Efficient Selectivity and Backup Operators in Monte-Carlo Tree Search
Grow a game tree one random playout at a time, steer each playout toward the move most likely to be best so you never fully give up on anything, and read each node's value as a blend that slides from the average toward the best as the playouts pile up.
Read at your level
Start where you're comfortable and climb as far as you like.
- For a 5-year-old
- For a high schooler
- For a college student
- For an industry pro
- For a PhD candidate
- For a peer researcher
Executive summary
Computers got good at chess by reading deep and scoring positions with hand-built rules. That trick failed at Go, where good rules are hard to write and every position stays in motion. One workaround was Monte-Carlo evaluation: judge a move by playing it out to the end with random moves many times and averaging who wins. This paper fuses that idea with tree search into one loop. Each round runs a single random playout, steered down the tree toward the move most likely to beat the current best, and feeds the result back up. Nothing ever gets pruned to zero, so a move that looks bad early still gets probed and can recover. And each node reports a value that starts as the plain average of its playouts and slides toward the best of its children as the playouts pile up, since the average is right when samples are few and the best is right when they're many. This became Monte-Carlo Tree Search. The program built on it, Crazy Stone, won the 10th KGS computer-Go tournament. The honest weakness is that it leans on hand-tuned formulas and a primitive uncertainty estimate, and the authors say a global tree like this won't scale to a full 19 by 19 board.
Try it
Load Coulom: find the gem and press play. Move C is the best move, but its playouts are noisy, so A looks better at first. Watch C climb past A as the playouts settle and the solid clay ring lands on C. Then load Pruning kills the gem and play it. Progressive pruning cuts C off after a few unlucky playouts, the indicator flips to "recommends a worse move," and the search settles on A forever. Switch the backup to Max mid-run on the first preset and watch the root value jump too high.
Coulom selectivity with the mix backup on the hidden-gem tree. Run it and watch move C overtake A as its noisy rollouts settle.
Flip a control or load a preset to start the log, then click an entry to rewind.
Each tick runs one full simulation: descend by the selectivity rule, expand a node, run a rollout, and back the value up. The rollout value of a move is sampled around a hidden true value with that move's noise, so a good move with wide noise can look bad at first. The dashed sage ring marks the move with the highest true value; the solid clay ▶ ring marks the move the search would play now; a red ✕ marks a pruned move. Each preset uses a fixed seed so the run is deterministic and reproducible. This runs a 4-move tree a few plies deep, where Crazy Stone ran thousands of moves on a 9 by 9 board.
For a 5-year-old
Imagine you're digging for treasure in a sandbox. There are a few spots you could dig. You don't know which spot has the gold, so you grab a shovel and take a quick scoop from one spot. Maybe you find a shiny rock. That's a good sign. So you scoop that spot again. And again. The spots that keep giving good stuff, you dig more. The spots that give junk, you dig less.
But you never stop digging a spot all the way. Here's why. Sometimes the best spot is deep down, and your first few scoops just hit plain dirt. If you quit too soon, you walk away from the gold. So you always take a few more scoops everywhere, just in case.
When you want to guess how good a spot is, you have two ways. Early on, you just take all your scoops and average them, because a few lucky or unlucky scoops shouldn't fool you. Later, once you've dug a spot a lot, you trust your single best find, because by then you really know what's down there.
Real diggers don't have shovels here. The digging is a computer playing the game out to the end with random moves, over and over, and counting who wins. But the feeling is the same. Dig the good spots more, never give up on any spot, and slowly learn where the gold is.
For a high schooler
You've used a phone that suggests the next word. Now picture a game like tic-tac-toe but much bigger, where the computer has to pick a good move. It can't check every future, there are too many. So it guesses smart instead.
Here's the one new idea for this section. A playout is one full game played from the current spot to the end using random moves, which tells you who would win that one time. One playout is noisy. A move might win a random playout by luck. So you run many playouts and keep score for each move: how many times you tried it, and how often it won.
Now the clever part, in three steps. First, you don't spread your playouts evenly. You spend more of them on the move that looks most likely to be the best, because that's the move whose true value matters most. Second, you never set a move's chance of being tried to zero, even if it looks bad, so a move with bad early luck can still bounce back. Third, when you score a move, you blend two numbers: the average of its playouts and the value of its best follow-up.
