OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments
A real computer you can hand an AI agent any task on, then grade by running a script that checks the machine afterward, which shows agents plan well but miss the clicks.
Read at your level
Start where you're comfortable and climb as far as you like.
- For a 5-year-old
- For a high schooler
- For a college student
- For an industry pro
- For a PhD candidate
- For a peer researcher
Executive summary
People keep saying AI agents will run our computers for us. Nobody had a fair way to check. The tests that existed were either canned demos with no live machine behind them, or they were locked to one app like a web browser. OSWorld is a real computer in a virtual machine, on Ubuntu, Windows, or macOS, that you can hand any task. It ships 369 real tasks across web apps, office apps, coding, and file work, including jobs that span several apps at once. Each task starts the machine in a set-up state, lets the agent drive the real mouse and keyboard, and then runs a custom script that checks the machine afterward to decide pass or fail. The result is blunt. Humans finish 72.36% of these tasks. The best agent finishes 12.24%, and on tasks that need several apps it drops below 5%. The agents can write the right plan. They just can't reliably click the right pixel, and more than three out of four failures are exactly that.
Try it
Load Single-app, a11y tree and press play a few times. Some seeds finish the short task, many miss a click and stall. Now load Multi-app workflow and watch the same kind of agent burn its step budget before it ever finishes, because the task needs far more clicks. Then load Shrink the window, step once so the first click lands, and hit the Window shrunk button mid-run. The landing gauge craters and the same plan starts missing.
The agent's best shot. A short Chrome task with the accessibility tree. Run it a few times; some seeds finish, many still miss a click and stall.
A short single-app task. Open settings, find the site data, delete it. Few clicks, so a decent grounding rate often gets through.
How the agent sees — observation modeWindow state — perturb mid-run to watch the gauge dropStep or play to start the agent loop.
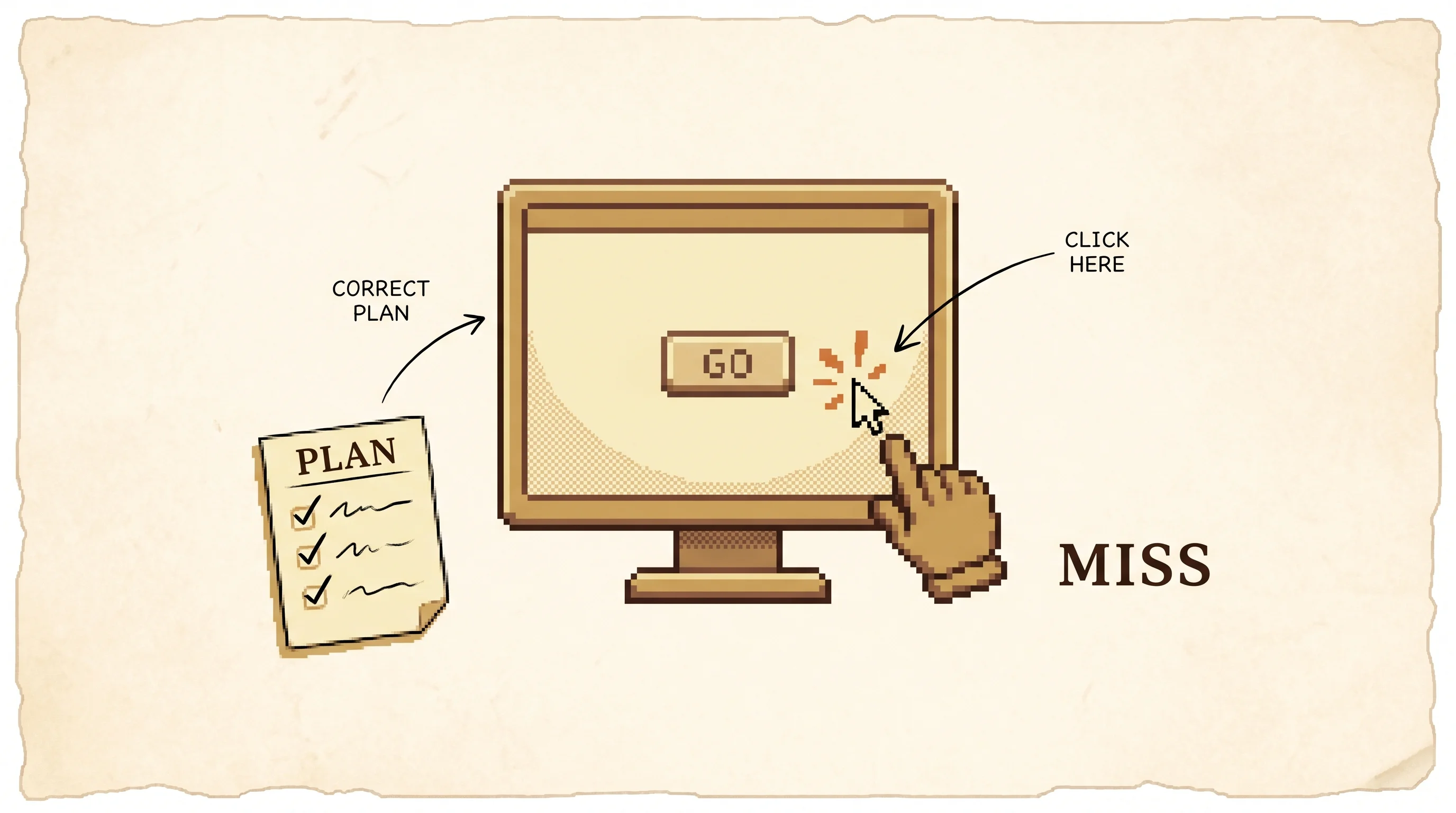
