Proximal Policy Optimization Algorithms
A way to train a policy that gets trust-region reliability from plain gradient steps, by clipping the objective so the reward goes flat once the policy strays too far from where it started.
Read at your level
Start where you're comfortable and climb as far as you like.
- For a 5-year-old
- For a high schooler
- For a college student
- For an industry pro
- For a PhD candidate
- For a peer researcher
Executive summary
Training a policy with gradient ascent has a sharp edge. Take one step that's too big and the new policy can be so much worse than the old one that the whole run falls apart. The earlier fix, trust region policy optimization, kept each step small by solving a constrained problem with second-order math, which works but is a pain to build and won't share a network between the policy and the value function. PPO gets the same reliability with plain first-order gradient steps. It changes the objective instead of constraining the step. Once the new policy's probability for an action drifts more than a small fraction away from the old policy's, the objective goes flat, so the gradient stops pushing and the step can't run away. That one change lets you reuse a batch of experience for many cheap updates instead of one careful one. PPO beat the other online policy gradient methods across MuJoCo control tasks and won 30 of 49 Atari games on training-period reward, while staying simple enough to write in a few lines on top of vanilla policy gradient. The cost is that the clip bounds each sample's ratio, not the true policy change, so it's a heuristic, not a guarantee.
Try it
Load the No clip, many epochs preset and press play. Watch the per-round KL line (sage) spike past the band and the trust-region light flip to broken as the policy chews one batch too hard. Now switch the update to Clip mid-run and watch the light come back on and the return settle. Then load Clipped objective, hover a corridor state, and drag the clip width epsilon down to 0.05. The ratio dots get pinned tight against the band, the climb slows, and nothing ever bolts.
The paper's main method, epsilon 0.2 with 10 reuse epochs per round. Press play and watch the return climb to optimal while the trust-region light stays lit, because the clip flattens the gradient the instant a ratio leaves the band.
| action | prob | ratio | A | clip? |
|---|---|---|---|---|
| left | 50% | 1.00 | -0.01 | no |
| right | 50% | 1.00 | 0.01 | no |
Play, switch the objective, or drag epsilon to start the log.