Here's a worked example with small numbers. Say move A won 6 of 10 playouts, so 60 percent. Move C won only 3 of its first 10, so 30 percent, and you'd ignore it. But C's playouts swing wildly, sometimes a blowout win, sometimes a blowout loss, while A's are steady around 60. That wild swing is the tell. Keep giving C playouts and its average climbs to 70 percent, because C really is better. It just took more digging to see it.
The whole search is that loop run thousands of times: pick a promising move, play it out, update the scores, repeat.
For a college student
You should care about this because it's the paper that introduced Monte-Carlo Tree Search, the search method behind the Go programs that eventually beat the best humans. Everything from later UCT and AlphaGo-style search traces back to the loop defined here.
The setup is a two-player, zero-sum, perfect-information game. The old approach was alpha-beta search with a hand-built static evaluator at the leaves, which works for chess but fails for Go because good static evaluators for Go are hard to build and positions rarely sit still. Monte-Carlo evaluation replaces the static score: to judge a position, play many random games from it to the end and average the results. This paper's contribution is to grow a search tree and run Monte-Carlo evaluation in one interleaved loop, instead of a separate min-max phase and Monte-Carlo phase.
The loop has four steps per simulation:
loop:
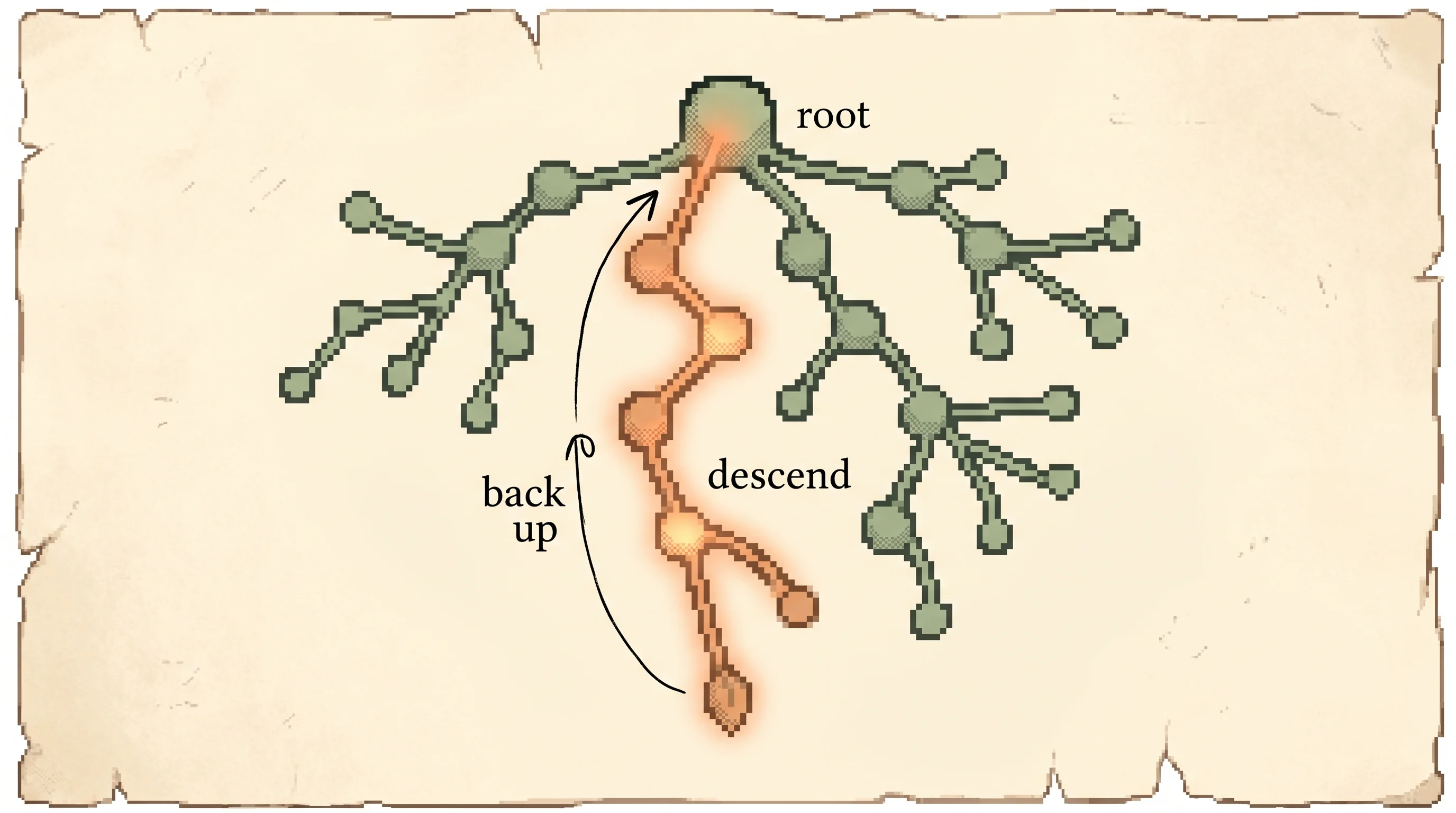
1. Descend from the root, at each node picking a child by the selectivity rule,
until you reach a node not yet expanded.
