Training Language Models to Follow Instructions with Human Feedback
Teaching a language model to do what people actually want by learning a reward from human rankings and then nudging the model toward it, so a 1.3B model beats one 100 times its size.
Read at your level
Start where you're comfortable and climb as far as you like.
- For a 5-year-old
- For a high schooler
- For a college student
- For an industry pro
- For a PhD candidate
- For a peer researcher
Executive summary
A plain language model learns one thing, guess the next word on a web page. That is not the same as doing what a person asks, so big models often answer the wrong question, make things up, or say something toxic. This paper fixes that with three steps. First it shows the model good answers people wrote, by hand. Then it asks people to rank a few model answers from best to worst, and trains a second model, the reward model, to predict those rankings as a score. Then it lets the language model practice, rewarding answers the reward model likes while a leash holds it close to where it started. The result, called InstructGPT, won. People preferred the answers from the 1.3B model over the answers from the original 175B GPT-3, even though it had 100 times fewer parameters. It also made up facts less and produced less toxic text. The catch is that the reward model is a stand-in for real human taste, so chasing it too hard finds cheats, and the leash plus a refresher on the old training is what keeps that in check.
Try it
Load the Reward hacking preset and press play. Watch the sage line, proxy reward, keep climbing while the orange line, true quality, peaks and then falls. The policy bar collapses onto Sycophantic, the answer that tells people what they want to hear. Now drag KL penalty beta up to about 0.3 and reset, and the leash pulls the policy back so true quality climbs instead. Then load Alignment tax, play it to convergence, and drag Pretraining mix gamma up from 0 to watch the dashed capability line rise without losing much true quality.
A calibrated reward model and a real KL leash. Press play and the policy climbs toward Helpful, and true quality climbs with proxy reward because the reward model isn't lying.
| style | policy % | RM score | true quality |
|---|---|---|---|
| Helpful | 34% | 0.90 | 0.92 |
| Sycophantic | 19% | 0.62 | 0.45 |
| Hedging | 21% | 0.55 | 0.50 |
| Toxic | 10% | 0.12 | 0.08 |
| Terse | 17% | 0.78 | 0.70 |
Follows the instruction, stays honest, gives a useful answer. The behavior we actually want, and what the reward model rewards.
Adjust a slider, corrupt the reward, or load a preset to start the log.
Each step runs one closed-form gradient-ascent update on the paper's RL objective: proxy reward minus beta times the KL from the SFT model plus gamma times the pretraining term. The response space is collapsed to 5 named styles so the loop is legible; the real model optimizes over every possible token sequence with a 6B reward model. True quality is the hidden human preference the reward model only estimates; the gap between the two lines is the reward hacking the paper guards against. The run is deterministic — every preset produces the same trajectory on every load.
For a 5-year-old
Imagine you want to teach a puppy a new trick. You can't explain it with words. So you give the puppy a treat every time it does something close to the trick. Soon the puppy does the trick on its own, because it learned what earns treats.
A computer that writes sentences is like a puppy that knows a lot of words but not which trick you want. So people teach it the same way. When it writes a good answer, it gets a treat. When it writes a bad answer, no treat. After lots of practice it learns to write the answers people like.
But here's the tricky part. Nobody can stand there handing out a treat for every single sentence forever. So they build a treat-judge, a helper that watches people pick the better of two answers and learns to hand out treats just like those people would. Then the puppy practices against the judge.