The plan here is always right, because the paper's agents plan well and fail at grounding, so the only question each step is whether the click lands. The landing chance comes from the paper: the observation mode sets the base rate near Table 5's overall numbers (a11y tree beats raw screenshot), and each window perturbation scales it by the drop Figure 8 measured (original 50.79%, moved 36.65%, shrunk 15.04%, cluttered 25.39%). A real agent's accuracy comes from the model; here it is a fixed rate so the loop is legible. Each preset uses a fixed seed so the run is deterministic; press “New sample” to try a different trajectory.
For a 5-year-old
Imagine a robot helper sitting at a computer. You give it a job, like "throw away the old cookies the computer saved." The robot is smart. It knows exactly what to do, step by step, in the right order.
But the robot has shaky hands. To do anything on a computer you have to point your finger at the exact right spot and tap. The robot keeps tapping just a little bit off. It taps next to the button instead of on it. Sometimes when it taps the wrong place, a surprise window pops up, and now the robot has to close that too before it can get back to work.
So the robot knows the plan but keeps poking the wrong spot. A grown-up doing the same job gets it right almost every time. The robot only finishes about one job out of every eight it tries.
It gets worse when a job needs lots of taps. Every tap is another chance to slip. A short job with a few taps, the robot sometimes gets through. A long job with many taps across different programs, it almost never makes it to the end before it runs out of tries.
The robot doesn't really have hands or eyes. It looks at a picture of the screen and guesses where to tap with numbers. But the feeling is the same. It plans like a champ and taps like it's wearing oven mitts.
For a high schooler
You've watched a phone autocomplete your texts. That model is good at deciding what word comes next. Now picture a model that's supposed to run a whole computer for you. It has to look at the screen, decide what to do, and then actually do it by moving the mouse and typing.
To test something fairly, you need an environment, which means a real working version of the thing you're testing, not a recording of it. A driving test uses a real car on a real road, not a slideshow of roads. OSWorld is a real computer running inside a safe sandbox, so the agent's clicks have real consequences and you can check what actually happened.