2. Expand that node (create a child the second time the node is visited).
3. Simulate a random playout from the new leaf to the end; it returns a value.
4. Back up the value to every node on the path, updating mean and variance.The tree stays partial. Only nodes near the root are stored, and a node's children are created the second time it's visited, so memory stays bounded.
The two interesting pieces are how you descend and how you back up.
Selectivity (how you descend). At each node you allocate the next simulation to the move most likely to be better than the current best, because that's the move whose value would change the backed-up answer. Order the moves so their estimated values run μ₀ > μ₁ > ... and pick move i with probability proportional to
u_i = exp( -2.4 · (μ_0 - μ_i) / sqrt(2·(σ_0² + σ_i²)) ) + ε_iThe exponential is a smooth approximation of the probability that move i beats the best move, given their means and variances. A move that's far below the best, or whose value is pinned down tightly (small σ), gets a small urgency. The ε_i term is a floor that keeps every urgency above zero, so no move is ever fully abandoned.
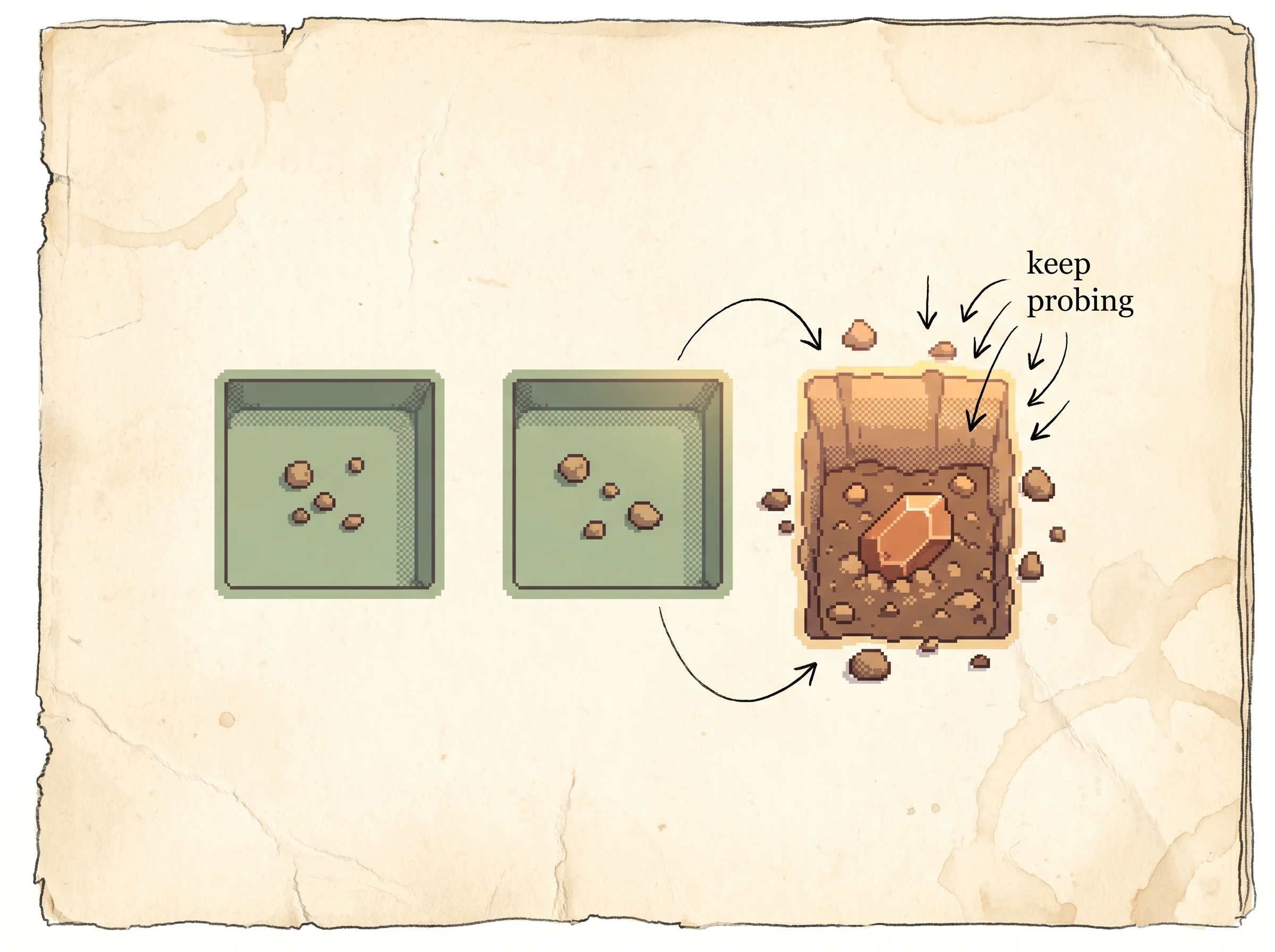
That floor is the whole point of "selectivity" over hard "pruning." Earlier methods cut a move off for good once it looked bad. The danger, which the paper names directly, is that the central limit theorem doesn't really apply inside a tree, because as the tree grows the move probabilities shift and the playout outcomes aren't drawn from one fixed distribution. A move can look weak until a deeper search uncovers a killer follow-up. Cut it early and you lose it. Keep a floor under it and the search can come back.
Backup (how you score a node). A leaf you've barely visited uses the plain mean of its playouts, value = Σ/S. But a well-visited internal node shouldn't use the mean, because the mean of a node mixes in its bad moves, and once you've searched a lot you'll only ever play the best move from here, so the node is worth roughly the value of its best child. The fix is an operator that slides from one to the other.

