Language Models are Few-Shot Learners
A language model big enough learns a brand-new task from a handful of examples typed into its prompt, with no extra training, and the bigger it gets the better it learns this way.

Read at your level
Start where you're comfortable and climb as far as you like.
- For a 5-year-old
- For a high schooler
- For a college student
- For an industry pro
- For a PhD candidate
- For a peer researcher
Executive summary
Before this paper, teaching a language model a new task meant collecting thousands of labeled examples and retraining it, adjusting its internal numbers until it got the task right. That is slow and it needs a fresh dataset for every new task. This paper shows a different way. Train one model that is enormous, 175 billion numbers, on a huge pile of text, then just show it the task in the prompt. Write a short instruction and a few worked examples, then the question, and the model finishes it. No retraining, no weight changes, just text in and text out. The authors call this in-context learning, and the headline finding is that it gets dramatically better as the model grows. A small model barely improves when you add examples to its prompt. The big one shoots up, hitting 100% on 2-digit addition and writing news articles people can't tell from human ones. The cost is that the prompt has a fixed size, so you can only fit so many examples, and some tasks never click no matter how many you show.
Try it
Load the Few-shot, 175B preset and press play. Watch the running accuracy on 2-digit addition climb toward 100% as the test queries roll in. Now switch the model size to 125M and play again. The same prompt, the same examples, but the accuracy stays near the floor, because the slope of the curve comes from scale. Then load The reversed-word wall, pile on every example you can, and watch the prediction sit near zero anyway.
The full GPT-3 with a task description and a stack of worked examples. Press play and watch the running accuracy climb toward 100% on 2-digit addition.
Orange is the 175B (GPT-3) model you picked. The faint sage lines are the other sizes. The slope is what changes with scale.
GPT-3 175B scores 76.9% zero-shot and 100% few-shot on 2-digit addition (Table 3.9). Small models stay near zero no matter how many examples they see.
| query | model | answer |
|---|---|---|
| Press play to send test queries through the prompt. | ||
Add an example, scale the model, or mislabel a demo to start the log.
The success rates are fit to the paper's own numbers: GPT-3 175B goes from 76.9% to 100% on 2-digit addition (Table 3.9) and random insertion climbs 8% to 67% (Table 3.10), while reversed words stays near zero. Each test query is a seeded coin flip against the predicted rate, so the running accuracy lands on the curve over many trials, the way the paper reports accuracy over 2,000 instances. Each preset uses a fixed seed, so the same preset always produces the same trial sequence. The playback-pace slider controls how fast queries arrive during autoplay; it is not a concept in the paper.
For a 5-year-old
Imagine a kid who has read every book in the world. The kid is really, really smart, but you've never asked them to do your special game before.
So you show them. You say, "Here's how my game works. When I say two plus three, you say five. When I say four plus one, you say five too. When I say six plus two, you say eight." You did three turns yourself so they can watch.
Then you say, "Okay, now you. Seven plus one?" And the kid says "eight!" They never played before. They just watched you do it three times and copied the pattern.
That's the whole trick. You don't have to teach the kid for months. You show a few examples right before you ask, and the kid figures out the game from those examples.
Here's the funny part. A kid who only read a few books can't do this. You show them the examples and they still get it wrong. The trick only works if the kid has read enough to be really smart first. The model in this paper is the kid who read everything, so it learns your game from just a few examples.
Real models don't watch with eyes and they don't really copy. They turn your words into numbers and guess the next word. But the feeling is the same. Show a few, then ask, and the smart one gets it.
For a high schooler
You've used autocomplete. You start typing a text and your phone guesses the next word. A language model is autocomplete trained on almost the whole internet, so it's very good at guessing what comes next.
Here's the clever move. Suppose you want it to translate English to French. You don't retrain it. You just type a prompt like this, and let it autocomplete the last line.
Translate English to French:
sea otter => loutre de mer
cheese =>The model sees the pattern. It already knows French from all the text it read, and the one example tells it what you want right now. So it guesses "fromage" and it's right. The authors call this in-context learning, because the model learns the task from what's in its context, the prompt, instead of from training.
You can show it zero examples, one example, or a few. More examples usually help. Here's the surprise, with real numbers. On adding two 2-digit numbers, the biggest model in the paper gets it right 76.9% of the time with no examples, and 100% of the time once you show it a handful. But the small models stay terrible at it no matter how many examples you give. Showing examples only helps if the model is big enough.
So the size of the model decides whether it can learn from your examples at all.