Each tick is one inner gradient step on the frozen snapshot batch; after K epochs the round ends and the snapshot refreshes (Algorithm 1). The advantage is solved exactly on this 5-state corridor, so the surrogate is exact up to the softmax policy class; real PPO estimates it from samples, which the noise slider stands in for. The trust-region light tracks KL(snapshot, policy), the quantity the clip bounds. Discount gamma is fixed at 0.97. The playback-speed dial controls animation pace only and does not affect the gradient math. This corridor is forgiving enough that even a divergent no-clip run still finds the goal, where on a real task like HalfCheetah the same destructive updates sink the return outright.
For a 5-year-old
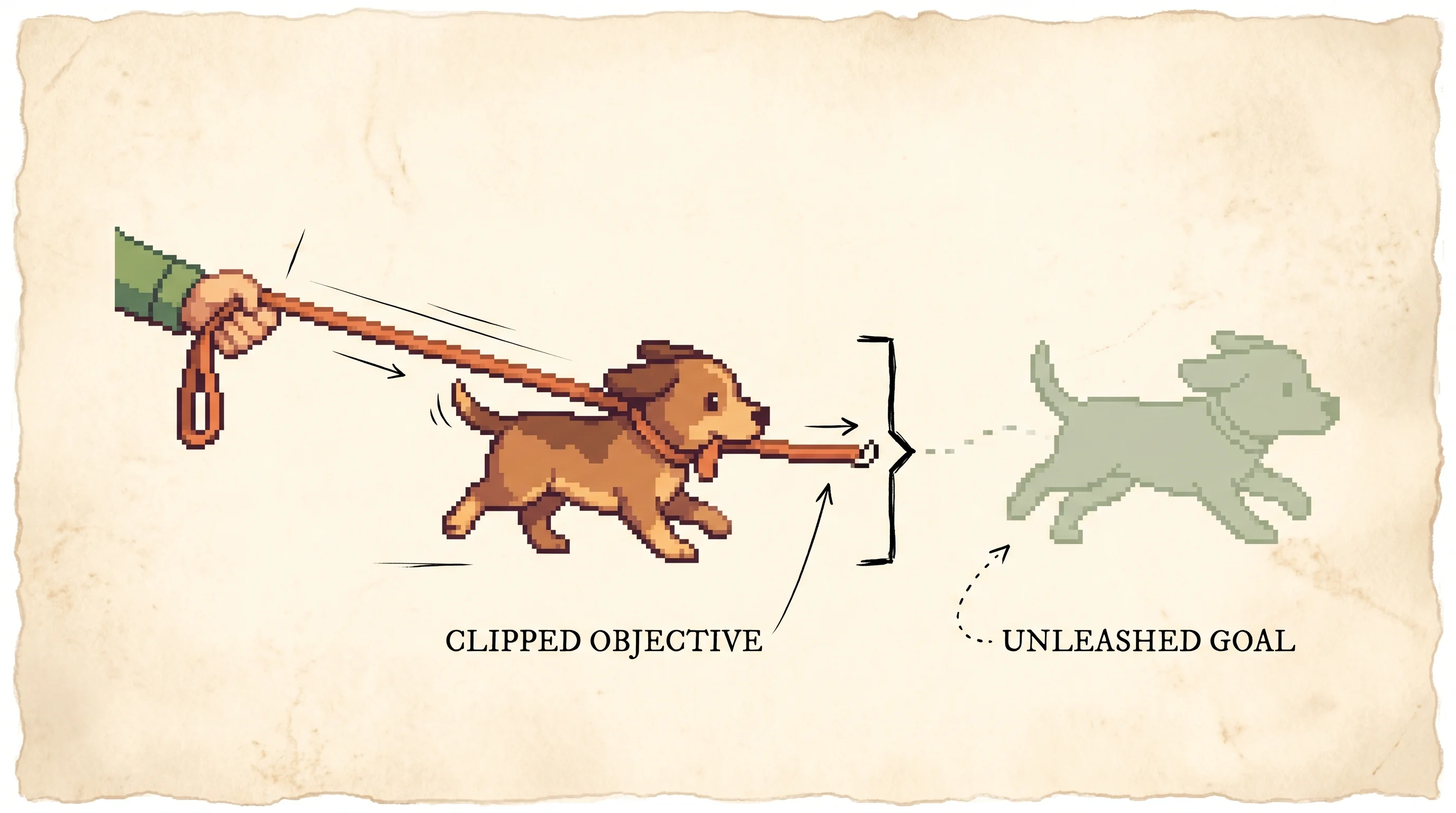
Imagine you have a puppy on a leash, and you're teaching it to walk to the park. The puppy is excited, so it pulls hard toward every smell. If you let it run as fast as it wants, it yanks the leash, trips, and you both end up in a worse spot than you started.
So you use a short leash. The puppy can still walk forward and learn the way to the park. But the leash only lets it go a little bit past where it is right now. When it pulls too hard, the leash goes tight and pulling more does nothing. One little walk at a time, the puppy gets closer to the park without ever tumbling.
That short leash is the whole idea. The puppy is a robot learning to do a task. Each time it tries, it wants to change a lot all at once, because the reward is pulling it. The leash stops it from changing too much in one go. Lots of small safe steps beat one big step that knocks everything over.
The robot doesn't really feel a leash tug. The leash is a rule in the math that says once the robot changes more than a little, it stops getting points for changing more. No points means no reason to keep pulling.
For a high schooler
You've used an app that learns what you like, maybe a video feed that gets better at picking videos the more you watch. Under the hood, something is tuning a set of dials to make good choices more likely and bad choices less likely. Reinforcement learning does this for an agent acting in a world. The set of dials is called a policy, and it gives a probability to each action the agent could take.
Here's the trap. To improve the policy, you nudge the dials in the direction that earned reward last time. If you nudge too far, the new policy can behave completely differently from the one that gathered your data, and your data no longer describes what the new policy does. You've stepped off a cliff using a map of where you used to stand.
PPO fixes this with one number called the ratio. The ratio compares how likely the new policy is to take an action against how likely the old policy was. At the start of an update the ratio is exactly 1, because the two policies are the same. As you tune the dials, the ratio for a good action creeps above 1. PPO says you only get rewarded for pushing it up to a small limit, say 1.2, and not a step further. Past 1.2 the reward goes flat, so the gradient that drives the dials reads zero and the update stops on its own.