Early, with few playouts, the mean is the honest estimate, because the best-looking child might just be lucky and taking the max would overestimate. Late, with many playouts, the best child is the honest estimate, because you've confirmed which one it is and you'll only play that one. The paper's "Mix" operator is a weighted blend of the robust max and the mean whose weight shifts toward the max as the visit count grows, which the experiments found beats either extreme.
One worked path, end to end. Start with one root node and its candidate moves. Run a simulation: descend by urgency to move C, find it unexpanded, expand it, play a random game from there, get a loss, back it up. C's average dips, so its urgency drops a little, but not to zero. Keep going. Most simulations go to A, which looks best, but a steady trickle still reaches C. C's wins start landing, its average climbs, its urgency rises, and the root's backed-up value, blended toward the best child, settles on C's true worth.
The limitation is structural. The tree is global and grows from the root, so it scales to a 9 by 9 board but, the authors say, not to a full 19 by 19 one.
For an industry pro
The problem this solves is search in a domain where you can't write a good static evaluator. If you can simulate a rollout cheaply but can't score a position by hand, this gives you an anytime, best-first search that improves smoothly with every simulation and points its compute at the moves that matter.
Three properties make it deployable. It's anytime: every simulation backs information up to the root immediately, so you stop whenever your time budget runs out and take the current best move, no fixed depth or iteration boundary. It's tunable at the grain of a single simulation, not whole branches, so you get fine control over where compute goes. And because no move's probability ever hits zero, it stays convergent: given enough time it finds the best move, unlike hard pruning, which can lock in an early mistake.
The cost is twofold. First, it leans on hand-tuned constants. The 2.4 in the urgency formula, the ε floor, the mix weights, and Crazy Stone's Go-specific rollout heuristics were all set empirically by trial and error, so porting this to your domain means retuning. Second, the uncertainty backup is crude. The authors back up variance as σ²/min(500, S) and call it "an extremely primitive and inaccurate way to backup uncertainty." If your selectivity depends on good variance estimates, that's the weak link to fix first.