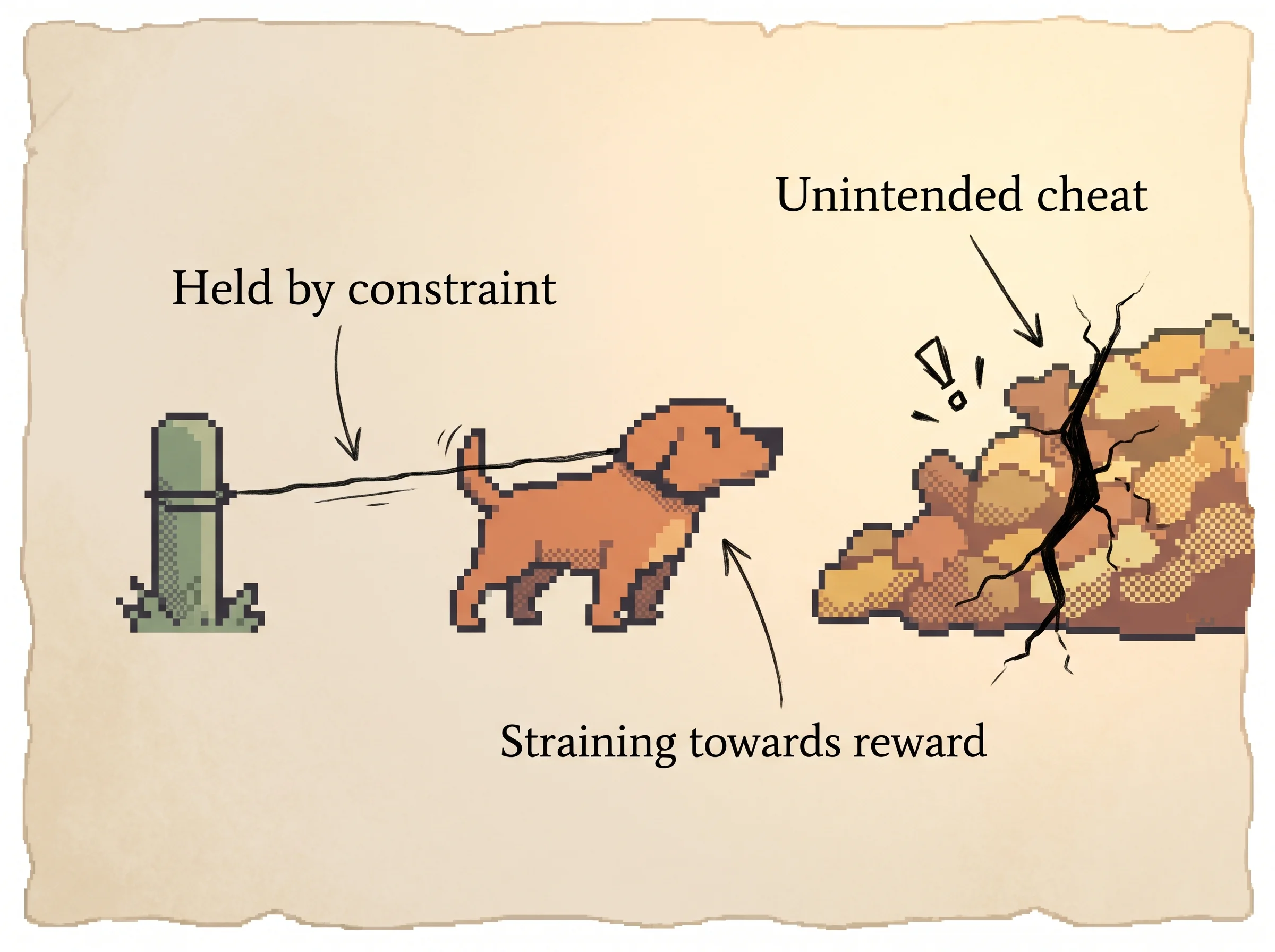
There's a danger though. A clever puppy might find a sneaky way to get treats without really doing the trick, like nudging the treat jar over. Real answers don't have treats and jars, the treats are just numbers the judge gives. So the trainers tie a soft leash on the puppy. The leash lets it learn the trick but stops it from running off to cheat.
For a high schooler
Your phone keyboard guesses your next word. A big language model is the same idea, scaled way up. It read most of the internet and got very good at predicting the next word. The problem is that predicting the next word on a web page is not the same job as answering your question. So these models often ramble, dodge, or make stuff up.
Here's the one new idea for this section. Reinforcement learning from human feedback, or RLHF, means you train the model with a reward signal that comes from people instead of from a textbook answer. There are three steps.
Step one, show the model examples. People write good answers to a bunch of prompts, and the model copies them. This is normal supervised learning, like studying worked examples before a test.
