Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
One algorithm that knows only the rules teaches itself chess, shogi, and Go from scratch by playing against itself, and beats the best handcrafted programs in each within a day.
Read at your level
Start where you're comfortable and climb as far as you like.
- For a 5-year-old
- For a high schooler
- For a college student
- For an industry pro
- For a PhD candidate
- For a peer researcher
Executive summary
For decades the strongest chess programs ran on two human-built parts. A scoring function that grandmasters tuned by hand told the program how good a position was, and a brute-force search that checked tens of millions of positions a second found the best move. AlphaZero throws both away. It starts knowing only the rules, plays millions of games against itself, and learns a single neural net that guesses a good move and scores a position. A search called Monte-Carlo Tree Search uses those guesses to look ahead, and the move the search settles on becomes the next thing the net learns to copy. The net and the search lift each other round after round. Starting from random play, AlphaZero beat the world-champion chess program Stockfish, the champion shogi program Elmo, and its own Go predecessor, all within 24 hours, while searching about a thousand times fewer positions per move than Stockfish. The honest cost is that this took 5,000 specialized chips to generate the self-play games, so the result is reachable but not cheap.
Try it
Load the Net is wrong scenario. The net's hunch points at move A, which is a losing move, and it barely backs move C, the real winner. Step the search a few times and watch it pile visits onto A and B. Now drag Exploration c_puct up to about 4 and keep stepping. The search starts probing C, finds the wins hiding under it, and the played move flips to C. Drop c_puct back near 0 and reset, and the search never escapes the bad hunch.
The prior loves move A, a loss. Move C is the real win but the prior barely backs it. Run enough simulations with healthy exploration and visits drift onto C. Starve the search and it plays the prior's mistake.
Step or play to start the log. Click an entry to rewind there.
This runs the paper's PUCT search over a fixed nine-node game tree, a stand-in for chess where the real tree holds millions of positions. The network's prior P and value v are hand-set per node so the patterns are legible; AlphaZero learns those numbers from self-play. The search reads the network's value at each leaf, not the true outcome, so a wrong, under-explored net plays the wrong move exactly as it would in the full game. The run is deterministic: same scenario and same controls always produce the same sequence of simulations.
For a 5-year-old
Imagine you're standing at the start of a forest with paths that split again and again. You want the path that leads to treasure. You can't see the whole forest, so you send little scouts down the paths to peek ahead and come back.
A wise owl sits on your shoulder and whispers which path looks best. The owl is usually right, so you send most of your scouts down that path. But you also send a few scouts down the other paths, just in case the owl missed something. Every time a scout comes back, you learn a little more, and you send the next scouts toward whichever path is looking best now.
After all your scouts come home, you pick the path you sent the most scouts down. That's your move.
Here's the magic part. At first the owl is just guessing, because nobody taught it anything. But every time you finish, you tell the owl which path actually won. So the owl gets smarter. And a smarter owl helps your scouts find treasure faster next time. The owl and the scouts keep teaching each other, over and over, until they're the best treasure-finders in the world.
The owl isn't a real bird and the scouts aren't real people. They're numbers inside a computer. But the idea is the same. Guess, peek ahead, learn from what won, and get better forever.
For a high schooler
You've used a phone app that suggests the next chess move or finishes your sentence. Old chess programs worked by raw speed. They checked tens of millions of board positions every second and used a scoring sheet, written by chess masters, to judge each one. More speed and a better scoring sheet meant a stronger program.
AlphaZero does something different. It has one neural network, which is a function that takes a board and spits out two things. First, a hunch about which moves are worth trying, called the prior. Second, a guess at who's winning, a number from minus one (I lose) to plus one (I win), called the value.
A network alone isn't enough, because its first guess can be wrong. So AlphaZero looks ahead with a method called Monte-Carlo Tree Search, MCTS for short. Think of it as the scout system. It runs many quick look-aheads from the current position, called simulations. Each simulation walks down the tree of possible moves, picking at every fork the move that balances three things: the network's hunch, how well that move has scored in earlier simulations, and a bonus for moves it has barely tried.