Here's a worked example. Say an action was good, with advantage +1, and you've pushed its ratio to 1.5 with a clip limit of 1.2. The plain objective would still pay you 1.5 times 1, growing without limit. PPO instead pays the clipped amount, 1.2 times 1, and freezes it there. The dial for that action gets no more push. The leash is tight.
Lots of small clipped steps reach a good policy without any single step blowing it up.
For a college student
You should care about this because PPO is the default policy gradient algorithm in practice. It trains game agents, robots, and the reward-tuning stage of large language models, and it earned that spot by being both stable and simple.
Start with the plain policy gradient. You have a stochastic policy π_θ(a|s) with parameters θ, and you want to maximize expected return. The estimator everyone uses is
ĝ = Ê_t[ ∇_θ log π_θ(a_t | s_t) · Â_t ]where Â_t is an estimate of the advantage, how much better action a_t was than the policy's average at state s_t. You can write a loss whose gradient is this estimator and hand it to an optimizer. The temptation is to run that optimizer for many steps on one batch of collected experience, because experience is expensive to gather. But the loss was built around the policy that gathered the data, and after a few steps the policy has moved, so the loss is lying to you. Push hard enough and the policy collapses.
TRPO solved this by constraining the KL divergence between the old and new policy, keeping the update inside a trust region, but it needs conjugate gradients and a quadratic approximation, and it can't cleanly share parameters between the policy and value networks.
PPO replaces the constraint with a clip. Define the probability ratio
r_t(θ) = π_θ(a_t | s_t) / π_{θ_old}(a_t | s_t)so r is 1 when the policy hasn't moved. The naive surrogate is r_t(θ) · Â_t. PPO's clipped surrogate is
L^CLIP(θ) = Ê_t[ min( r_t(θ) · Â_t , clip(r_t(θ), 1−ε, 1+ε) · Â_t ) ]with ε around 0.2. Read it carefully. The second term clamps the ratio into the band [1−ε, 1+ε] before multiplying by the advantage. The outer min takes the smaller of the clamped and unclamped terms. That min is what makes the clip a one-sided pessimistic bound.
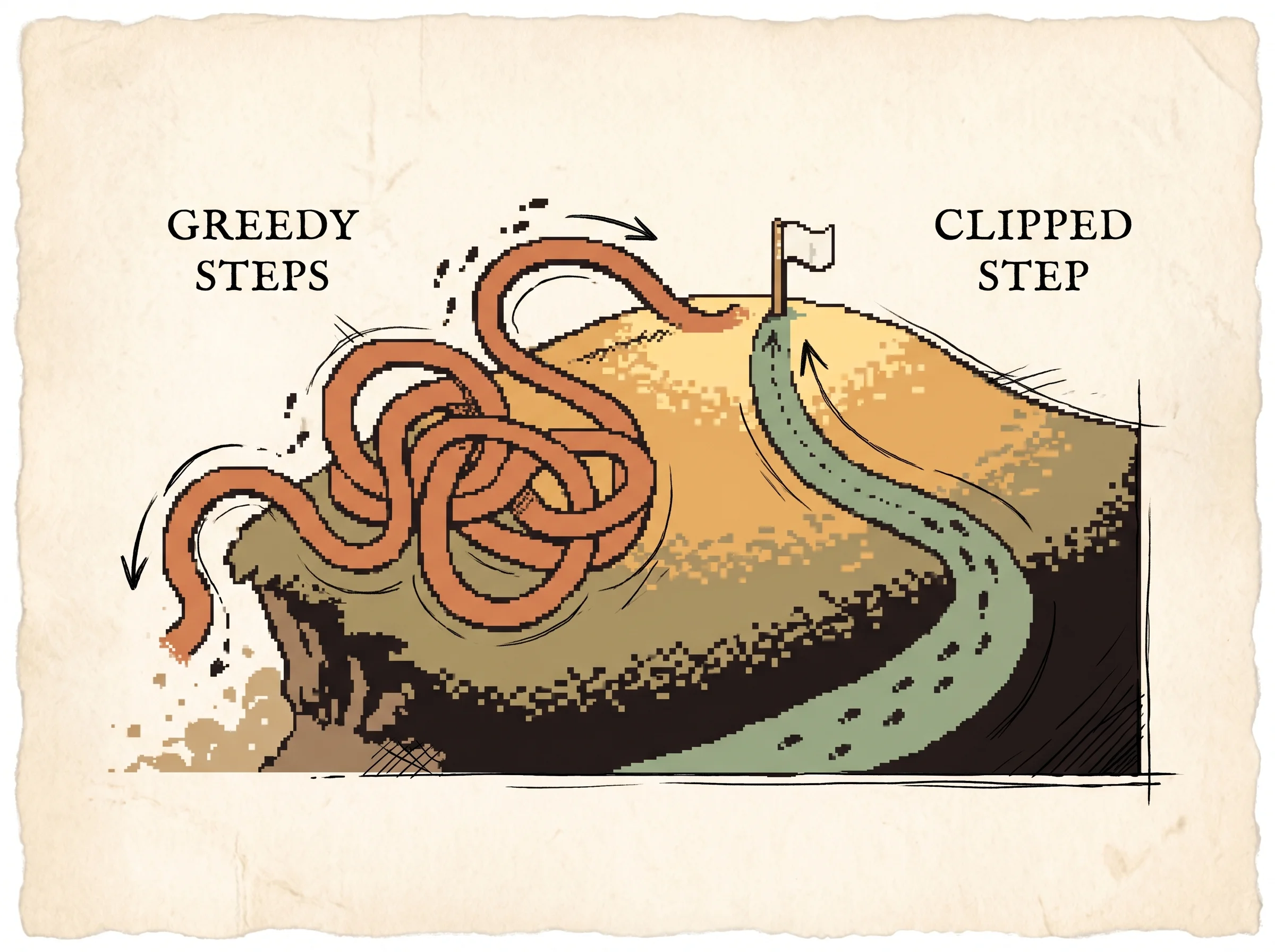
Walk the two cases. When the advantage is positive, you want to raise the action's probability, so r climbs above 1. The objective rewards that climb until r hits 1+ε, then the clipped term caps it and the line goes flat, so there's no gradient pulling r higher. When the advantage is negative, you want to lower the probability, so r falls below 1, and the objective stops rewarding it past 1−ε. The min adds the crucial asymmetry. If the ratio moves the wrong way past the band, the unclipped term is smaller, so the min picks it and the penalty still applies. You only lose the incentive when the move helps, never when it hurts.