For a college student
You should care about this because it's the paper that made prompting a thing. Before it, the standard recipe was pre-train then fine-tune. You take a model pre-trained on lots of text, then you keep training it on a few thousand labeled examples of your task, nudging its weights with gradient descent until it performs. It works, but every new task needs its own dataset and its own training run, and a model fine-tuned on a narrow dataset can latch onto quirks of that data instead of the real task.
The authors ask a sharper question. Can a model do a new task with no gradient updates at all, just from a prompt? They build GPT-3, a 175 billion parameter autoregressive Transformer, train it once on about 300 billion tokens of web text, books, and Wikipedia, and then freeze it. For every task they test, they only ever run a forward pass. The task lives entirely in the input text.
They define three settings, all the same idea with more examples stuffed in.
Zero-shot: description + question
One-shot: description + 1 example + question
Few-shot: description + K examples + question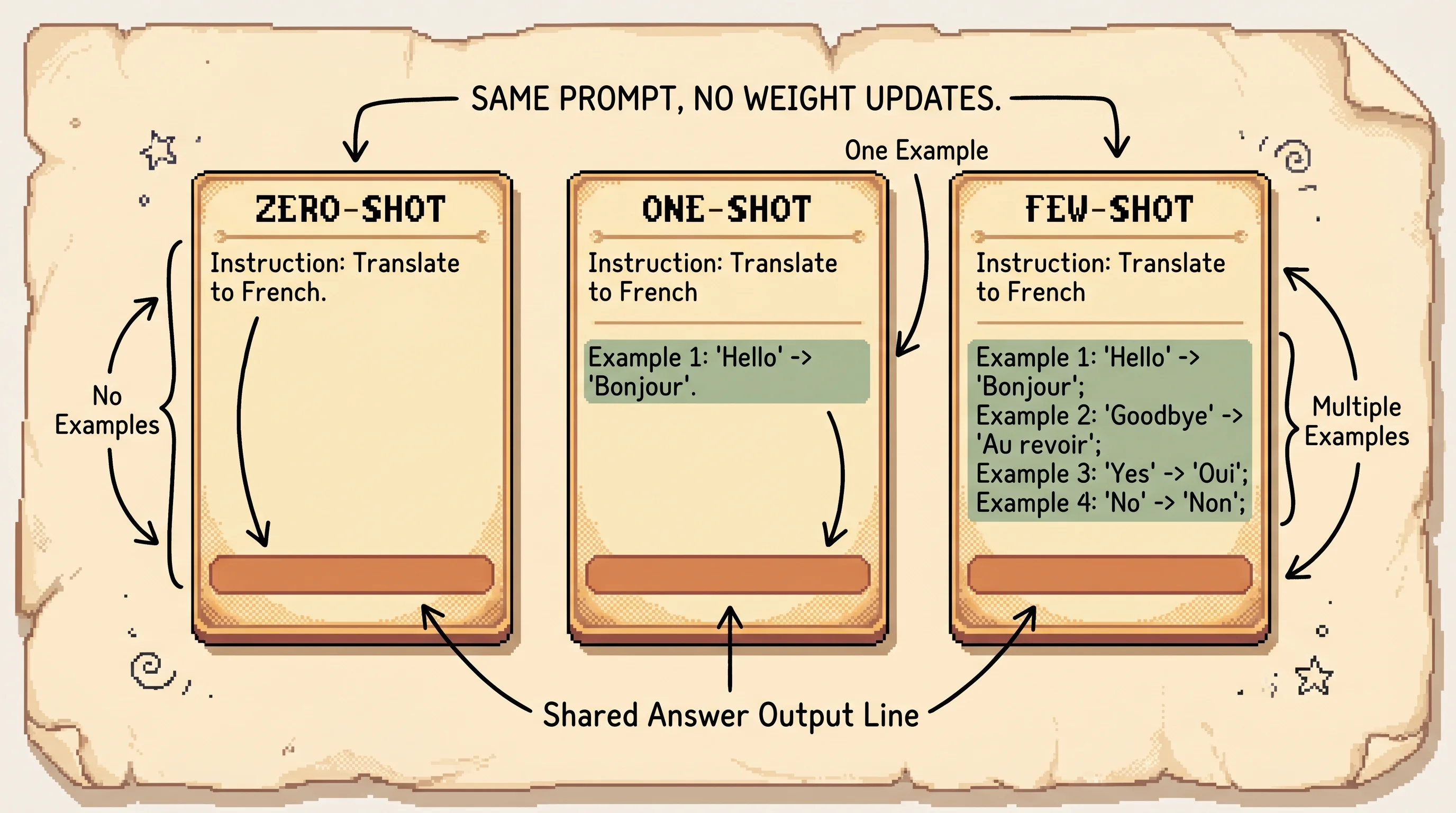
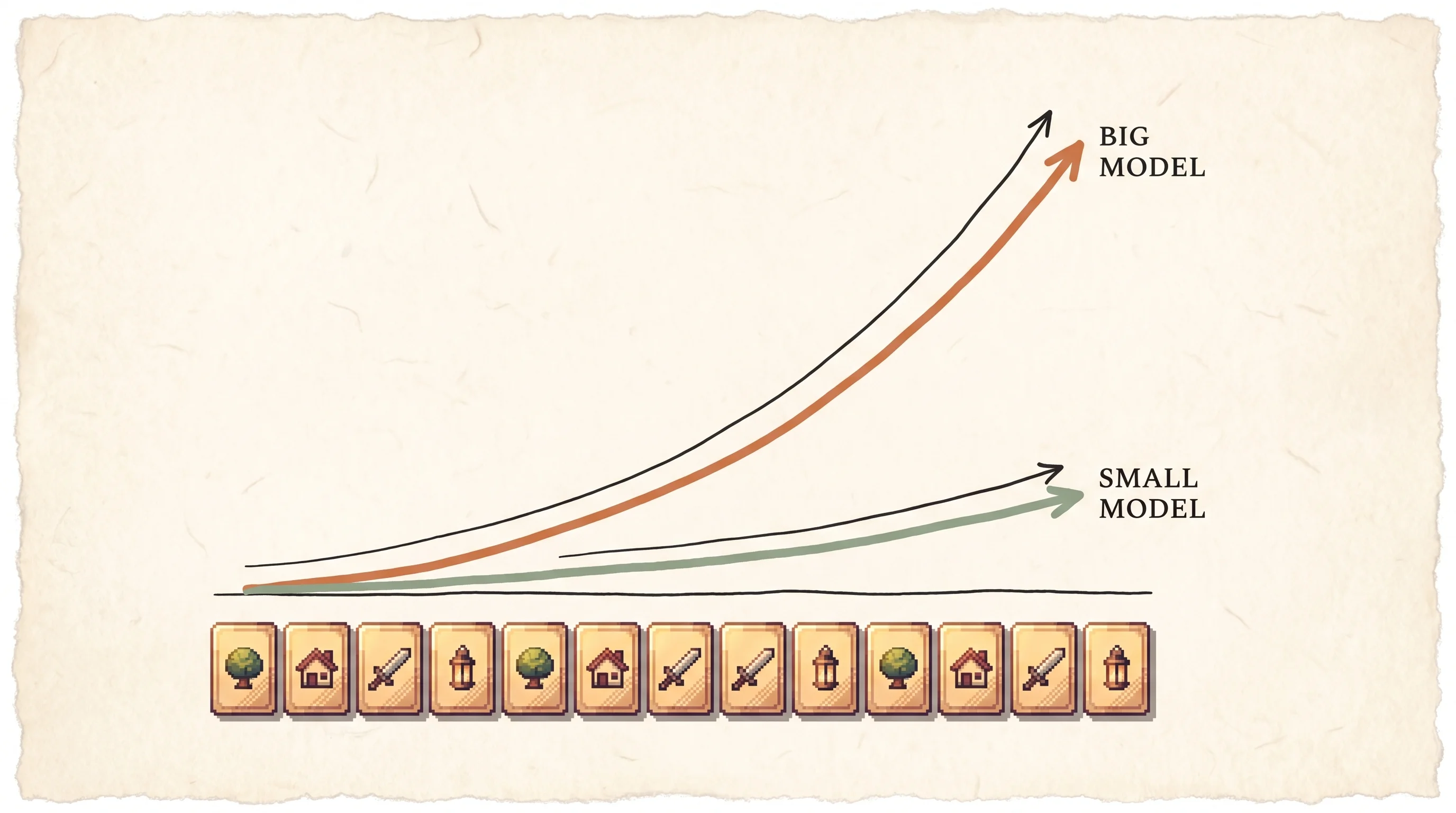
The key result is not just that few-shot works. It's how the benefit scales. Plot accuracy against the number of examples K in the prompt, and you get an in-context learning curve. For a big model that curve climbs steeply. For a small model it's almost flat. The ability to learn from the prompt is itself something that emerges with scale.