The expected payoff was real. Crazy Stone won its tournament and beat Indigo, a strong Monte-Carlo Go program of the era, in a 100-game match, while still losing to the knowledge-heavy GNU Go at equal time. The failure mode to plan around is long tactical lines: the wins came from better global judgment, the losses from deep tactics like ladders that the random rollouts miss. And the scaling ceiling is hard. A single global tree from the root does not stretch to a 19 by 19 board.
For a PhD candidate
The contribution is a single interleaved framework that drops the separation between a min-max phase and a Monte-Carlo phase, with two coupled ideas: simulation-level selectivity that never prunes to zero, and a backup operator that interpolates between averaging and max as a function of visit count.
The selectivity descends from the algorithm of Chang, Fu and Marcus and the n-armed bandit literature, but the paper is careful about why those frameworks don't transfer cleanly. Bandit objectives minimize regret, the count of pulls of suboptimal arms, which is the wrong objective here, since searching a bad move costs nothing as long as the right move is finally chosen. Discrete stochastic optimization is closer, since it optimizes the final decision, but its objective of maximizing the probability of selecting the best move is only right at the root. Inside the tree the objective is an accurate backed-up value, which is why Coulom allocates by probability-of-being-best rather than by Chen's equal-allocation rule. The urgency formula is a Gaussian approximation tuned with the 2.4 constant, plus an ε floor that preserves convergence by keeping every move's probability positive.
The backup analysis is the sharper part. Pure max backup, the Chang-Fu-Marcus negamax limit, overestimates, because the expected maximum of noisy estimates exceeds the max of the true values; pure mean underestimates, because it averages in the bad moves. The paper measures both: Table 1 reports mean squared error and bias across simulation counts and confirms the mean is biased low, the max biased high, the mean better at low counts and the max better at high counts. The robust max, returning the value of the most-simulated child rather than the highest-valued one, hedges against backing up a lucky low-count move, an idea shared with Alrefaei and Andradottir's simulated annealing. The "Mix" operator combines robust max and mean with refinements for the case where the mean exceeds the max, which can happen under non-stationarity, and it was tuned by a temporal-difference-style procedure: sample 1,500 self-play positions, record the estimate every 2ⁿ simulations, and fit the operator so the estimate after 2ⁿ matches the estimate after 2ⁿ⁺¹.
Threats to validity worth probing. The constants and the rollout heuristics are empirical and Go-specific, so the generality claim rests on the framework, not the numbers. The variance backup is admittedly primitive, σ²/min(500, S), which undercuts the selectivity that depends on it. The headline result is a 9 by 9 tournament win plus a 100-game match against one Monte-Carlo opponent, with luck acknowledged as a factor in the 6-round tournament. And the central limit assumptions behind the urgency formula are known to be violated inside the tree, a tension the paper flags but does not resolve.
For a peer researcher
The delta against Bouzy's iterative-deepening Monte-Carlo Go and against the Chang-Fu-Marcus adaptive sampling is that selectivity and backup move to the grain of the individual simulation, and that the backup is a tunable interpolation rather than a fixed mean or a fixed negamax. Bouzy grew a tree by deepening and pruned the worst moves between iterations, which surfaces information only at iteration boundaries and can prune a good move permanently. Here every simulation backs up to the root immediately, which buys the anytime property, and the ε floor keeps the method convergent where progressive pruning is not.
The choices read as deliberate tradeoffs. Allocating simulations by probability-of-being-best rather than by a regret or equal-allocation rule is the right objective for an accurate backed-up value but wrong for the root decision, a distinction the paper makes explicit and leaves as an open lever, suggesting a discrete-stochastic-optimization rule at the root specifically. The mean-to-max interpolation is the empirical answer to a real bias-variance problem in the backup, and Table 1 is the evidence: neither pure operator dominates across simulation counts, so the operator that slides between them wins.
What would change my mind on the framing. If a fixed backup operator matched the mix's error profile across the full range of simulation counts, the interpolation would be unnecessary complexity, but the table says it doesn't. The honest soft spots are the primitive variance backup and the hand-tuned constants, and the open question the paper leaves wide, scaling beyond a global root tree, is exactly where the field went next, first with UCT's principled bandit rule replacing the hand-tuned urgency, then with learned rollouts and value networks replacing the random playouts entirely.
