Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Instead of writing one answer left to right, a language model lays out partial answers as a branching tree, scores each branch itself, and searches the tree, keeping the promising paths and backtracking out of dead ends.
Read at your level
Start where you're comfortable and climb as far as you like.
- For a 5-year-old
- For a high schooler
- For a college student
- For an industry pro
- For a PhD candidate
- For a peer researcher
Executive summary
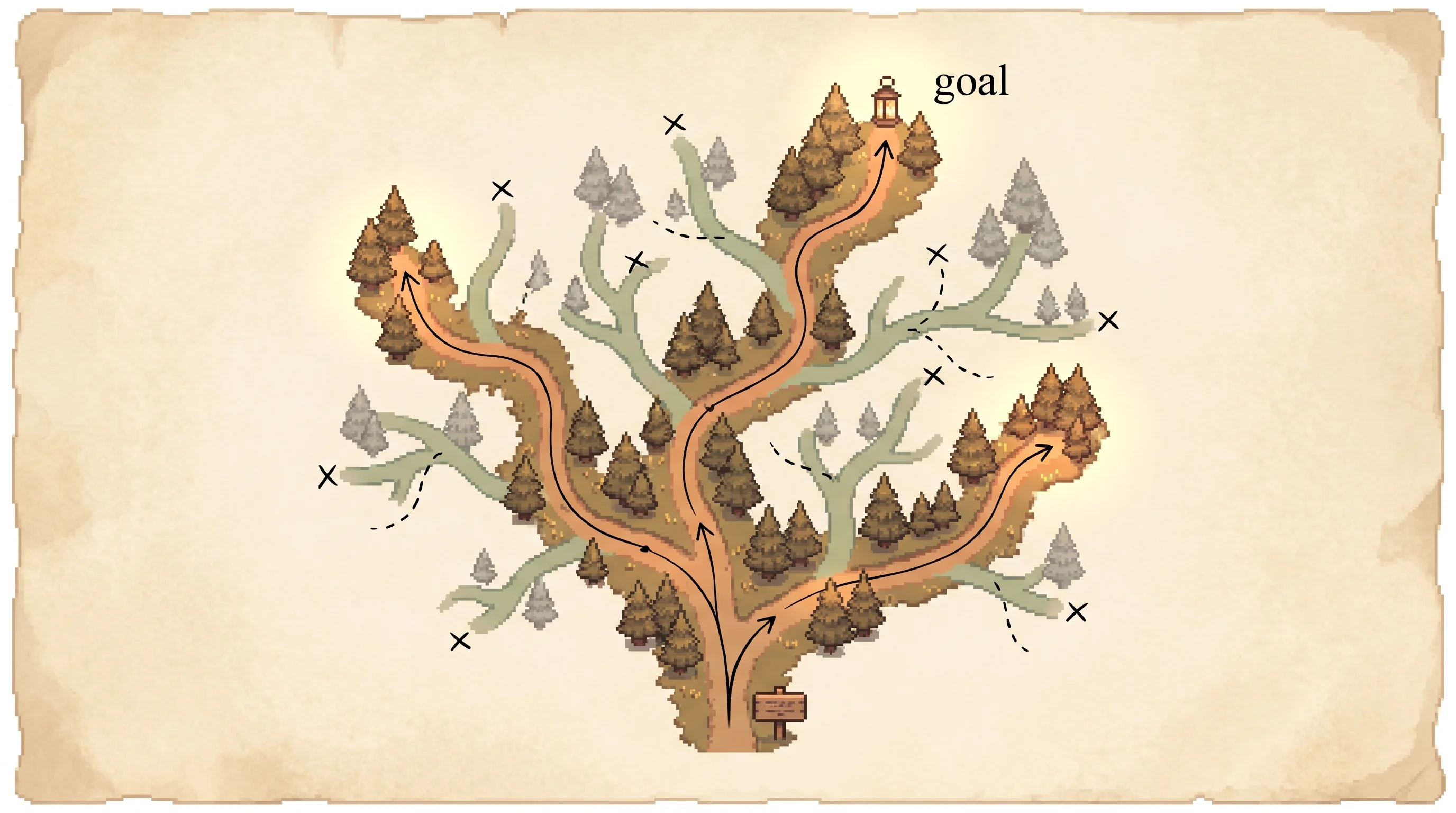
A language model normally writes an answer one word at a time, left to right, never looking back. That works for easy questions and breaks on anything that needs a plan, because one bad early word drags the whole answer down with it. Tree of Thoughts changes the shape of the work. The model writes a partial answer, a thought, then branches into several next thoughts, and keeps branching, so the partial answers form a tree. The model also grades each branch sure, maybe, or impossible. A search algorithm then walks the tree, keeps the most promising branches, throws out the dead ones, and backs up when a path leads nowhere. On Game of 24, a puzzle where you combine four numbers to make 24, plain chain-of-thought prompting with GPT-4 solved 4 percent of games. Tree of Thoughts solved 74 percent. The cost is that you call the model many more times, once to propose branches and again to grade them, at every node in the tree.