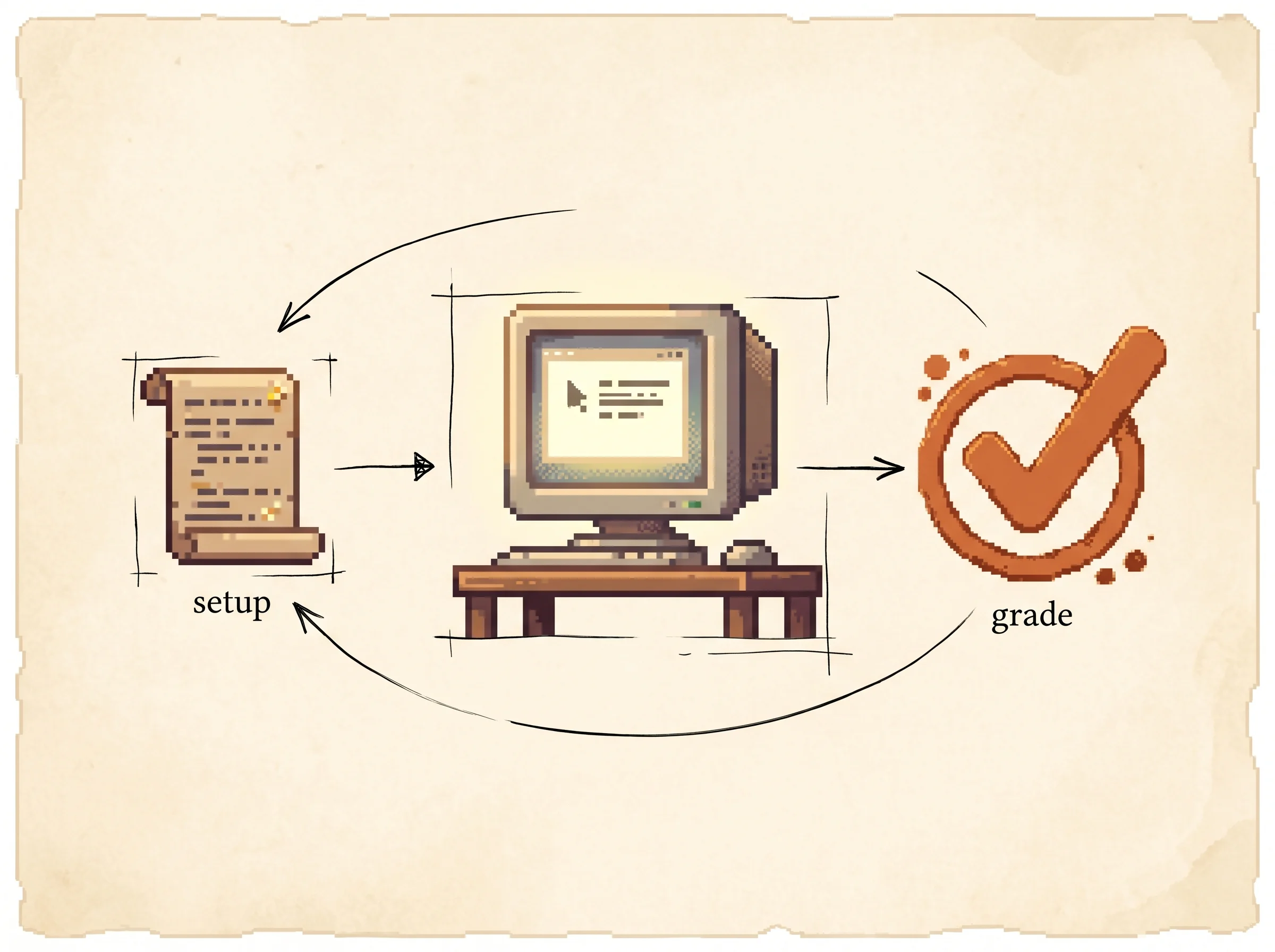
Every task works the same way. The computer gets set up in a starting state, like a spreadsheet already open with some rows in it. The agent looks at the screen and writes a line of code that moves or clicks the mouse, the same kind of command a person could type. The computer runs that command. This repeats until the agent says it's done or hits a limit of 15 tries. Then, and this is the clever part, a checking script looks at the real computer afterward and decides if the job got done. Not "did the agent pick the answer we expected," but "is the file actually renamed, are the cookies actually gone."