Here's a worked example with small numbers. Say move A starts with a hunch of 0.7 and move C with 0.1. Early on the scouts mostly walk down A. But suppose every time a scout reaches the end of A, it reports back a loss, while the few scouts that try C report wins. The average score for A drops, the average for C climbs, and soon the scouts shift to C. After 60 simulations, C has the most visits, so AlphaZero plays C, even though its first hunch was wrong.
The move that got the most visits becomes the answer, and that answer is what the network trains to copy next time. So the search fixes the network's mistakes, and the fixed network makes the next search sharper.
For a college student
You should care about this because it's the clearest demonstration that one general learning algorithm, with no game-specific knowledge, can beat systems that absorbed decades of human expertise. The same code, unchanged, mastered chess, shogi, and Go.
The setup is two pieces working as a loop. The first is a deep neural network with parameters that maps a board position to a move-probability vector and a scalar value.
(p, v) = f_θ(s)Here p is a distribution over legal moves (the prior) and v ≈ E[z | s] is the expected game outcome from position s, with z equal to plus one for a win, zero for a draw, minus one for a loss.
The second piece is Monte-Carlo Tree Search, which turns that rough network into a much stronger move-chooser. Each search runs many simulations. A simulation descends from the root, and at every node it picks the child that maximizes a score the paper inherits from AlphaGo Zero, the PUCT rule.
a* = argmax_a [ Q(s, a) + c_puct · P(s, a) · sqrt(Σ_b N(s, b)) / (1 + N(s, a)) ]Read it as two terms added together. Q(s, a) is the mean value backed up from all simulations that tried move a, the exploit term, which favors moves that have looked good. The second term is the explore term. P(s, a) is the network's prior, N(s, a) is how many times move a has been tried, and c_puct is a knob that sets how curious the search is. A move with a high prior and few visits gets a big bonus, so the search tries it. As visits pile up, that bonus shrinks, and Q takes over.
When a simulation reaches a position not yet in the tree, the network evaluates it once, and that value gets backed up the path the simulation took, flipping sign at each ply because a position good for me is bad for my opponent. After all simulations, the search returns a policy π proportional to the visit counts. Crucially, π is a better policy than the raw prior p, because the look-ahead corrected the prior's mistakes.
That gap is the whole engine. Training minimizes one loss over self-play games.
l = (z - v)² - πᵀ log p + c‖θ‖²The value head learns to predict the real outcome z, the policy head learns to copy the search's improved policy π, and the last term is weight regularization. Run this loop from random weights, and the net climbs from random play to superhuman because each search produces a target slightly better than the net that made it. This is policy iteration, where MCTS is the policy-improvement operator.
The simulation above runs this exact PUCT search on a tiny tree. Load Net is wrong, where the prior favors a losing move. With low c_puct the search exploits and never finds the win. Raise c_puct and the explore term pushes scouts down the neglected move until its hidden wins surface.
For an industry pro
The problem it attacks is the cost of domain expertise. A world-class chess engine is decades of hand-tuned evaluation features, opening books, endgame tables, and pruning heuristics, all specific to chess. AlphaZero replaces that pipeline with one network trained by self-play and a generic search. The same algorithm, with no changes, handled three different games.
What it costs to deploy is the catch. Training the chess net ran for 700,000 mini-batches over 9 hours, but it leaned on 5,000 first-generation TPUs to generate self-play games and 64 more to train the net. That's the bill for the "no human knowledge" headline. If you have a narrow problem and a working heuristic, the handcrafted route may still be cheaper. The win shows up when the domain is hard to hand-tune and you can afford the self-play compute.
The improvement over the incumbent is not marginal. In 100-game matches AlphaZero lost zero games to Stockfish and eight to Elmo, and it crossed Stockfish's level after 4 hours of training and Elmo's after under 2. It did this searching 80 thousand positions per second in chess against Stockfish's 70 million, roughly a thousandfold fewer. The lesson for a practitioner is that a learned value plus a focused search can beat brute force, because the net tells the search where not to waste time.