Try it
Load the BFS, wide beam (b=5) preset and press play. Watch the tree of partial answers grow, branches turn clay-orange when the search keeps them, gray when it prunes them, and one branch reach a green 24. Now load BFS, narrow beam (b=1) and play it, and the search fails on the same puzzle. Widen the beam slider back to 5 and reset, and the answer comes back. Then load Evaluator lies, step until a branch gets a red misjudged flag, click that branch to confirm 24 was truly still reachable from it, and flip the Honest evaluator toggle on and reset to watch the same search succeed.
The paper's 74% setting. A wide beam keeps the winning branch alive at every depth, so the search reaches 24.
The paper's worked example. (10 - 4) * (13 - 9) = 24.
Click any state in the tree to read its numbers, the equation that made it, the evaluator's verdict, and whether 24 is truly still reachable. Then flip its verdict or prune it and rerun.
Step the search or poke a state to start the log.
The thought generator and the state evaluator stand in for the two jobs the paper gives the language model. Game of 24 is small enough that the 24 reachable light is exact arithmetic, never a guess, so an honest evaluator always finds a route when one exists. The evaluator noise knob (active only when the honest toggle is off) is what turns the evaluator into a fallible model that prunes good branches, the failure the paper sees on crosswords. The run is deterministic: same preset, same search every time. This runs one puzzle with a handful of branches; the paper runs GPT-4 over 100 games.
For a 5-year-old
Imagine you're in a maze and you want to find the treasure. One way is to just keep walking straight and hope. If you walk into a wall, too bad, you lose.
A smarter way is to stop at every place the path splits. You look down each new path a little bit. You think "this one looks good, this one looks like a dead end." You walk down the good ones. If you hit a wall, you don't cry. You walk back to the last split and try a different path.
That's the whole idea. The maze is the problem. The splits are the choices. Looking down each path and guessing if it's good is the thinking. And walking back when you hit a wall is the part that makes it smart.
A computer that writes can do this too. It used to just walk straight and hope. Now it stops at every split, guesses which paths are good, and walks back when it gets stuck. It finds the treasure way more often.
For a high schooler
You've used a maze-solving trick without naming it. When you do a maze on paper, you don't commit to one route. You try a branch with your pencil, see it dead-ends, and back up to the last fork. Tree of Thoughts gives a language model that same trick.
Here's the one new term. A thought is a small chunk of partial answer, big enough to mean something but small enough to judge. For the puzzle Game of 24, where you use four numbers and plus, minus, times, divide to make 24, a thought is one step like "4 + 9 = 13." After that step you have three numbers left instead of four. Do it again and you have two. Once more and you have one, and you hope it's 24.
Each thought opens new thoughts, so the partial answers branch into a tree. The model does two jobs at every branch. First it proposes the next thoughts. Then it grades each one, saying "this looks sure," "maybe," or "no way." A search then keeps the best branches and drops the rest.