How it works
The problem and why prior approaches failed. Strong game programs paired alpha-beta search with a hand-built static evaluator at the leaves. That works where you can write a good evaluator and stop search at quiet positions, like chess. Go breaks both assumptions: static evaluation is hard, and positions stay dynamic so there's no quiet place to stop. Monte-Carlo evaluation sidesteps the evaluator by playing random games to the end and averaging, but early Monte-Carlo Go either ran flat, with no tree, or split the work into a min-max tree phase and a separate Monte-Carlo phase, and the selective ones pruned moves they could never recover.
The key idea. Run one loop that grows a tree and runs Monte-Carlo evaluation together. Each simulation descends the tree by a selectivity rule, expands a node, plays a random game from there, and backs the result up the path. Allocate simulations toward the move most likely to be best, keep every move's probability above zero so nothing is lost, and score each node with an operator that slides from the mean toward the best child as visits grow.
Methodology. Start with one node at the root. Whenever a playout passes through an already-visited node, create a child for its next move if one doesn't exist, which keeps the stored tree near the root and bounded. Below a visit threshold a node is "external" and uses the plain mean Σ/S; above it the node is "internal" and uses the backup operator. The external-node variance carries a high-variance virtual prior so rarely-explored nodes read as genuinely uncertain:
σ² = (Σ₂ - S·μ² + 4·P²) / (S + 1)Selectivity picks the next move by the urgency u_i above, whose exponential approximates the probability that move i beats the current best and whose ε floor keeps every move alive. The backup tries four operators: mean (underestimates), max (overestimates), robust max (the value of the most-visited child), and the mix that blends robust max and mean with a weight that shifts toward the max as the visit count grows.
external node: value = Σ / S
internal node: value = mix( mean, robustMax ) # weight -> robustMax as visits growThe mix weights were fit by a temporal-difference-style procedure across 1,500 self-play positions, tuning the operator so the estimate after 2ⁿ simulations matches the estimate after 2ⁿ⁺¹.
Results with effect sizes. Table 1 measures backup error against a "true" value from twice as many simulations. The mean operator is biased low, the max biased high, the mean more accurate at low simulation counts and the max more accurate at high counts, exactly as the bias argument predicts, and the mix beats both across the range. Crazy Stone won the 10th KGS computer-Go tournament over 8 opponents including GNU Go, Neuro Go, and Aya. In direct matches it beat Indigo 2005, a strong Monte-Carlo Go program, 61 percent to its opponents over 100 games, while still losing to the knowledge-rich GNU Go at equal time and closing the gap as time control grew, which shows the method scales with compute.