Work one example end to end. Take 2-digit addition. The full GPT-3 in the few-shot setting scores 100% on 2-digit addition, 98.9% on 2-digit subtraction, and 80.4% on 3-digit addition. The 13 billion model, the next size down, solves 2-digit addition only about half the time. The authors checked whether the model just memorized the answers from its training data, searched for the test problems in the training set, and found almost none, so the model is actually computing, not looking up.
The hard limit falls out of how prompts work. The model has a fixed context window of 2048 tokens. Every example you add eats into that budget, so you can only fit so many before the prompt overflows. Load the simulation, switch to the unscramble task, and add examples until the context meter turns orange. That's the ceiling the paper is working against.
For an industry pro
The problem this solves for you is the per-task data tax. The fine-tune recipe needs thousands of labeled examples for every new task, plus a training pipeline and a place to store each fine-tuned checkpoint. In-context learning collapses that to a forward pass. You write a prompt with a few examples and ship it. One frozen model serves every task, and adding a task means writing text, not collecting a dataset and running a job.
The cost has two parts. First, the model is huge. 175 billion parameters is expensive to host and slow to run, and you pay that at every inference. Second, the context window caps how much you can teach in the prompt, and tokens spent on examples are tokens you pay for and tokens you can't spend on the actual input. Doubling your examples roughly doubles the prompt cost.
The expected lift over a small model is not incremental, it's categorical. A small model basically can't do this. The few-shot accuracy curve is flat for small models and steep for the large one, so the capability shows up only past a size threshold. Budget for the big model or you don't get the trick at all.
The failure modes are real and worth planning around. Some tasks barely move even at full scale. Reading comprehension on hard datasets, natural language inference, and anything requiring comparing two pieces of text closely all lag. And some tasks never work no matter what, like reversing the letters in a word, where even the biggest model with a full prompt sits near zero. If your task looks like one of those, few-shot prompting won't save you, and you're back to fine-tuning or a different approach.
For a PhD candidate
The contribution is showing that in-context learning scales as a capability, not just that a large LM can be prompted. Prior work, the GPT-2 paper among others, showed task descriptions and demonstrations could steer a pre-trained model, but the results were far below fine-tuned baselines and there was no systematic scaling study. This paper trains eight models from 125M to 175B under identical conditions and measures zero-, one-, and few-shot performance across more than two dozen benchmarks, which lets it isolate the effect of scale on the slope of the in-context learning curve.
The methodological choices reward scrutiny. They deliberately do not fine-tune GPT-3, because the whole point is task-agnostic inference-time adaptation, and fine-tuning would confound the measurement they care about. The architecture is GPT-2's with alternating dense and locally banded sparse attention, so the result is about scale and data, not a new architecture. The training mix oversamples high-quality corpora, WebText and books and Wikipedia get seen 2 to 3 times while filtered Common Crawl is seen less than once, trading a little overfitting for quality. They also build a contamination analysis, searching test sets in the training data, because a model that memorized 300 billion tokens could fake competence. A bug left some overlap in, which they characterize rather than hide.
The threats to validity the authors name themselves are the honest ones. They cannot fully separate whether few-shot learning recognizes a task seen during pre-training or learns it de novo at inference time. They argue this varies by task, synthetic tasks like word unscrambling look learned in-context while translation must come from pre-training, but they're explicit that it's unresolved. The decoder-only autoregressive design likely hurts on tasks that benefit from bidirectionality, which they suggest explains the weak showing on WIC and some reading comprehension. And the headline tasks skew toward short sequences, with the quadratic attention cost and the fixed context window left as standing constraints. The obvious follow-ups, most of which the field then chased, are instruction tuning to fix the zero-shot gap, bidirectional or retrieval-augmented variants, and pushing the scaling further.
For a peer researcher
The delta against the fine-tune paradigm and against the GPT-2 demonstration is that adaptation moves entirely to inference and that the adaptation ability itself scales with parameters. Strip the gradient updates, freeze the model, and put the task in the context. The payoff is one model that handles arbitrary tasks from text alone, and the new measurable is the in-context learning curve's slope as a function of scale, which is flat for small models and steep for the 175B one.
The choices read as deliberate. No fine-tuning is a measurement decision, not a performance one, since they grant fine-tuning would likely beat their numbers on most benchmarks and call it future work. The decoder-only autoregressive objective trades the bidirectional advantage on cloze and comparison tasks for clean sampling and likelihood, and they own that this probably costs them WIC and ANLI. Oversampling clean corpora trades a touch of train-test overlap for data quality. Each is a defensible tradeoff rather than a claim of optimality.