Here's a worked example. Start with 4, 9, 10, 13. One branch is "10 - 4 = 6," leaving 6, 9, 13. From there "13 - 9 = 4" leaves 6 and 4, and "6 * 4 = 24" wins. A different branch, "4 + 9 = 13," leaves 10, 13, 13, and no matter what you do next you can't reach 24, so the model grades that branch low and the search abandons it.
The big result lands hard. Asked to just write the answer straight out, GPT-4 solved 4 of every 100 of these puzzles. With the tree and the search, it solved 74. Stopping at every fork to look and to back up beats walking straight and hoping.
For a college student
You should care about this because it reframes inference as search. A language model's default decoding is a left-to-right, token-level walk with no backtracking, which is a single greedy path through an enormous space. For problems where early commitments matter, that's the worst possible search strategy. Tree of Thoughts wraps the model in the planning machinery the model lacks on its own.
Frame any problem as a tree. A node is a state s = [x, z_1...i], the input x plus the thoughts chosen so far. To instantiate Tree of Thoughts you answer four questions. How do you decompose the problem into thought steps? How do you generate candidate next thoughts from a state? How do you evaluate a state? And what search algorithm walks the tree?
For Game of 24 the answers are concrete. A thought is one intermediate equation that consumes two numbers and produces one. The generator proposes k candidate next equations. The evaluator scores each resulting state.
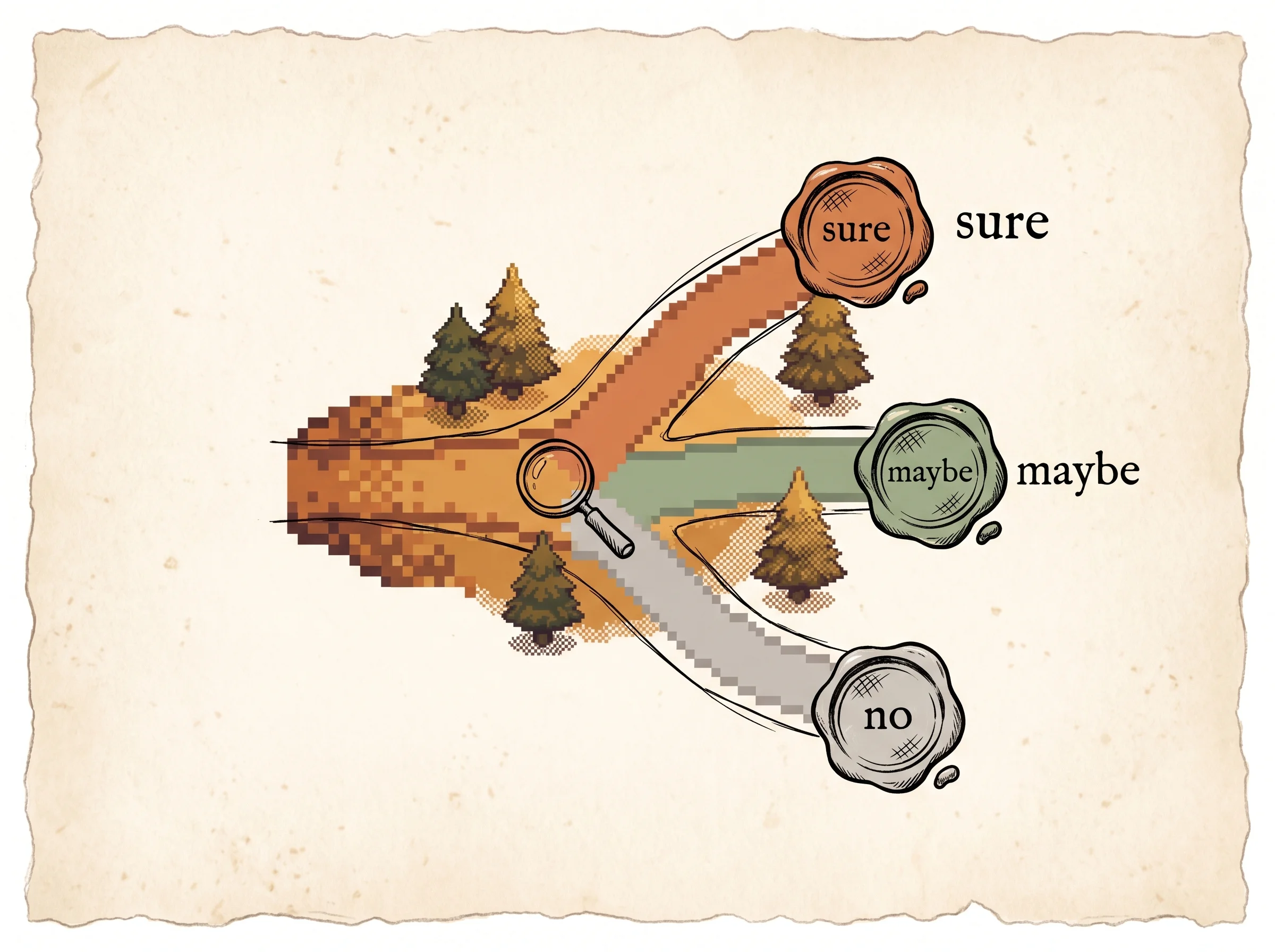