The interactive above computes exactly this. Each corridor state shows the ratio for each action as a dot on a track, and the sage band is [1−ε, 1+ε]. When a dot leaves the band, its update reads zero and it can't push further.
The result is that you can safely run many epochs of minibatch SGD on one batch. Collect NT timesteps, optimize L^CLIP for K epochs, then refresh the snapshot policy and collect again.
The limitation is that the clip bounds each sample's ratio, not the actual KL divergence of the policy. It's a cheap proxy that works well in practice but doesn't promise the policy stays in a true trust region.
For an industry pro
The problem PPO solves for you is sample-efficient, stable on-policy training without the engineering weight of TRPO. If you've tried to ship TRPO, you know the conjugate-gradient inner loop and the Fisher-vector products are fiddly, and the moment you want one network with a shared trunk for the policy and value heads, the clean trust-region story breaks. PPO is a few lines on top of a vanilla policy gradient. You compute the ratio, clip it, take the min, and run Adam for several epochs on the batch.
Deployment cost is low. No second-order machinery, no per-update line search. The hyperparameters that matter are the clip width ε (0.2 is the paper's pick and a fine default), the number of reuse epochs K (around 10 for control, 3 for Atari), the horizon T, and the GAE settings (γ = 0.99, λ = 0.95). If you share a network, add a value-function loss term with coefficient c1 and an entropy bonus c2 for exploration.
The expected improvement over the alternatives is real. On the MuJoCo continuous-control suite, clipping at ε = 0.2 scored 0.82 on the paper's normalized scale, beating every KL-penalty variant (0.62 to 0.74) and crushing the no-clip baseline (-0.39, worse than a random policy on one task). On Atari, PPO won 30 of 49 games on average reward over all of training, the metric that favors fast, stable learning. ACER edged it on final-episode performance, 28 wins to 19, so if you only care about the very best converged policy and can afford the extra complexity of off-policy replay, ACER is competitive.
The failure mode to watch is the one PPO is built to prevent and can still hit. The clip bounds the per-sample ratio, not the policy's true change, so a batch where many samples each move a little can still add up to a large policy shift. Reuse a batch for too many epochs and you push past where the clip protects you. The interactive shows this directly. The no-clip preset blows the KL past the band; even clip with a huge step and 40 epochs stays bounded, but the gap is your safety margin, not infinite. Tune K down if you see the KL drifting up between rounds.