The failure mode to watch is when the net's value is wrong and the search is starved. The search trusts the net's leaf evaluations, so a confidently wrong net plus too few simulations plays the net's mistake. The fixes are more simulations per move and enough exploration in the search, which is exactly the trade you can feel in the simulation by starving the budget or dropping c_puct.
For a PhD candidate
The contribution is generality. AlphaGo Zero already showed tabula rasa self-play could master Go, but Go is unusually friendly to convolutional nets: translation invariant, defined by local liberties, rotationally and reflectionally symmetric, with binary outcomes. AlphaZero drops the parts of AlphaGo Zero that exploited those properties and still works on chess and shogi, which are position-dependent, asymmetric, full of long-range interactions, and can draw.
Three changes carry the generalization. AlphaGo Zero optimized the probability of winning under binary outcomes; AlphaZero estimates expected outcome to handle draws. AlphaGo Zero augmented training with the eight board symmetries and randomly transformed positions during MCTS; AlphaZero does neither, because chess and shogi lack those symmetries. And AlphaGo Zero used a best-player checkpoint, generating self-play from the best network seen so far and only promoting a challenger that won 55 percent of an evaluation match; AlphaZero maintains a single network updated continually, dropping the evaluation-and-gating step entirely. That last choice is the riskiest, since it removes the safeguard against a regression poisoning the self-play data, yet it held up.
The methodological choices reward scrutiny. The most striking result is the MCTS-versus-alpha-beta comparison. The field's settled belief was that minimax with alpha-beta pruning is inherently superior for chess, since earlier MCTS chess programs were weak. The paper's read is that alpha-beta propagates the largest approximation error of any leaf straight to the root, which is brutal when leaves come from a noisy nonlinear evaluator, whereas MCTS averages over a subtree and cancels much of that error. So a powerful but error-prone neural evaluator pairs better with averaging search than with minimax. The scaling-with-time plots back this up: AlphaZero's MCTS gained more from extra thinking time than Stockfish's alpha-beta did.
Threats to validity worth probing. The matches used fixed one-minute-per-move conditions with pondering off, and Stockfish ran with settings that its community argued were not its strongest, so the absolute margin invites debate even though zero losses is hard to wave away. Draws compress the chess Elo scale relative to shogi or Go, which flatters or deflates the chess curve depending on how you read it. And each game trained one network from one seed, so the run-to-run variance is unmeasured here. The open questions the paper names are whether the discarded handcrafted techniques could still help on top, and how far the single-network continual-update scheme generalizes beyond these three games.
For a peer researcher
The delta against AlphaGo Zero is that the algorithm stops depending on Go's structure. Strip the symmetry-based data augmentation, the symmetry averaging inside MCTS, the binary-outcome assumption, and the best-player gating, and what's left still reaches superhuman play in chess and shogi. The claim is that the self-play policy-iteration loop, MCTS as the improvement operator over a dual-headed net, is the general part, and everything Go-specific was incidental.
The choices read as deliberate tradeoffs. Continual single-network updates over the AlphaGo Zero best-player checkpoint trades a stability safeguard for simplicity and throughput; it worked, but the paper doesn't isolate how close it came to instability. Expected-outcome over win-probability is forced by draws and is clean. The decision not to transform positions during MCTS is forced by asymmetry and costs the variance reduction that symmetry averaging bought in Go.
What would change my mind on the headline. The provocative claim isn't "self-play works," it's that MCTS beats alpha-beta in chess given a neural evaluator, overturning a long-held belief. The argument that alpha-beta amplifies the worst leaf error while MCTS averages it away is mechanistically convincing, and the thinking-time scaling curves are the strongest evidence. If a comparison at equal compute and equally tuned opponents narrowed that gap, the architectural claim would weaken even though the self-play result would stand. The honest soft spots are the opponent-tuning disputes and the absence of seeds and variance, neither of which touches the central demonstration of generality.