The trick that makes this work without any extra training is that the same model does both the generating and the evaluating. The evaluator is just the model prompted to reason about a state and answer sure, maybe, or impossible, which maps to a value the search can sort on.
def tot_bfs(x, generate, evaluate, steps, beam):
frontier = [State(x)] # start with just the input
for t in range(steps):
candidates = []
for s in frontier:
candidates += generate(s, k) # propose next thoughts
scored = [(evaluate(s), s) for s in candidates]
frontier = top_b(scored, beam) # keep the best b, prune the rest
return best(frontier)That top_b line is the whole game. With a beam of 1 you keep only the single best-looking state at each depth, so one bad score from the evaluator throws away the winning branch and never gets it back. With a beam of 5 you keep five, so the right branch survives even when the evaluator misranks it.
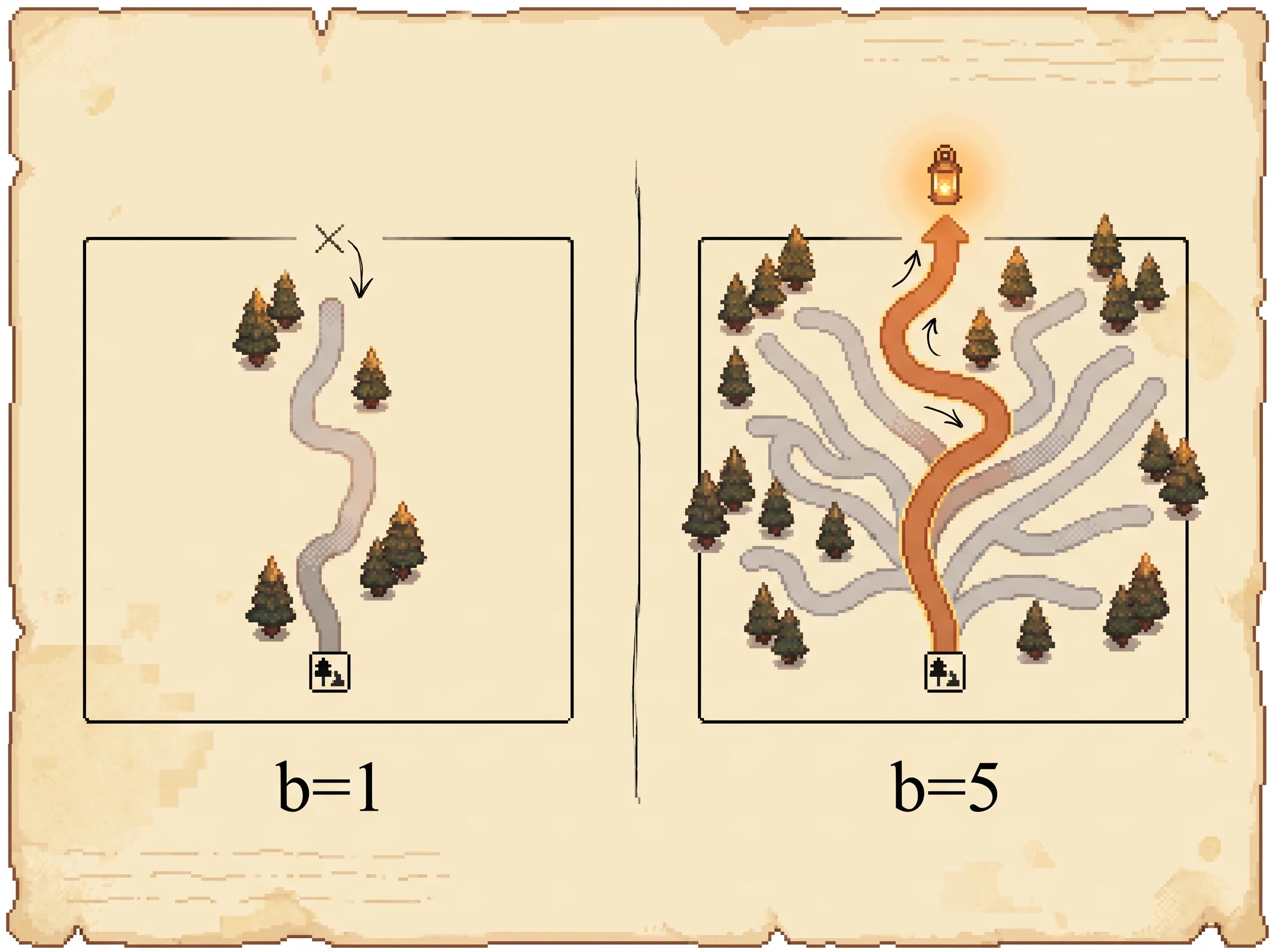
The numbers show exactly this. Beam of 1 solved 45 percent of Game of 24 puzzles, beam of 5 solved 74 percent, against 4 percent for chain-of-thought. The simulation above is honest about why. Load the narrow-beam preset, watch it drop the path, then widen the beam and watch the same search recover.
The limitation is cost. Every node needs a generate call and an evaluate call, and you keep several nodes per level, so you pay many model calls per problem instead of one. That buys the accuracy, and you decide whether the trade is worth it.
For an industry pro