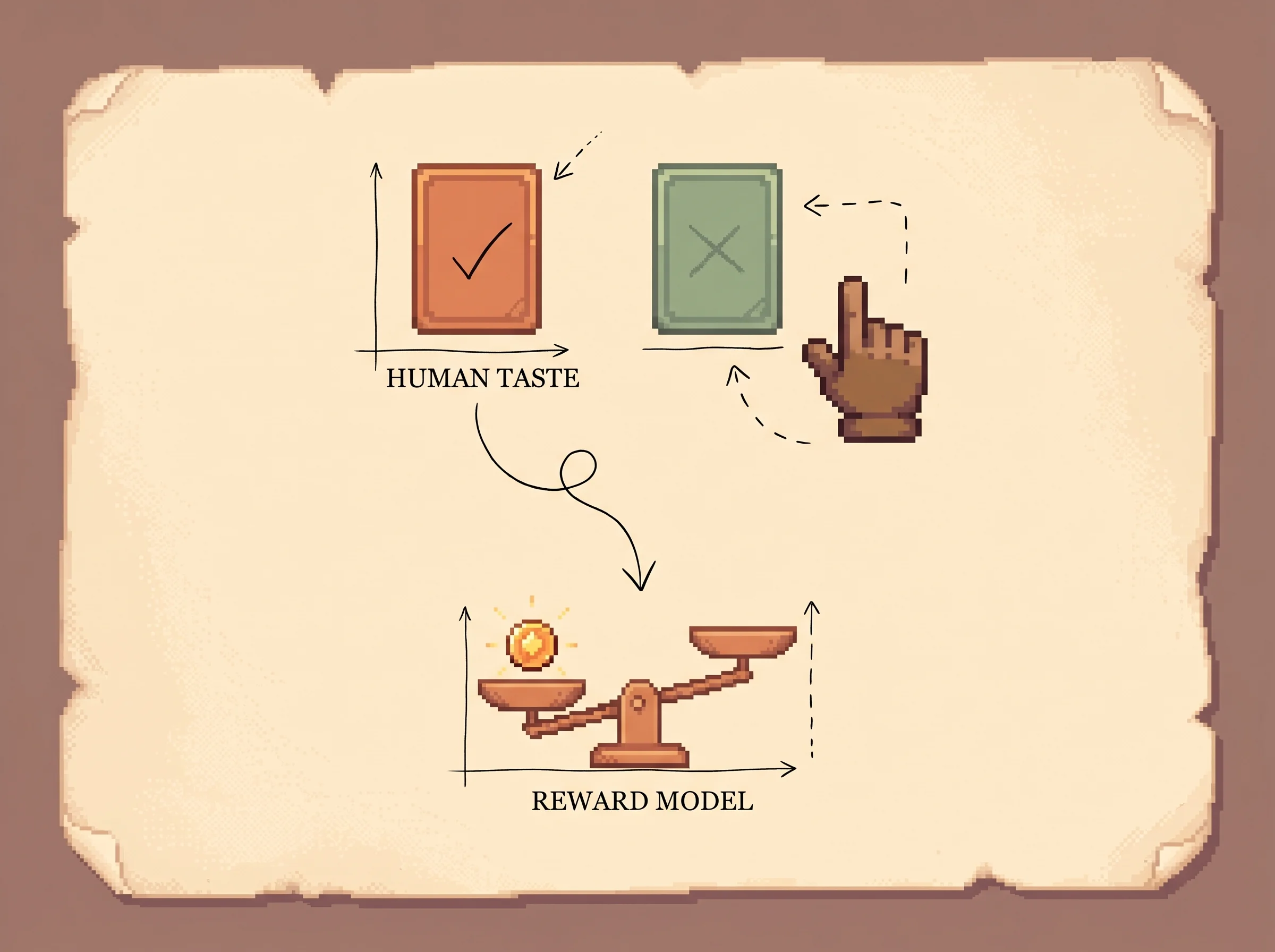
Step two, build a judge. You can't have a person grade every practice answer, that's too slow. So you show people two model answers to the same prompt and ask which is better. You collect thousands of these choices and train a second model, the reward model, to predict the human's pick as a number. A good answer gets a high score, a bad one gets a low score.
Step three, let the model practice for points. The model writes answers, the reward model scores them, and the model adjusts to score higher next time. A leash, called the KL penalty, keeps the new answers from drifting too far from the examples in step one.