What would change my mind on the central claim. If a model an order of magnitude smaller matched the few-shot curve under the same data, the "scale unlocks in-context learning" story would weaken, and that hasn't happened, the curves separate cleanly by size. The honest soft spots are the unresolved learned-versus-recognized question and the contamination bug, both of which they surface rather than bury. The reversed-words wall is the cleanest negative result in the paper and the most useful, because it marks where prompting genuinely cannot reach.
How it works
The problem and why prior approaches failed. Pre-train then fine-tune was the standard. Pre-train a model on lots of text, then keep training it on a task-specific labeled dataset until it performs. Two problems. It needs thousands to hundreds of thousands of labeled examples for every single task, which is expensive to collect and has to be redone for each new task. And fine-tuning on a narrow dataset lets the model exploit quirks of that dataset, so a model that scores at human level on a benchmark can be much worse on the real underlying task. Humans don't work this way. A person learns a new language task from a short instruction or a couple of examples.
The key idea. Make the model big enough and you don't need to fine-tune at all. Show it the task in the prompt, a description and a few worked examples, then the question, and let it complete the answer. No gradient updates, no weight changes, just a forward pass. The model learns the task from its context, so the authors call it in-context learning.
Methodology. Train GPT-3, an autoregressive Transformer with 175 billion parameters, on roughly 300 billion tokens drawn from filtered Common Crawl, an expanded WebText, two book corpora, and Wikipedia. Use the same architecture as GPT-2, with alternating dense and locally banded sparse attention. Train eight sizes, from 125M to 175B, so the effect of scale is measurable. Then evaluate frozen, in three settings.
Zero-shot: "Add the two numbers. 57 + 38 =>"
One-shot: "Add the two numbers. 48 + 76 => 124. 57 + 38 =>"
Few-shot: "Add the two numbers. 48 + 76 => 124. 12 + 9 => 21. ... 57 + 38 =>"Across all of this, the only knob is what sits in the prompt and how big the model is. To see why example count is bounded, the prompt lives inside a fixed context window of 2048 tokens, and each example spends some of that budget.

In the simulation, switch to the unscramble task and add examples while watching the context meter. Once it overflows, the earliest examples have to fall out of the prompt, which is the real wall the paper works against.
Results with effect sizes. On 2-digit addition the full GPT-3 goes from 76.9% zero-shot to 100% few-shot, on 2-digit subtraction from 58.0% to 98.9%, and on 3-digit addition from 34.2% to 80.4%. The 13 billion model solves 2-digit addition only about half the time, so the jump from 13B to 175B is sharp, not gradual. On word unscrambling, removing random inserted symbols climbs from 8.3% zero-shot to 67.2% few-shot. On TriviaQA few-shot GPT-3 hits 71.2%, beating the fine-tuned state of the art in the same closed-book setting. And human evaluators told apart GPT-3's news articles from real ones at barely above chance.
Limitations and open questions. Some tasks resist few-shot prompting even at full scale, including natural language inference and several reading comprehension datasets, likely because the decoder-only design can't read bidirectionally. Reversing the letters in a word stays near zero in every setting, a skill the model just can't pick up from a few examples. The fixed context window caps how much you can teach in the prompt. And the authors can't fully say whether the model learns each task fresh at inference time or recognizes something it saw during pre-training, which they leave open.
My assessment
The authors got the big call right, and the field reorganized around it. Prompting a frozen model is now the default way people use language models, and "few-shot" and "zero-shot" entered everyday vocabulary because of this paper. The deepest idea here is the one they measured rather than assumed, that the ability to learn from the prompt is itself a function of scale. That reframed model size from a quality knob into a capability switch, and it set up the scaling-law thinking that drove the next several years.
Where the paper is honestly incomplete is the learned-versus-recognized question, which it raises and cannot answer, and which still isn't fully settled. The contamination bug is a real blemish, though characterizing it openly was the right move given retraining a 175B model wasn't feasible. The zero-shot results were weaker than they needed to be, and the fix, instruction tuning, came right after from the same lab and from others, which tells you the gap was a missing ingredient rather than a ceiling. The reversed-words wall has aged well as a lesson, a clean marker that prompting has limits no amount of scale erases on its own. None of that dents the core. Make the model big enough, and it learns from a few examples in its prompt.