The problem this solves is the class of tasks where your model gets the first step wrong and there's no recovery. Anything with lookahead or search, like multi-step planning, constraint puzzles, or structured generation under hard requirements, fails under plain prompting because the model can't revise a bad early commitment. Tree of Thoughts adds the revise step by turning inference into a tree search with self-scoring and backtracking.
Deployment cost is the thing to size carefully. This is not a fine-tune and needs no training, which is the upside, you wrap your existing model. The downside is call volume. You make a generate call to propose branches and an evaluate call to score them, at every node, and you keep several nodes per level. For Game of 24 with a beam of 5 over 3 steps that's dozens of model calls per single puzzle. Budget the API spend and the latency against the accuracy you need.
The expected improvement over your current prompting is large when the task actually needs search. Chain-of-thought solved 4 percent of Game of 24, Tree of Thoughts solved 74. But the gain is task-shaped, not free. If your task is one the model already handles in one pass, the tree buys you nothing and costs you many calls, so don't reach for it there.
The failure mode to plan around is the evaluator. The search is only as good as the model's own grading of partial states. On the crosswords task the evaluator sometimes called a solvable word state impossible and pruned the only good branch, which capped accuracy no matter how much search you threw at it. A better evaluator, or sampling the evaluation several times and aggregating, helps, but a confidently wrong evaluator silently throws away the answer. Load the evaluator-lies preset in the simulation to see a pruned-but-reachable branch flagged in red, which is exactly this failure happening in front of you.