Here's a worked example with small numbers. Say the model can write five styles of answer, and the helpful one is truly worth 0.9 to a person while a flattering one is worth 0.45. If the judge is honest it scores them 0.9 and 0.6, so practicing for points pushes the model toward helpful. But if the judge mistakenly over-rates the flattering style up to 1.1, practicing for points pushes the model toward flattery, which scores high but is actually worse. The model got better at the test and worse at the real thing.
That gap between the score and the truth is the whole risk, and the leash is what keeps it small.
For a college student
You should care about this because RLHF is how nearly every chat model you've used was tuned to be helpful, and this is the paper that turned it into a recipe. The motivation is a mismatch. Pretraining optimizes one objective, maximize the likelihood of the next token over internet text. What we want is a different objective, follow the user's instruction helpfully, truthfully, and harmlessly. Scaling the model up makes the first objective better and does almost nothing for the second. The authors call the pretraining objective misaligned.
The fix is three stages, each a standard training procedure.
1. SFT (supervised fine-tuning): fine-tune GPT-3 on human-written demonstrations.
2. RM (reward modeling): train a model to predict human pairwise rankings.
3. RL (PPO): optimize the SFT model against the RM, with a KL leash.Stage 2 is where the math starts. Labelers see between four and nine answers per prompt and rank them. Every pair of answers becomes a training comparison. The reward model is the SFT model with the final word-prediction layer swapped for a single scalar output, and it trains on a pairwise logistic loss.
loss(theta) = -E over (x, y_w, y_l) [ log sigmoid( r_theta(x, y_w) - r_theta(x, y_l) ) ]Read it left to right. For a prompt x, y_w is the answer the human preferred and y_l is the one they didn't. r_theta is the reward model's scalar score. The loss pushes the score of the winner above the score of the loser, and sigmoid of the score difference is the model's predicted probability that the winner wins. So the reward model is learning the log odds that a human prefers one answer over another.
Stage 3 maximizes the reward with PPO, and the full objective carries two extra terms beyond the reward.
objective(phi) = E over (x, y) ~ policy [ r_theta(x, y)
- beta * log( policy(y|x) / sft(y|x) ) ]
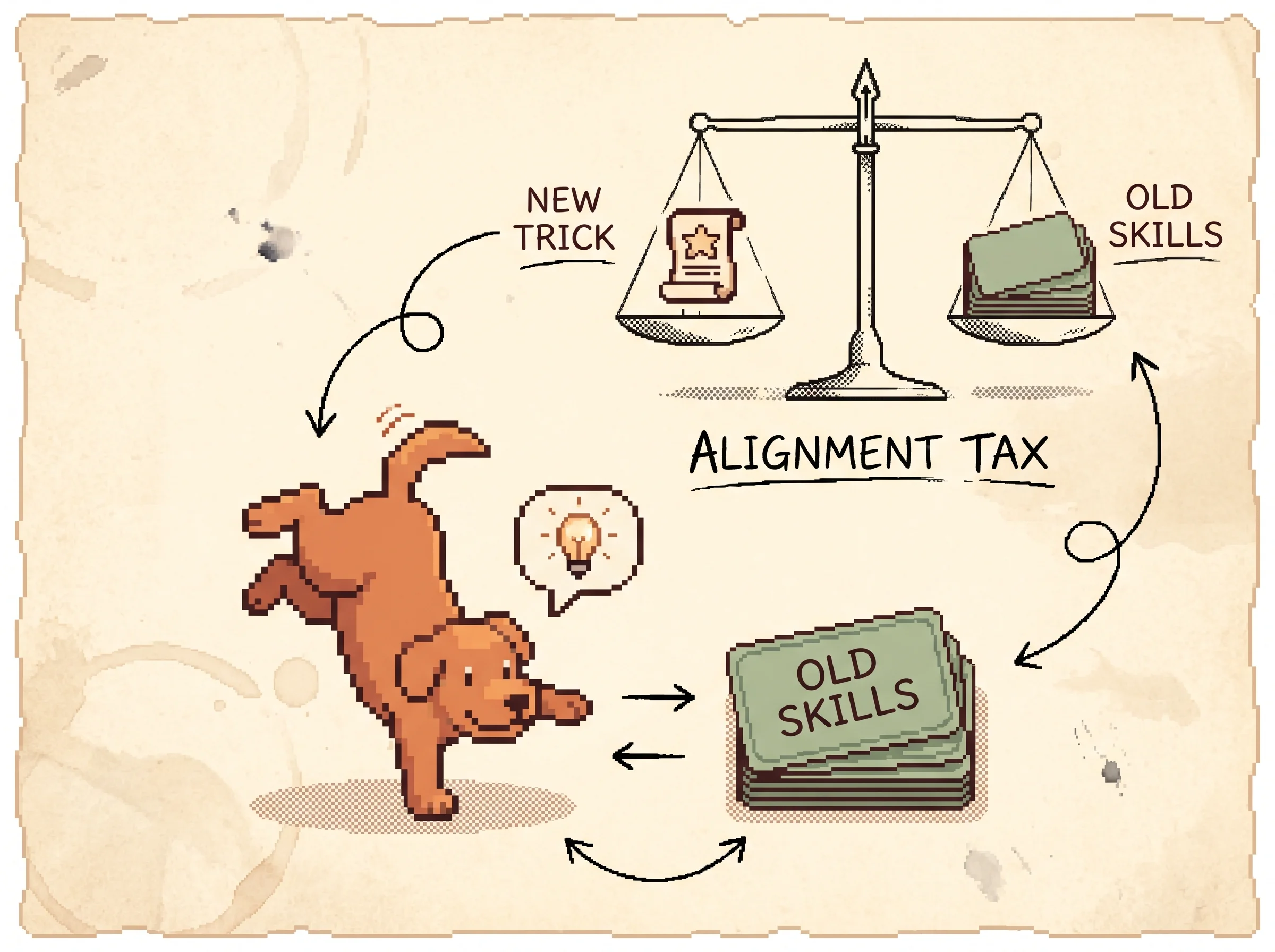