How it works
The problem and why prior approaches failed. Strong chess and shogi programs share an architecture: a handcrafted evaluation function scores a position from features that human experts chose and tuned, and an alpha-beta search expands a huge tree, using domain-specific heuristics to prune branches and order moves. This works, but every piece is bespoke to the game and to human knowledge. Earlier attempts to learn the evaluator with a neural net, or to swap alpha-beta for MCTS, were weaker than the tuned handcrafted engines. So the bet that you could discard both human knowledge and alpha-beta and still win looked unlikely.
The key idea. Use one neural network for both jobs, the move prior and the position value, and use MCTS guided by that network as a policy-improvement operator. The search, looking ahead with the net's guidance, produces a better move distribution than the net alone. Train the net to copy that better distribution and to predict the game's real outcome. Repeat from random weights using games the system plays against itself.
Methodology. A single search runs many simulations. Each simulation has four phases.
select descend from the root, at each node taking
argmax_a [ Q(s, a) + c_puct·P(s, a)·sqrt(ΣN) / (1 + N(s, a)) ]
until reaching a leaf not yet in the tree
expand add that leaf's children to the tree
evaluate read (p, v) = f_θ(leaf) from the network once
backup add v to Q along the path taken, flipping sign each plyAfter the budget of simulations (800 during training), the search returns a policy π proportional to the root visit counts, and the move played is sampled from π during self-play or taken greedily at evaluation. The selection rule is the heart of it: the explore term c_puct·P·sqrt(ΣN)/(1+N) is large for high-prior, rarely-tried moves and shrinks as visits accumulate, so early simulations follow the net's hunch and later ones are governed by what actually scored well.
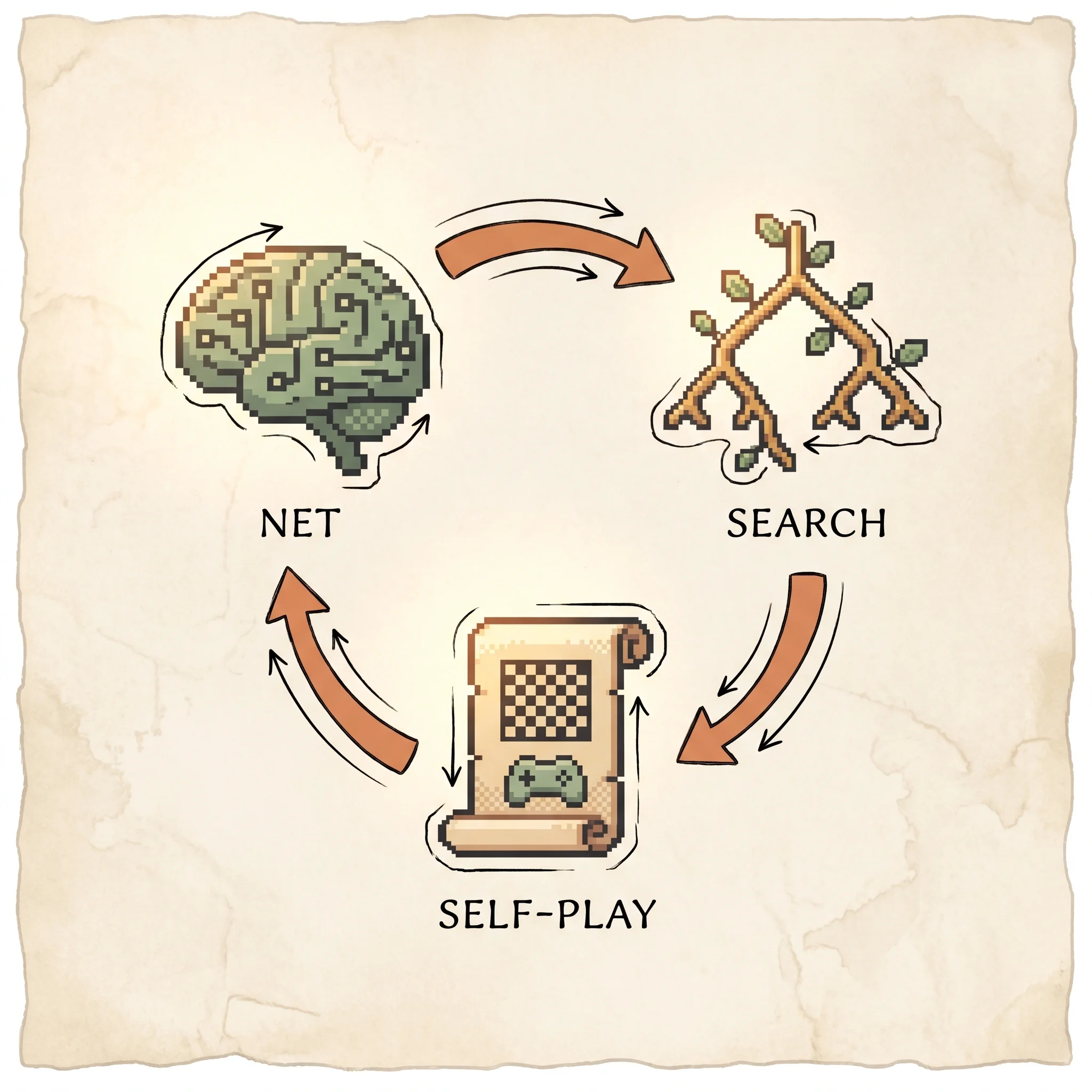
Training rolls all of this into one objective. Self-play games produce, for each position, the search policy π and the eventual outcome z. The net trains to match both.
(p, v) = f_θ(s)
l = (z - v)² - πᵀ log p + c‖θ‖²The only domain knowledge allowed is the rules: the board and move encodings as planes, the legal-move generator and terminal scoring used inside MCTS, and a count of typical legal moves used to scale the exploration noise. The net adds Dirichlet noise to the root prior in self-play so the search keeps exploring, scaled per game by how many moves a typical position has.