For a PhD candidate
The contribution is recasting LM inference as a general tree search over self-generated, self-evaluated intermediate states, and showing it beats chain-of-thought by a wide margin on problems that need planning. Chain of Thought introduced intermediate reasoning steps but sampled them in a single left-to-right pass with no branching and no backtracking. Self-consistency sampled several full chains and took a majority vote, which adds breadth across complete solutions but still has no local exploration within a chain and only works when the answer space is small enough to vote over. Tree of Thoughts adds the two things both lack, branching at each step and a search that prunes and backtracks.
The methodological choices reward scrutiny. Decomposition is deliberately task-specific, a thought is one equation for Game of 24, a writing plan for Creative Writing, a word for Crosswords, chosen so a thought is small enough for the model to evaluate yet big enough to be coherent. Generation has two modes, sampling i.i.d. thoughts when the space is rich and diverse, and a propose prompt that lists candidates in one shot when the space is constrained and i.i.d. samples would collide. Evaluation also has two modes, an independent value per state, or a vote that compares states against each other, the latter for tasks like passage coherence where an absolute score is hard but a relative ranking is easy. The search is plain BFS with a beam, or DFS with a value threshold for pruning and backtracking, with A* and MCTS explicitly left as future work.

Threats to validity worth probing. The three tasks are chosen to be hard for left-to-right decoding and are not a broad benchmark, so the headline gains describe a class of problems, not all problems. The evaluator is the load-bearing component and its errors are the real ceiling, the crosswords ablations show that with the oracle best state ToT solves 7 of 20 games versus 4 of 20 with its own heuristic, so a chunk of the remaining failures are evaluation failures, not search failures. The cost analysis is light on a careful compute-matched comparison against simply sampling more chains. The obvious follow-ups are better learned evaluators, stronger search like MCTS, and whether the gains survive on tasks the field actually benchmarks.
For a peer researcher
The delta against Chain of Thought and CoT with self-consistency is that thoughts stop being a linear chain and become a tree the model searches with explicit pruning and backtracking, where the branching factor and the search both come from prompting a frozen model rather than from any training. The self-evaluation is the novel piece, search heuristics here are neither programmed nor learned but produced by the LM reasoning about its own partial states, which is what lets one framework span arithmetic, open-ended writing, and constraint satisfaction.
The choices read as deliberate tradeoffs. Propose-style generation versus i.i.d. sampling is a bet on whether the thought space is constrained or rich, and they switch per task rather than claiming one is right. Value-per-state versus vote-across-states trades an absolute scoring signal, which is cheap when it exists, for a relative one that works when absolute scoring is unreliable, which is the coherence case. BFS-with-beam versus DFS-with-threshold is the classic memory-versus-depth trade, and they pick by how deep the solution sits, BFS for the shallow 3-step Game of 24, DFS for the variable-depth crosswords.
What would change my mind on the central claim. If a compute-matched baseline, the same number of model calls spent on more self-consistency chains, closed most of the gap, the search framing would weaken into "spend more calls" rather than "search is the right structure." It doesn't close it, the error analysis shows about 60 percent of chain-of-thought samples already fail after the first step, which is exactly the early-commitment failure a tree fixes and more chains can't. The honest soft spot is the evaluator, and the crosswords pruning failures, solvable states confidently called impossible, are where the next work has to go.
How it works
The problem and why prior approaches failed. A language model generates text token by token, left to right, sampling each next token from a distribution conditioned on everything before it. That is a single greedy walk through an astronomically large space of possible continuations, with no mechanism to explore alternatives or to undo a choice. For tasks where the first decision is pivotal, this is fragile. Chain of Thought helped by prompting the model to write intermediate reasoning steps, but those steps are still one linear chain with no branching. Self-consistency sampled several full chains and voted, adding breadth but no local exploration inside a chain and no way to revise a step once written.
