embedding of a short natural-language description of what the program does, and the value is the program itself. When a new task comes in, the agent embeds a generated plan for the task plus the current environment feedback, retrieves the top few matching skills, and hands them to GPT-4 as building blocks. Composition is just function calls, so a complex skill is a short program that calls simpler ones.
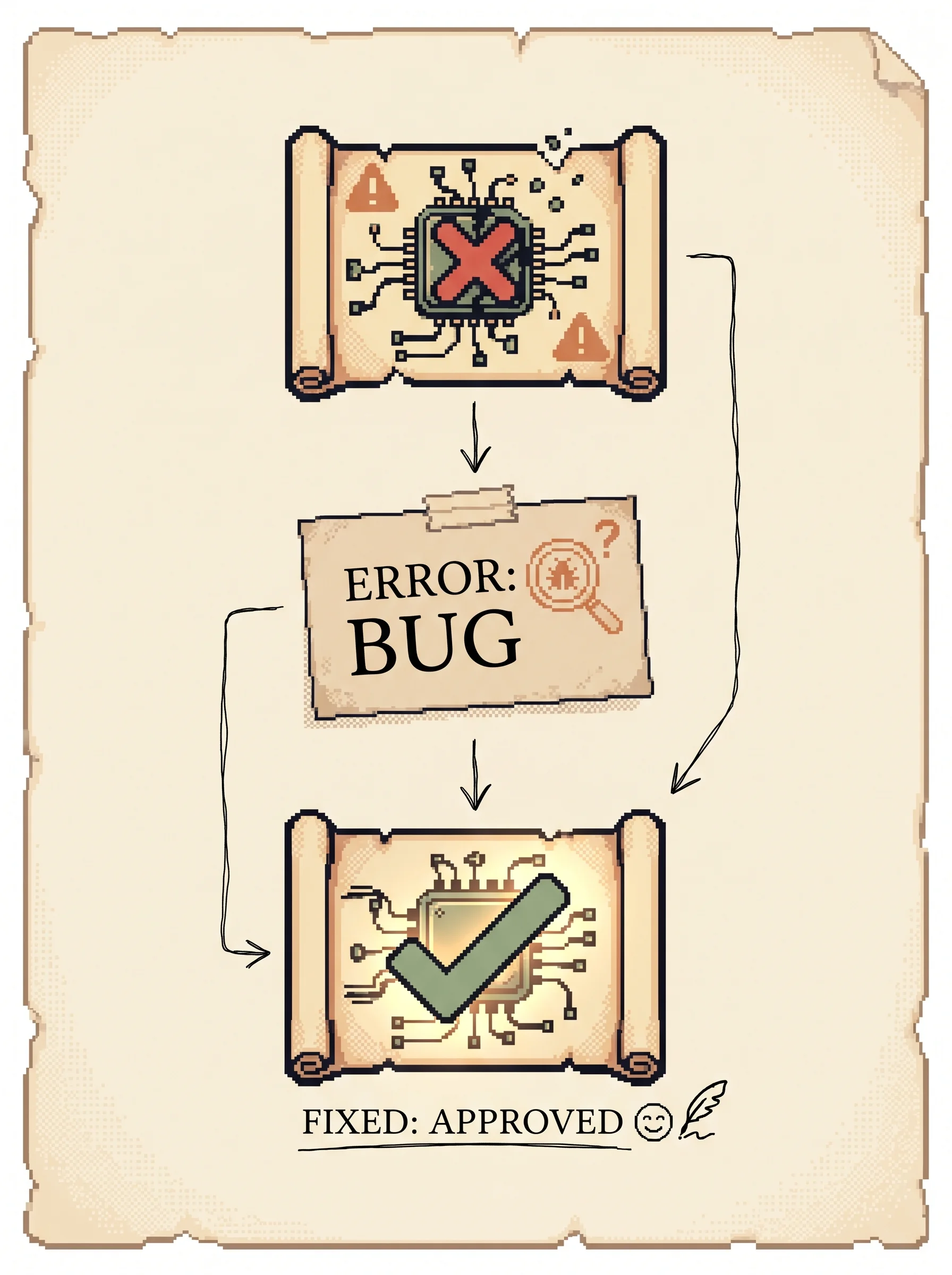
Third, the iterative prompting mechanism. GPT-4 writes a program, the agent runs it, and three kinds of feedback flow back. Environment feedback is the game telling you "I cannot make a stick because I need 2 more planks." Execution errors are interpreter crashes, like calling an item name that doesn't exist. Self-verification is a separate GPT-4 critic that looks at the before-and-after state and decides whether the task is actually done, giving a critique if not. The agent refines for up to four rounds. If the critic passes it, the program is committed and the curriculum is asked for the next task. If four rounds fail, the task is shelved and the curriculum can return to it later.
One worked path. The curriculum proposes "craft a stone pickaxe." The agent retrieves its saved mineWood, craftStick, and makeCraftingTable skills. GPT-4 writes a craftStonePickaxe program that calls them and adds the new step of mining cobblestone. The first run reports "I need 2 more sticks." That feedback goes back, GPT-4 inserts a step to craft more sticks, the rerun succeeds, the critic confirms a stone pickaxe in the inventory, and craftStonePickaxe joins the library. The next task, an iron pickaxe, will retrieve this exact skill.