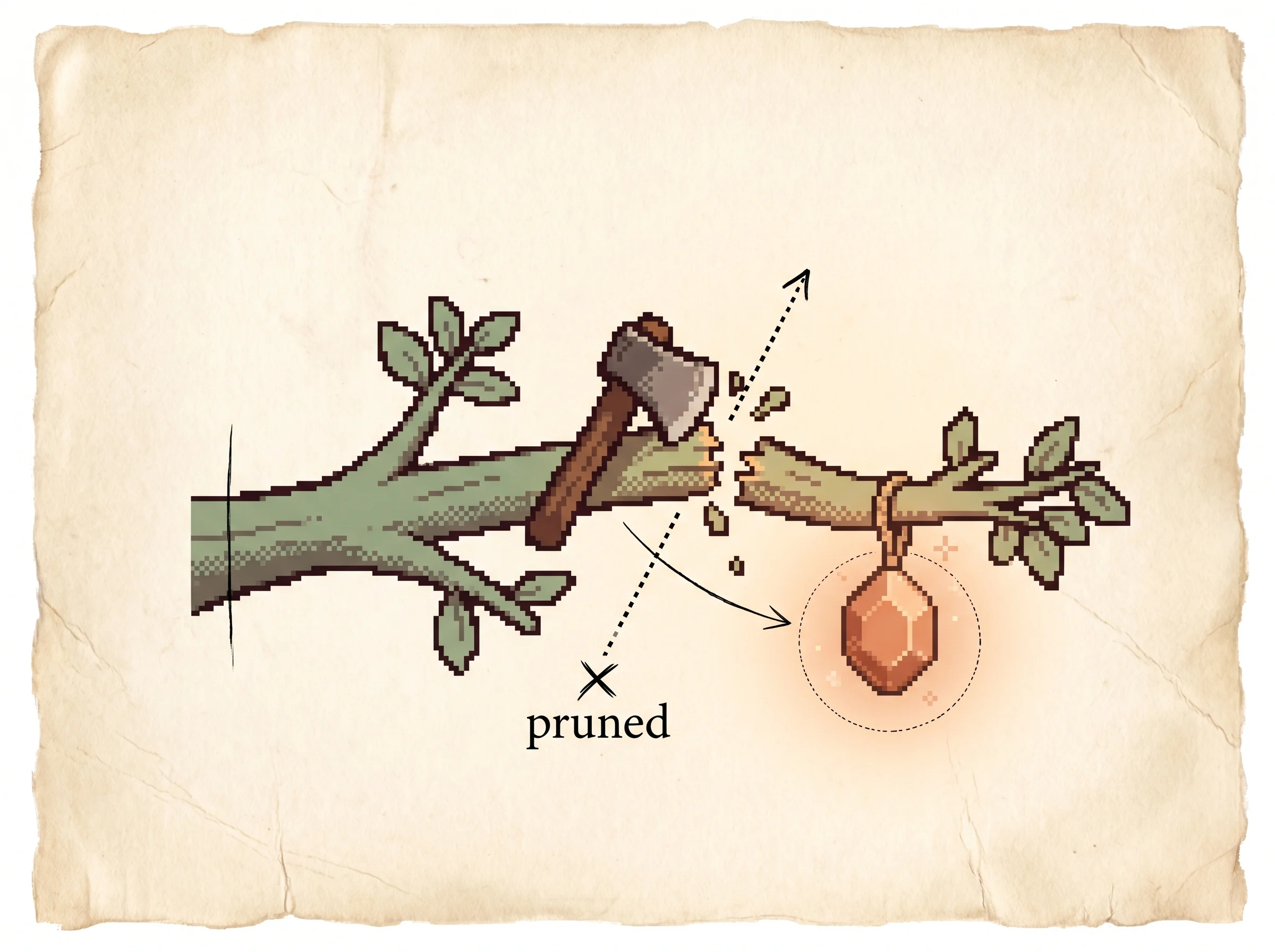
Switch the simulation's selectivity to Pruning to watch the danger directly. Progressive pruning cuts a move once its score falls far enough below the best, and on the hidden-gem tree it cuts the gem after a few unlucky playouts and never reconsiders it. Coulom's rule, with the ε floor, keeps a thin stream of playouts flowing to that move and recovers it.
Limitations and open questions. The constants and Crazy Stone's rollout heuristics were tuned empirically and are Go-specific. The uncertainty backup, σ²/min(500, S), is, in the author's own words, primitive and inaccurate. The central limit assumptions behind the urgency formula don't strictly hold inside the tree. And the global root-tree approach won't scale to 19 by 19; the authors suggest stochastic optimization at the root and generalizing the tree with high-level tactical objectives as next steps.
My assessment
The authors got the central call right, and the field's history confirms it. The four-step loop named here, descend by selectivity, expand, simulate, back up, is Monte-Carlo Tree Search, and it is the search that carried computer Go from hopeless to superhuman within a decade. The single most durable idea is the refusal to prune to zero. Keeping a floor under every move's probability is what makes the search convergent and what separates this from the progressive-pruning methods that came before, and you can watch that difference flip the answer in the simulation above.
The mean-to-max backup is the cleverest piece and also the most dated. The bias argument is exactly right, the mean underestimates and the max overestimates, and the empirical mix that slides between them is a sound engineering answer to a real problem. But it's a stack of hand-tuned formulas, and within a year Kocsis and Szepesvári's UCT replaced the urgency formula with a principled bandit bound that needed almost no tuning, which is the version that stuck. The variance backup the author flagged as primitive really was the weak brick, and the rollout heuristics in the appendix were the part that later work threw out entirely, first for learned rollouts and then for value networks.
What the paper undersold is the same thing the field undersold at the time: that a search which improves smoothly with compute and needs no static evaluator would, given enough compute and learned components, beat the static-evaluator approach at its own game. The author saw clearly that a global tree wouldn't reach 19 by 19, and was right, the answer turned out to be better rollouts and learned values bolted onto this exact loop, not a different search. The skeleton here held.