The key idea. Treat problem solving as search over a tree, where each node is a partial solution called a thought and the model itself both proposes the children of a node and scores how promising each node is. A standard search algorithm then explores the tree, keeps the promising nodes, prunes the rest, and backtracks out of dead ends. No training, just prompting a frozen model in two roles.
Methodology. Instantiating Tree of Thoughts means answering four questions for the task at hand. Decompose the problem into thought steps small enough to evaluate but coherent enough to mean something. Generate k candidate next thoughts from a state, either by sampling i.i.d. from a chain-of-thought prompt or by a single propose prompt that lists candidates. Evaluate each state, either with an independent value the model assigns by reasoning about the state, or by a vote that ranks states against each other. Then run a search.
ToT-BFS(x, generate G, evaluate V, steps T, beam b):
S = { x } # frontier starts at the input
for t in 1..T:
candidates = union over s in S of G(s, k) # propose next thoughts
S = argmax over size-b subsets of candidates of sum of V(s) # keep best b
return G(best of S)The breadth-first version keeps the best b states at each depth. The depth-first version dives into the most promising child, prunes any child whose value falls below a threshold, and backtracks to the parent when a branch dies. The simulation runs both, switch between BFS and DFS and watch the tree grow level by level or dive and backtrack.
Results with effect sizes. On Game of 24, chain-of-thought prompting with GPT-4 solved 4 percent of games and self-consistency over 100 samples reached 9 percent. Tree of Thoughts with a beam of 1 already hit 45 percent, and a beam of 5 hit 74 percent. The error analysis is telling, about 60 percent of chain-of-thought samples had already failed after generating just the first step, which is the early-commitment failure the tree is built to fix. On Creative Writing, GPT-4 scored passages from Tree of Thoughts at 7.56 coherence against 6.93 for chain-of-thought, and human raters preferred the tree's passages in 41 of 100 pairs against 21 for chain-of-thought. On Mini Crosswords, word-level success rose from under 16 percent for chain-of-thought to 60 percent for Tree of Thoughts, solving 4 of 20 games.
Limitations and open questions. Every node costs a generate call and an evaluate call, so the method spends many model calls per problem where plain prompting spends one, and deliberate search may not be worth it on tasks a model already handles in one pass. The evaluator is the ceiling, the crosswords ablations show an oracle best-state heuristic solving 7 of 20 games against the model's own 4 of 20, so confidently wrong evaluations that prune solvable branches are a real failure mode. The paper uses simple BFS and DFS and leaves stronger search like A* and MCTS, and fine-tuning the model for this style of deliberate decision making, as future work.
My assessment
The authors got the framing right, and it has held up. Recasting inference as search over self-evaluated thoughts is the durable idea, and it generalizes cleanly, the same four-question recipe handles arithmetic, open-ended writing, and a constraint puzzle. The cheapest part, having one frozen model play both generator and evaluator with no training, is what made the idea spread, because anyone could try it on top of a model they already had.
Where the work is honest about its own soft spot is the evaluator, and that honesty is the most useful part of the paper. The crosswords ablation, where an oracle state-picker beats the model's own heuristic, names the ceiling plainly, the search is only as good as the model's grading of partial states, and a confidently wrong grade silently discards the answer. That is the failure the simulation above puts in front of you, a branch from which 24 is truly reachable, flagged in red because the evaluator called it impossible and pruned it.
The thing the paper undersells is cost. The headline 74 percent against 4 percent is real, but it buys that with dozens of model calls per puzzle, and the paper does not press hard on a compute-matched comparison, what the same budget spent on more self-consistency chains would do. The error analysis answers it indirectly, since 60 percent of chains fail at the first step, more chains can't rescue the early-commitment problem the way a tree can, but a tighter accounting would have made the case airtight. The open door the authors named, stronger search and learned evaluators, is exactly where the next wave of work went.