For a PhD candidate
The contribution is a first-order surrogate that recovers most of TRPO's monotonic-improvement behavior without the constrained optimization. TRPO maximizes Ê[r_t Â_t] subject to Ê[KL] ≤ δ, justified by a lower bound on policy performance that uses a per-state max-KL penalty. The exact penalty is too conservative to use directly, and a fixed penalty coefficient β is brittle across problems and across the course of a single run. PPO sidesteps the penalty-versus-constraint dilemma by clipping the ratio, which removes the gradient signal that would push the policy outside [1−ε, 1+ε] in the helpful direction while keeping it in the harmful direction via the outer min.
The methodological choices reward scrutiny. The min of the clipped and unclipped terms is the load-bearing piece. Clipping alone, without the min, would also flatten the objective when the policy moves the wrong way past the band, which is exactly when you want the gradient to pull it back. The min ensures L^CLIP is a lower bound on the unclipped L^CPI, so optimizing it can't be fooled into a worse policy by an overshoot. The paper also tests an adaptive-KL-penalty variant (eq 8) that adjusts β toward a target d_targ each round, and finds it consistently worse than clipping, which is the honest result given that clipping is the simpler method.
The advantage estimator is truncated GAE (eq 11), which interpolates between low-variance one-step TD and high-variance Monte Carlo via λ, computed over length-T segments so it works with recurrent policies and bootstraps at the truncation. For shared-parameter architectures the objective adds a squared value-function error and an entropy bonus (eq 9).
Threats to validity. The clip is a per-sample heuristic with no guarantee on the realized KL, so the trust-region analogy is loose. The continuous-control gains live on seven MuJoCo tasks with three seeds each, a thin statistical base by later standards, and the deep-RL-reproducibility literature has since shown how seed-sensitive these comparisons are. The Atari result splits depending on whether you weight early learning or final performance, so "PPO is best" depends on which you care about. The follow-up questions the field then chased are what the clip actually bounds, whether better surrogates exist, and how much of PPO's empirical strength comes from implementation details rather than the objective itself.
For a peer researcher
The delta against TRPO is dropping the constrained second-order solve for a clipped first-order surrogate that you optimize with ordinary SGD for several epochs per batch. You keep the multi-epoch data reuse and the stability, you lose the conjugate-gradient machinery and the hard KL constraint, and you gain compatibility with shared policy-value networks and with noise like dropout. The delta against vanilla policy gradient is that L^PG has no protection against multi-epoch reuse on one batch, so it either takes one update per sample or blows up, and L^CLIP makes the reuse safe.
The choices read as deliberate tradeoffs. The clip trades a true KL bound for a cheap per-sample proxy that needs no extra computation, and the min buys back the lower-bound property so the surrogate can't reward a harmful overshoot. The fixed ε trades adaptivity for one fewer thing to tune, which the adaptive-KL ablation suggests is a fair trade since the adaptive scheme didn't help. Truncated GAE trades a bias from bootstrapping at T for variance reduction and recurrence compatibility.
What would change my mind on the central claim. If the no-clip L^CPI matched PPO's stability under the same multi-epoch reuse, the clip would be doing nothing, but the -0.39 normalized score says otherwise. If the realized KL routinely blew through any reasonable bound despite the clip, the trust-region framing would be hollow, and the honest answer is that it can drift, which is why practitioners cap reuse epochs and watch the KL. The open question the paper leaves is what objective best bounds the true policy change at first order, and the years since have produced PPO-penalty hybrids, KL early-stopping, and a long argument over how much of PPO is the objective versus the code.
How it works
The problem and why prior approaches failed. A policy gradient nudges the policy along the gradient of expected return. The estimator ĝ = Ê[∇ log π_θ(a|s) · Â] is built from data the current policy gathered. Run one gradient step and you're fine. Run many steps on the same batch, which you want to do because data is expensive, and the policy drifts away from the one that gathered the data, so the surrogate loss stops describing reality and the update can grow destructively large. TRPO prevents this by constraining the KL divergence per update, but the constrained solve needs conjugate gradients and a quadratic KL approximation, and it doesn't play well with parameter sharing or stochastic network layers.