A regular person finishes about 72 of every 100 tasks. The best AI agent finishes about 12 of every 100. When the experimenters looked at why agents fail, more than 75 out of every 100 failures were the agent clicking the wrong spot. It had the right idea and missed the target.
The agent plans well and aims badly, and a computer doesn't forgive bad aim.
For a college student
You should care about this because everyone is building "computer-use agents" now, and OSWorld is the benchmark that exposed how far they have to go. The motivation is honest measurement. Before it, agent benchmarks were either static datasets of recorded demonstrations, which punish any correct solution that differs from the one recorded, or they were live but boxed into a single domain like web browsing. Neither one tests an agent that has to open the terminal, find a file, and paste a result into a spreadsheet.
The setup is a partially observable Markov decision process. The agent never sees the full machine state, only an observation, and it acts through code.
task = (S, O, A, T, R)
S full machine state (hidden)
O observation: a screenshot and/or a filtered accessibility tree
A a pyautogui action, e.g. click(300, 540) or hotkey('ctrl', 'c')
T the real VM transitions the state when it runs the action
R an execution-based script grades the final state, returns 1 or 0Walk it left to right. The agent gets an observation, emits one action as a Python string, and the virtual machine executes it for real. The loop runs until the agent emits DONE or FAIL, or it hits the 15-step cap. The reward is the part that makes this trustworthy. Instead of comparing the agent's action to a stored "correct" action, OSWorld runs a task-specific script on the machine afterward. For "delete the Amazon cookies," the script reads the browser's cookie store and checks they're gone. There are 134 of these unique evaluation functions, so the benchmark grades the outcome, not the path.
The result is the gap. Humans score 72.36% overall. The strongest agent configuration, GPT-4 reading an accessibility tree, scores 12.24%. Raw screenshots alone drop to about 5%. The reason is grounding, which means turning "click the Save button" into the exact pixel coordinate of that button. Vision-language models are weak at it. The authors found more than 75% of failures are mouse-click inaccuracies, and a second failure they call the environmental noise dilemma, where a stray click opens a pop-up the agent then doesn't know how to close.
The limitation falls out of the math. A multi-step task succeeds only if every grounded action lands. If each click lands with probability p below 1, and a task needs k clicks, the chance of finishing decays like p^k. That's why single-app tasks score 13.74% while multi-app workflows score 6.57%. More steps, more chances to miss, and the agent burns its 15-step budget on repeated misclicks.
For an industry pro
The problem this solves for you is that you have no honest way to know whether a computer-use agent will do real work. Demos look great. OSWorld measures the thing demos hide, which is whether the agent actually changes the machine the way the task needs, checked by a script that inspects the result.
What it costs to take seriously is reading the numbers, not the press release. The best agent here finishes 12.24% of tasks against a human 72.36%. On workflows that touch more than one app, the kind of automation people actually want, agents are under 7%. The single biggest failure is grounding. The agent writes correct steps with correct code comments, then clicks the wrong coordinate. Plan good, aim bad. Budget for that gap before you wire an agent into anything that mutates real data.
The operating envelope has sharp edges worth knowing. First, observation mode changes everything. Feeding the accessibility tree, which carries element labels and rough positions as text, roughly doubles success over raw screenshots, but that tree can run past 6000 tokens for one screen, so you pay in context length and latency. Second, agents are brittle to the screen drifting from what they expect. On a subset agents handled at 50.79%, moving the window dropped them to 36.65%, shrinking it to 15.04%, and adding clutter to 25.39%. A UI update on the apps you target can quietly tank a deployed agent. Third, the cost compounds with task length, so short single-purpose tasks are where these are least bad today.