The limitation is cost and reliability. Every step is a GPT-4 call, which is about 15 times the price of GPT-3.5, and the authors show GPT-3.5 can't do the coding well enough to replace it. The agent also gets stuck sometimes and the curriculum occasionally proposes impossible items.
For an industry pro
The problem this solves is the one that kills most agent demos. A scripted LLM agent does a few steps and stops improving. Voyager keeps improving across a long session with no retraining, because the learning is stored as code in a library rather than in weights. If you're building an agent that operates a tool-rich environment over time, the reusable-skill pattern is the part worth copying.
Three things make it work, and each maps to something you'd build. The skill library is a vector store of verified, callable functions keyed by a description embedding, so retrieval is cheap and the agent composes instead of regenerating. The iterative refinement loop wires the environment's own error messages and a self-check critic back into the prompt, which is what turns a one-shot code generator into something that converges. The automatic curriculum keeps task difficulty in the learnable zone by reading live state, so the agent doesn't waste calls on tasks it can't reach.
Deployment cost has a sharp edge. Every task is many GPT-4 calls, and the ablations are blunt about why you can't downgrade. Self-verification carries the most weight: removing it drops the discovered-item count by 73 percent, because the agent stops knowing when a task is really done and moves on too early or loops on a finished one. Swapping GPT-4 for GPT-3.5 gives 5.7 times fewer items, since the cheaper model can't write the code. So the bill is GPT-4 calls times a self-verification critic times a multi-round refine loop, and the paper shows each factor earning its place.
The failure modes to plan around are concrete. The agent hallucinates tasks, asking for a "copper sword" that doesn't exist in the game, and burns rounds on them. It hallucinates inside code too, calling APIs that aren't there or using cobblestone as fuel. Self-verification occasionally misreads success. For a real deployment, that means a hard cap on retries per task (the paper uses four), a way to shelve and revisit stuck tasks, and a grounding step so the planner can't propose actions the environment can't support. The expected improvement over a ReAct or AutoGPT style loop is large here, not marginal, because those baselines lack the library and the verification and never get off the ground in this setting.
For a PhD candidate
The contribution is an in-context lifelong-learning agent for an open-ended embodied world, with no fine-tuning, where the learned policy is an ever-growing library of executable programs. The delta over the surrounding literature is the combination. Prior LLM-in-Minecraft work (the Volum-style high-level planner with Codex) needed human interaction and lacked a curriculum. ReAct and Reflexion bring reasoning and self-reflection but no persistent skill store, so they don't accumulate. AutoGPT decomposes goals in a ReAct loop but, again, has no library, no verification, and no exploration curriculum. Voyager's claim is that the three together produce compounding open-ended progress, and the ablations are the argument.
The methodological choices reward scrutiny. Code as the action space is the load-bearing decision. Programs are temporally extended and compositional, so one skill abstracts many primitive actions and composition is literally function calls, which is what lets the library grow without the prompt blowing up and what alleviates catastrophic forgetting, since old skills are frozen artifacts that new ones call rather than weights that drift. Self-verification over self-reflection is the second key choice: Reflexion reflects on mistakes, but Voyager's critic both checks success and reflects, and the authors argue the success check is what decides when to move on. The retrieval key is the embedding of the program description rather than the code, which keeps lookups semantic.
Threats to validity worth probing. The headline metrics run three trials each, which is thin, and the comparisons re-interpret NLP agents (ReAct, Reflexion, AutoGPT) for an embodied setting they weren't built for, so the baselines may be undertuned. The diamond result is 1 of 3 trials, honestly reported. The system relies on the specific coding ability of gpt-4-0314, so the result is partly a statement about that model rather than the architecture alone. And self-verification using the same model family as the actor invites correlated blind spots, which the paper acknowledges when the critic misses spider string as a success signal. The obvious follow-ups, several of which the field then chased, are grounding the curriculum so it can't hallucinate items, multimodal perception so the agent can see (here humans stand in as visual critics for 3D builds), and pushing the same skill-library idea into robotics with a code API.
For a peer researcher
Delta first. Strip the recurrence of older agent loops and the point is this: make the policy an external, append-only library of verified programs, key it by description embeddings, and close the loop with the environment's own feedback plus a self-verification critic, all without touching weights. That's the move. Everything else (Mineflayer, MineDojo, the specific tech-tree metrics) is apparatus.
The choices read as deliberate tradeoffs. Code-as-action buys composition and interpretability at the cost of being hostage to the LLM's code quality, which the GPT-3.5 ablation (5.7 times fewer items) shows is not negotiable. The automatic curriculum buys learnable-difficulty task selection at the cost of hallucinated tasks, since a model proposing goals from internet priors will ask for items the game doesn't have. Self-verification buys a stopping criterion at the cost of correlated failure with the actor, and it's the single most load-bearing component (removing it costs 73 percent of discovered items, more than removing the library, which mainly causes a late-stage plateau).