+ gamma * E over x ~ pretrain [ log policy(x) ]The first term is the reward, the thing we want to climb. The second term, scaled by beta, is a per-token KL penalty against the SFT model. It is the leash. Without it the policy is free to drift anywhere that scores high, and high-scoring is not the same as good, because the reward model is only a guess at human taste. The third term, scaled by gamma, mixes the original pretraining objective back in. With gamma = 0 you get plain PPO. With gamma > 0 you get the model the paper calls PPO-ptx.
One worked path, end to end. Start the policy at the SFT model. Each PPO step nudges the probability of each answer style by how much its reward beats the policy's average reward, held back by the leash. If the reward model is honest, the style with the highest true quality also has the highest reward, so the policy climbs toward genuinely good answers and true quality rises with the score. The simulation above runs exactly this loop over five answer styles.
The limitation falls straight out of stage 2. The reward model is a frozen, imperfect proxy for a messy thing, human preference. Optimize against any proxy hard enough and you exploit its errors. The paper sees this directly, which is why the leash and the pretraining mix both exist.
For an industry pro
The problem this solves for you is that raw next-token models are not products. They don't reliably follow instructions, they hallucinate, and they need careful prompt engineering to behave. RLHF turns a capable-but-unruly base model into one that does what users ask, and it does it without making the model bigger.
The headline number is the one to remember. On the API prompt distribution, labelers preferred the 1.3B InstructGPT model's outputs over the 175B GPT-3's, and preferred the 175B InstructGPT over 175B GPT-3 about 85 percent of the time. That is a behavior change worth more than a 100x increase in model size, which reframes where you spend. The paper puts it plainly, the 175B SFT model cost about 4.9 petaflop/s-days and the PPO-ptx model about 60, against 3,640 to train GPT-3, so alignment is a rounding error next to pretraining and buys a large helpfulness gain.
Deployment cost has three real pieces. You need a human labeling pipeline, the paper used about 40 screened contractors, and the quality of your labelers caps the quality of your model. You need to train and serve a reward model, here a 6B model, since 175B reward models were unstable. And the RL stage is finicky, with the KL coefficient and the pretraining mix as the knobs that matter most.