One more thing the paper checked that you'll want. They ran the same agent on Ubuntu and on Windows after migrating tasks, and performance correlated at 0.7, so insights transfer across operating systems with decent reliability.
For a PhD candidate
The contribution is a controllable, execution-based, cross-application benchmark of real computer use, which prior work couldn't offer all at once. Static benchmarks like Mind2Web and AitW give recorded trajectories with no executable environment, so they assume a single correct solution and miss interactive learning. Executable ones like MiniWoB++, WebShop, and WebArena are live but confined to web or to isolated synthetic UIs. OSWorld is a real OS, runs arbitrary apps, scores by inspecting the final machine state with 134 distinct evaluation functions, and explicitly includes cross-app workflows and infeasible tasks. Table 4 in the paper is the clean comparison, and OSWorld is the only row with checks in every column.
The methodological choices reward scrutiny. The execution-based reward is the core bet. Rather than match a predicted action against a golden action, they wrote per-task getter functions that pull the relevant artifact, a cookie store, a saved spreadsheet, an accessibility subtree, and evaluator functions that judge it. That costs about 2 man-hours per task and 1800 total, but it buys evaluation that doesn't penalize alternative correct solutions and that handles open-ended tasks. The observation space deliberately offers screenshot, accessibility tree, both, and Set-of-Mark, because the authors wanted to separate perception from grounding from reasoning, and the ablations show those input choices swing success by more than 2x and even reverse rankings between models.
Threats to validity worth probing. Human performance, 72.36%, comes from CS students unfamiliar with the specific software, on a setup sampled against 100 WebArena examples, so it's a strong but not exhaustive ceiling. The window-perturbation finding, the most striking robustness result, is measured on a 28-task subset the agents already handled well, so it's a targeted probe rather than a benchmark-wide claim. And the headline 12.24% is one configuration; the spread across configs is wide enough that "the best agent gets 12%" hides a lot of variance. The obvious follow-ups, which the field then chased, are stronger GUI grounding, longer and cheaper context for the accessibility tree, image-based history that actually helps, and agent architectures with real memory and reflection.
For a peer researcher
The delta against WebArena and the static-trajectory benchmarks is that OSWorld is a real OS, not a browser or a recording, with cross-app tasks and execution-based scoring over the actual machine state. That combination is what lets it surface the plan-versus-execute split that single-domain benchmarks blur. The agents reason competently and ground incompetently, and a real desktop is unforgiving of bad grounding in a way a constrained web action space isn't.
The choices read as deliberate tradeoffs. Execution-based reward trades annotation cost, 1800 man-hours and 134 evaluators, for evaluation that doesn't punish alternative correct solutions and scales to open-ended tasks. Intermediate initial states trade extra setup engineering for realism, since most real assistance happens mid-activity, not from a clean boot, and the paper shows that realism is itself a difficulty multiplier. Offering four observation modes trades a clean single-input story for the ability to decompose perception from grounding, which is where the most interesting variance lives.
What would change my mind on the central claim that current VLMs are far from being computer agents. If a model matched human grounding accuracy on raw screenshots, the screenshot-only number would climb toward the a11y-tree number and the framing would soften. It didn't. The honest soft spots are that the human ceiling rests on a modest sample and the robustness result on a 28-task subset. The open question the paper leaves wide is the one the next wave took up, which is whether grounding is a pretraining problem, a fine-tuning problem, or an architecture problem, and the cross-OS correlation of 0.7 hints the answer transfers across platforms.
How it works
The problem and why prior approaches failed. A computer-use agent has to perceive a screen, plan, and act through a real interface, across whatever apps the task needs. Prior benchmarks couldn't test that whole loop. Static datasets like Mind2Web and AitW are recorded demonstrations with no live environment, so they grade by matching the agent's step to the one recorded, which wrongly fails any other correct solution and can't support interactive learning. Live benchmarks like MiniWoB++, WebShop, and WebArena run real but only inside a web browser or a synthetic UI, so they can't pose a task that opens a terminal, edits a file, and pastes into a spreadsheet.