What would change my mind on the central claim. If a fine-tuning-free agent without a persistent skill library matched the tech-tree speed and the zero-shot transfer to a fresh world, the "library is what compounds" story would weaken. It didn't: w/o-skill-library plateaus and fails the diamond, and the library even boosts AutoGPT when bolted on, which is a clean demonstration that the library is a transferable asset rather than a quirk of the full system. The honest soft spots are cost and hallucination, and the open question the paper leaves wide, grounding the planner and adding perception, is where the next wave of embodied-agent work went.
How it works
The problem and why prior approaches failed. Building agents that explore, plan, and pick up new skills in an open world is a long-standing goal. Classical reinforcement learning and imitation learning struggle with systematic exploration, interpretability, and generalization in a world as open as Minecraft, which has no fixed goal. LLM-based agents brought world knowledge and planning, but they weren't lifelong learners. They couldn't progressively acquire, keep, and transfer skills across a long session. ReAct and Reflexion reason in the moment but forget; AutoGPT decomposes goals but keeps no library. None of them compound.
The key idea. Make the agent's growing competence live outside the model, as a library of executable programs it writes, verifies, and reuses. Drive the whole thing with a self-generated curriculum and a refine-until-it-works loop, and never touch the model's weights.
Methodology. Three components run in a loop, all on GPT-4 through blackbox API calls, with Mineflayer as the motor API.
The automatic curriculum prompts GPT-4 with the agent's state and its completed and failed tasks, under a directive to propose novel, reachable goals.
loop:
task = curriculum.propose(agent_state, done, failed)
skills = library.retrieve(embed(plan(task) + env_feedback), k=5)
program = gpt4.write_code(task, skills, guidelines)
for round in 1..4:
result, env_feedback, errors = environment.run(program)
if self_verify(task, agent_state_before, agent_state_after):
library.add(key=embed(describe(program)), value=program)
break
program = gpt4.refine(program, env_feedback, errors, critique)The skill library stores each verified program keyed by the embedding of its description, so retrieval is semantic and a complex skill is a short program that calls simpler stored ones. Composition is the reason the agent speeds up rather than slowing down as tasks get harder.
The iterative prompting mechanism feeds three signals back into GPT-4 between rounds. Environment feedback is the game's own message, like "I cannot make an iron chestplate because I need 7 more iron ingots." Execution errors are interpreter traces. Self-verification is a separate GPT-4 critic that checks the before-and-after state and writes a critique when the task isn't done. The agent refines for up to four rounds, then shelves the task if it still fails.
Results with effect sizes. Against ReAct, Reflexion, and AutoGPT in MineDojo, Voyager found 63 unique items in 160 prompting iterations, 3.3 times more than the others. It unlocked the wooden, stone, and iron tiers 15.3, 8.5, and 6.4 times faster in prompting iterations, and was the only method to reach the diamond tier (1 of 3 runs). It traversed 2.3 times longer distances. Dropped into a fresh world with cleared inventory, it solved every unseen task tested (diamond pickaxe, golden sword, lava bucket, compass) while the baselines solved none, and its library even lifted AutoGPT when transplanted.
The ablations carry the argument. Replacing the automatic curriculum with a random one cut discovered items by 93 percent. Without the skill library, progress plateaus in the later stages. Removing self-verification, the most important single component, dropped items by 73 percent. Swapping GPT-4 for GPT-3.5 in code generation gave 5.7 times fewer items.
Limitations and open questions. Every step is a GPT-4 call, about 15 times the cost of GPT-3.5, and GPT-3.5 can't substitute. The agent gets stuck and re-attempts tasks later. The curriculum hallucinates items that don't exist (a "copper sword"), and GPT-4 hallucinates inside code, using cobblestone as fuel or calling absent APIs. Self-verification occasionally misjudges success. Voyager has no visual perception in this version, so 3D building tasks need a human as the visual critic. The authors expect better models and grounding to chip away at these.
My assessment
Voyager got the central bet right, and the field has echoed it since. The durable idea isn't "use GPT-4 for Minecraft." It's that an agent's skills can live as an external, append-only library of verified programs, so competence compounds without any weight updates and old skills don't get forgotten because nothing overwrites them. The ablations are unusually honest and they point at the right culprits. Self-verification mattering more than the library is the result I'd least have guessed, and it's a useful warning: in an open world, knowing when you're done is harder and more important than knowing how to act.
Where the work is thinnest is grounding. The same model that gives the agent its broad competence also makes it ask for copper swords and feed cobblestone to a furnace, because it's reasoning from internet priors instead of the game's actual rules. The fixes the authors name, perception and a grounded curriculum, are exactly the load-bearing gaps, and leaning on humans as visual critics for 3D builds is an admission of that. The cost story is real but the least interesting limitation, since model prices fall. The three-trial sample size and the re-interpreted baselines mean the precise multipliers should be read as directional rather than exact. None of that dents the core. Store skills as code, verify before you save, and let composition compound, and an agent can keep getting better on its own.