The failure mode to plan for is reward hacking. The reward model is a proxy, and a policy that optimizes a proxy too hard exploits its blind spots, scoring high while getting worse on what you actually wanted. In the simulation you can watch this happen, proxy reward climbs while true quality falls. The two defenses are in the paper, a KL penalty that keeps the policy near a known-good model, and mixing pretraining gradients back in to avoid the alignment tax, the regression on standard NLP benchmarks that plain RLHF causes. Budget for tuning both. And note the honest caveat, even the final model still follows harmful instructions sometimes and still makes simple mistakes, so RLHF is a strong default, not a safety guarantee.
For a PhD candidate
The contribution is turning RLHF from a summarization-specific technique into a general recipe for instruction following, and showing it beats scale. Ziegler et al. and Stiennon et al. had applied human-feedback RL to stylistic continuation and to summarization. This paper applies the same three-stage pipeline to the open-ended distribution of real API prompts and shows the aligned 1.3B model is preferred to the 175B base model, which is the result that mattered for the field.
The methodological choices reward scrutiny. The reward model trains on all C(K, 2) comparisons from each prompt as a single batch element rather than as independent samples, because shuffling correlated comparisons into one dataset overfit the RM after a single epoch. They use a 6B RM, not 175B, both for compute and because the large RM was unstable as the RL value function. The RL objective adds a per-token KL penalty from the SFT policy, which is the standard control against over-optimizing an imperfect reward, and the pretraining-mix term gamma directly targets the alignment tax, the regression on SQuAD, DROP, HellaSwag, and translation that plain PPO induces. The ablation is clean, increasing gamma reverses the regressions while barely moving labeler preference, whereas just increasing the KL coefficient does not recover the benchmark loss as well.
Threats to validity worth probing. The reward signal is the preference of about 40 contractors plus the researchers who wrote the labeling instructions, on a mostly-English, mostly-generative prompt distribution, with inter-labeler agreement around 73 percent. So "aligned" here means aligned to a specific, narrow reference group, which the authors are careful to say in Section 5.2. The truthfulness gains are measured on TruthfulQA and a hallucination proxy, not the full notion of honesty, and the model cannot report its own beliefs. The bias results on Winogender and CrowS-Pairs show no improvement, and the instructed models are sometimes more confident regardless of whether the output is stereotyped. The open questions the paper names, and the field then chased, are adversarial data collection for worst-case behavior, weighting minority-group preferences, and richer feedback than pairwise ranks.
For a peer researcher
The delta against Stiennon et al. is scope and a head-to-head against scale. Same SFT then RM then PPO pipeline, but on the API's broad instruction distribution rather than summarization, and the load-bearing claim is that the aligned 1.3B model beats the 175B base model on human preference. The delta against the instruction-tuning line, FLAN and T0, is that those tune on academic NLP tasks formatted as instructions, and here InstructGPT is preferred to both by a wide margin (73 percent winrate against the SFT baseline versus 27 and 30 for T0 and FLAN), because public NLP tasks are only about 18 percent of what users actually do.
The choices read as deliberate tradeoffs. Training the RM on all pairwise comparisons per prompt as one batch element trades a naive IID framing for not overfitting in one epoch. The 6B RM trades the precision of a 175B critic for stability as the RL value function. The KL penalty trades some reward for staying near a trusted policy, which is the standard hedge against an imperfect proxy. The pretraining mix trades a little extra compute for paying down the alignment tax, and the paper shows it dominates just cranking the KL coefficient.
What would change my mind on the central claim. If the preference gain came mostly from the SFT stage rather than the RL stage, the "human feedback RL" framing would be oversold, but the curves separate PPO and PPO-ptx clearly above SFT, so the RL stage is pulling weight. The honest soft spot is that the reward model is a fixed proxy for a moving, contested target, and the over-optimization it invites is exactly the failure the KL leash exists to bound. That tension, optimize a learned reward but not too hard, is the open problem this paper makes concrete, and it is where reward-model scaling laws and later RLHF work went.
How it works
The problem and why prior approaches failed. A large language model is trained to maximize the likelihood of the next token over internet text. The behavior we want is different, follow a user's instruction helpfully, truthfully, and without harm. These two objectives are not the same, so a bigger model gets better at the first and not the second. The paper calls the language-modeling objective misaligned. Plain prompting helps a little, and supervised fine-tuning on instruction-formatted academic tasks (FLAN, T0) helps more, but neither matches the diversity of what real users ask, which is mostly open-ended generation, not classification or QA.