The key idea. Make the benchmark a real operating system in a virtual machine, and grade by running a script that inspects the machine after the agent finishes. The agent sees an observation, emits a pyautogui action, the VM executes it, and a task-specific evaluation function checks the final state for pass or fail.
Methodology. The environment runs on a host, and a Coordinator boots a VM from a snapshot, runs a config to set the initial state, then steps the agent loop. The config has three jobs, set up the files and window layout, post-process after the agent stops, and fetch the artifacts the grader needs.
config -> Setup Interpreter -> VM snapshot in starting state
loop: observe (screenshot + a11y tree) -> agent emits pyautogui action
-> VM executes -> repeat until DONE/FAIL or 15 steps
end: Postprocess -> Getter pulls artifacts -> Evaluation Interpreter -> rewardThe action space is real mouse and keyboard through pyautogui, like click(x, y), dragTo(x, y), hotkey('ctrl', 'c'), plus three special actions, WAIT, FAIL, and DONE. Because actions are Python, the agent can wrap them in loops, which widens what one action can express. The observation space offers a full screenshot, an XML accessibility tree filtered down to tag, name, text, position, and size, or both, plus a Set-of-Mark variant that draws numbered boxes on the screenshot so the agent picks a box index instead of a raw pixel. The benchmark is 369 Ubuntu tasks plus 43 on Windows, with 268 single-app, 101 multi-app workflows, and 30 deliberately infeasible tasks to test whether agents know when to give up.
Window perturbations. The sharpest robustness finding. On a 28-task subset agents handled at 50.79%, the authors disturbed the window and watched success fall. The simulation above applies these exact drops as a multiplier on the landing chance.
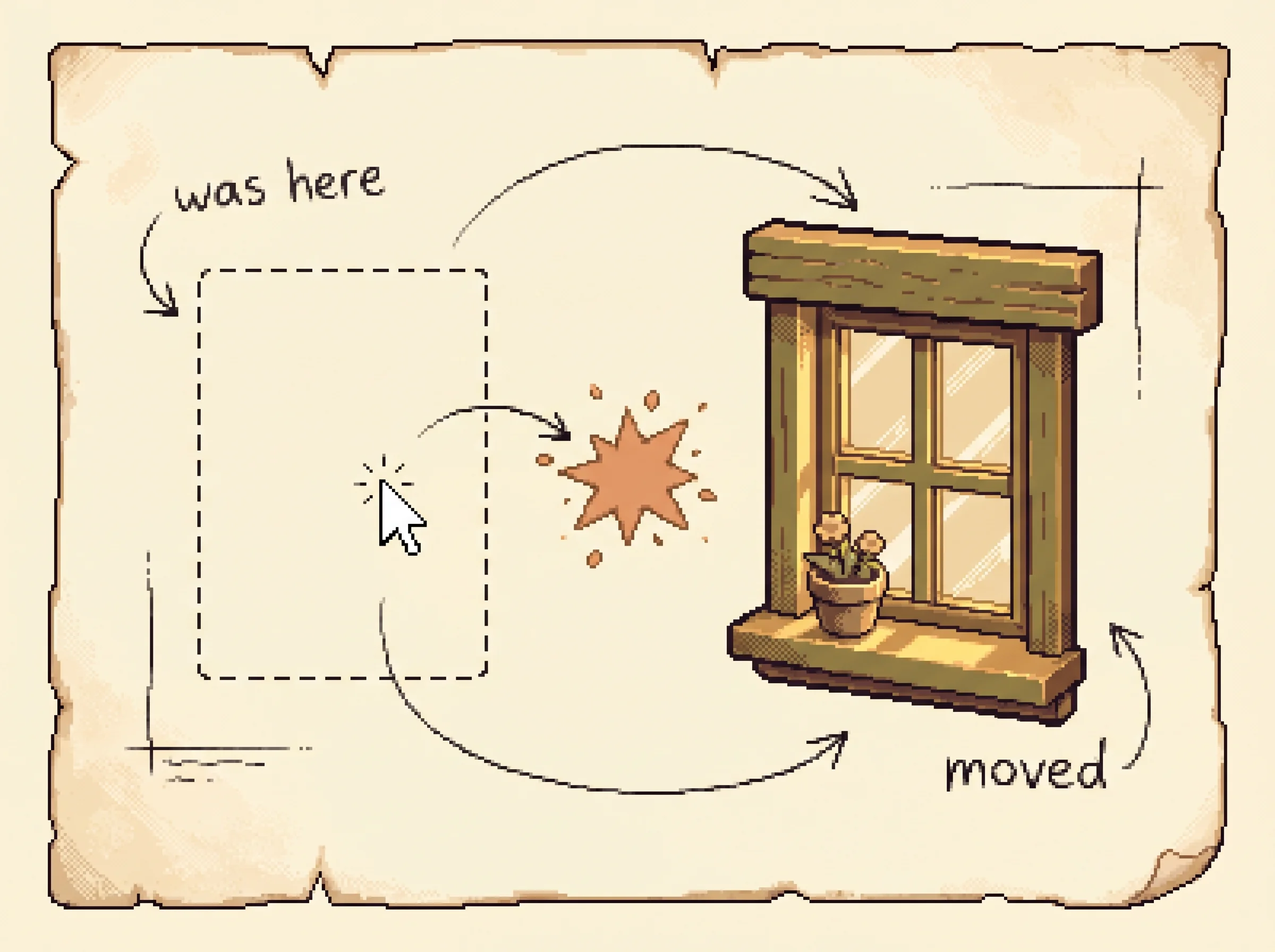
| Window state | Success rate |
|---|---|
| Original layout | 50.79% |
| Window moved | 36.65% |
| Window shrunk | 15.04% |
| Screen cluttered | 25.39% |
Load the Shrink the window preset, step once, then press Window shrunk mid-run to watch the same plan start missing.