The key idea. Replace the constraint with a clipped objective. Track the probability ratio r_t(θ) = π_θ(a_t|s_t) / π_{θ_old}(a_t|s_t), which is 1 before any update. Reward the policy for moving the ratio in the advantageous direction, but only until the ratio reaches the edge of a band [1−ε, 1+ε]. Past the edge, flatten the objective so the gradient is zero and the step can't keep running. Take the minimum of the clipped and unclipped terms so a move in the harmful direction is never let off the hook.
L^CLIP(θ) = Ê_t[ min( r_t Â_t , clip(r_t, 1−ε, 1+ε) Â_t ) ]Methodology. PPO alternates between sampling and optimizing, shown in Algorithm 1.
for iteration = 1, 2, ... do
for actor = 1, 2, ..., N do
run policy π_{θ_old} in the environment for T timesteps
compute advantage estimates Â_1, ..., Â_T (truncated GAE)
end for
optimize L^CLIP wrt θ for K epochs, minibatch size M ≤ NT
θ_old ← θ
end forEach round freezes a snapshot θ_old, collects a batch under it, computes advantages once, then runs K epochs of minibatch SGD on L^CLIP against that frozen batch before refreshing the snapshot. In the interactive, one tick is one inner epoch and the round counter shows the outer loop. The advantage uses truncated generalized advantage estimation, which blends one-step and multi-step returns through λ.
Â_t = δ_t + (γλ)δ_{t+1} + ... + (γλ)^{T−t+1} δ_{T−1}, δ_t = r_t + γV(s_{t+1}) − V(s_t)When the policy and value function share a network, the full objective adds a value-error term and an entropy bonus.
L^{CLIP+VF+S}(θ) = Ê_t[ L^CLIP(θ) − c1 (V_θ(s_t) − V^targ_t)^2 + c2 S[π_θ](s_t) ]What happens if you skip the clip is the heart of the paper. The plain L^CPI = r_t Â_t keeps paying you to push the ratio further every epoch, so over many epochs on one batch the policy overshoots and the KL blows up.
Load the no-clip preset and watch the sage KL line spike past the band; the clip preset under the same step size keeps it flat. That contrast is the whole argument for the clip.
Results with effect sizes. On the MuJoCo continuous-control benchmark, averaged over seven tasks and 21 runs, clipping at ε = 0.2 scored 0.82 on the paper's normalized scale where 0 is a random policy and 1 is the best run. Tighter and wider clips did slightly worse (0.76 at ε = 0.1, 0.70 at ε = 0.3), every adaptive-KL setting landed between 0.68 and 0.74, every fixed-KL setting between 0.62 and 0.72, and the no-clip-no-penalty baseline scored -0.39, worse than random because it tanked HalfCheetah. On Atari across 49 games, PPO won 30 on average reward over all of training and ACER won 28 on final-100-episode reward, so PPO favors fast stable learning and ACER favors the converged peak.
Limitations and open questions. The clip bounds each sample's ratio, not the policy's realized KL, so a batch of many small per-sample moves can still add to a large policy change, which is why reuse epochs need a cap. The adaptive-KL variant the paper includes as a baseline performed worse than the clip. The continuous-control results rest on three seeds per task, and the Atari winner depends on the scoring metric.
My assessment
The authors got the central call right, and the field ratified it hard. PPO became the default on-policy algorithm because it hit the sweet spot the introduction promised, trust-region reliability with vanilla-gradient simplicity, and a decade of game agents, robots, and language-model fine-tuning runs on it. The clipped objective is the rare idea that's both theoretically motivated, as a lower bound on the unclipped surrogate, and trivial to implement, which is exactly the combination that gets adopted.
Where the paper is honestly thin is the gap between the clip and a real trust region. The clip controls a per-sample ratio and the paper never claims more, but the trust-region framing invites the reader to assume the policy's KL is bounded, and it isn't. Practitioners learned this the hard way and bolted on KL early-stopping and reuse-epoch caps, fixes the paper's own no-clip failure case predicts. The other soft spot is one the authors couldn't have seen. The thin three-seed evaluation looked normal in 2017, and the reproducibility reckoning that followed showed how much these comparisons wobble with seeds and implementation details, to the point where later work argued a large share of PPO's edge comes from code-level choices rather than the objective. None of that unseats the core. Clip the ratio, take the min, reuse the batch, and you get a stable policy gradient you can actually ship.