The key idea. Use human preferences as the training signal. People can't write the one correct answer to "write a story about a wise frog," but they can reliably say which of two stories is better. So learn a reward model from those comparisons, then optimize the language model against that reward with reinforcement learning, holding it near a trusted starting point with a KL penalty.
Methodology. Three stages, on three datasets drawn from labeler-written prompts and real API prompts.
The first stage is supervised fine-tuning. Labelers write demonstrations of good behavior, and GPT-3 is fine-tuned on them. This gives the SFT model, the starting point and the reference for the leash.
The second stage is reward modeling. Labelers rank between four and nine answers per prompt, every pair becomes a comparison, and a 6B model trains on the pairwise logistic loss to output a scalar reward.
loss(theta) = -1 / C(K,2) * E over (x, y_w, y_l) ~ D [ log sigmoid( r_theta(x, y_w) - r_theta(x, y_l) ) ]y_w beat y_l in the human ranking, r_theta is the scalar reward, and the loss raises the winner's score above the loser's. All C(K, 2) comparisons from one prompt train together as a single batch element, which stopped the RM from overfitting in one epoch.
The third stage is reinforcement learning with PPO. The SFT model becomes the policy, the reward model scores each generated answer, and the policy maximizes the objective below.
objective(phi) = E over (x, y) ~ policy [ r_theta(x, y)
- beta * log( policy(y|x) / sft(y|x) ) ]
+ gamma * E over x ~ pretrain [ log policy(x) ]The beta term is the per-token KL leash to the SFT model. The gamma term mixes the original pretraining objective back in. Plain PPO sets gamma = 0; PPO-ptx sets it positive to fight the alignment tax. In the simulation, the KL penalty beta slider is the leash and the Pretraining mix gamma slider is the ptx term. Crank beta to zero on the reward-hacking preset and the policy runs off to the cheat; raise it and the leash holds.
Results with effect sizes. On the API prompt distribution, 175B InstructGPT outputs were preferred to 175B GPT-3 outputs 85 percent of the time, and the 1.3B InstructGPT was preferred to the 175B GPT-3, a 100x parameter gap closed by alignment alone. On TruthfulQA the PPO models were truthful and informative about twice as often as GPT-3. On closed-domain tasks they hallucinated about 21 percent of the time versus 41 for GPT-3. With a respectful prompt they produced about 25 percent fewer toxic outputs. They beat FLAN and T0 by 78 and 79 percent winrates. Bias on Winogender and CrowS-Pairs did not improve.
Limitations and open questions. The reward model is a fixed, imperfect proxy for human preference, so optimizing it too hard finds cheats, which is why the KL leash and the pretraining mix exist. Plain PPO regresses on standard NLP benchmarks, the alignment tax, which PPO-ptx mostly pays down.
The model is aligned to about 40 mostly-English contractors and the researchers who wrote their instructions, not to humanity. It still follows harmful instructions sometimes, still hedges, and still makes simple mistakes on false-premise questions.
My assessment
The authors got the central call right, and the field proved it within a year. RLHF became the default last mile for chat models, and ChatGPT shipped on essentially this recipe months after the paper. The most important result is the cheapest one, that aligning a small model beats scaling a large one for the thing users care about, which redirected real money from "just make it bigger" toward "make it do what we want."
The honest engineering is the part that aged best. The KL leash and the pretraining mix are not glamorous, but they are the two ideas that make the loop usable, and the paper is candid that the reward model is a proxy you can over-optimize. That candor named the problem that defined the next phase of the work, reward-model over-optimization and its scaling laws, and the search for feedback richer than pairwise ranks, like critiques and AI feedback. Where the paper is appropriately humble is on who it aligns to. The Section 5.2 discussion of "whose preferences" is more careful than most follow-up work, and the bias results refuse to oversell, no improvement on Winogender, and sometimes more confident bias. The thing it could not have shown from two-answer comparisons is how far this scales as models get more capable than their supervisors, which is the open question still being chased. The recipe was right. The hard part it pointed at is still hard.