Results with effect sizes. Humans finish 72.36% overall. The strongest agent, GPT-4 on the accessibility tree, finishes 12.24%. Screenshot-only configs land near 5.26% to 5.80%. Single-app tasks score 13.74%, multi-app workflows 6.57%, so doubling the apps roughly halves success. Task difficulty graded by human completion time tells the same story, 16.78% on easy tasks down to 4.59% on hard ones. More than 75% of failures are mouse-click inaccuracies. Higher screenshot resolution helps, longer text history helps, but longer image history doesn't, which says these models read structured text better than they read their own past screenshots.
Limitations and open questions. Self-attention over the observation is quadratic, and the accessibility tree's 90th percentile is 6343 tokens for one screen, so feeding it is expensive and the screenshot path that scales better is also the weakest today. The human ceiling rests on a modest sample, and the window-robustness result on a 28-task subset. The authors leave the central question open, whether to fix grounding in pretraining, fine-tuning, or the model architecture, and call for purely vision-based agents that don't lean on the accessibility tree.
My assessment
The authors got the framing right, and the field proved it. OSWorld became the reference benchmark for computer-use agents almost immediately, and the gap it exposed, strong planning and weak grounding, is exactly the gap the next two years of work attacked with grounding-focused pretraining and dedicated click models. The execution-based reward was the right expensive choice. Matching predicted actions to golden ones would have hidden the truth, because an agent can take a different correct path, and checking the final machine state is the only honest grade for open-ended work.
Where the paper is appropriately humble is the human ceiling and the robustness probe, both of which rest on small samples, and they say so. The cleverest single result is the window perturbation, because it isolates a failure that has nothing to do with reasoning. The agent memorizes a coordinate from a layout and a tiny shift makes that memory wrong, which tells you the weakness is perception and grounding, not planning. The weakest part of the story is that the headline 12.24% compresses a wide spread across configurations, so the number is best read as "the best of many tries, still terrible" rather than a stable capability. None of that dents the contribution. OSWorld made the right thing measurable, and the measurement was unflattering enough to be useful.