In the simulation, switch between Net is right and Hidden trap. When the net is right, a handful of simulations confirm the prior and play the best move. In the trap scenario, the surface-good move hides a refutation a ply deeper, and only a search that descends past the first reply backs the loss up and switches to the safe move.
Results with effect sizes. Trained for 700,000 steps, AlphaZero beat Stockfish in chess after 4 hours (300k steps), Elmo in shogi after under 2 hours (110k steps), and AlphaGo Lee in Go after 8 hours (165k steps). In 100-game matches it scored 25 wins, 25 draws, 0 losses as White against Stockfish and 3 wins, 47 draws, 0 losses as Black, lost zero overall. Against Elmo it lost 8 of 200. It searched 80 thousand positions per second in chess against Stockfish's 70 million, winning despite searching about a thousand times fewer positions, because the net focuses the search. Its MCTS also scaled better with thinking time than alpha-beta, which cuts against the belief that alpha-beta is inherently superior here.
Limitations and open questions. The compute to generate self-play games is large, thousands of TPUs. The matches drew disputes over opponent settings and time controls. The single-network continual-update scheme removes a stability safeguard and isn't stress-tested here. The paper leaves open whether the handcrafted techniques it discarded could still add value on top, and notes the head interpretability and the no-augmentation choice as places to push further.
My assessment
The authors got the central call right, and the field followed. The durable idea is that MCTS guided by a learned net is a clean policy-improvement operator, and wrapping it in self-play turns a random net into a superhuman one without a single human-tuned feature. Showing this on three games that demand different structure, with the same code, is what makes the "general" in the title earned rather than a flex.
The boldest and most contested claim is that MCTS beats alpha-beta given a neural evaluator. The mechanism they offer is the sharp part: alpha-beta's minimax sends the single worst leaf error straight to the root, while MCTS averages errors over a subtree and cancels them, so a noisy nonlinear evaluator wants averaging, not minimax. That reframing, more than the trophy, is the lasting contribution, and the thinking-time scaling curves support it better than any single match score.
Where the paper is fair to criticize is the evaluation. The Stockfish settings and the fixed time control drew real objections, and there's no reported seed variance, so the exact margin is softer than "zero losses" suggests. None of that dents the demonstration. A generic algorithm, knowing only the rules, taught itself to outplay the best programs humans built over half a century, and it did so by searching a thousand times less while thinking a thousand times better.