Playing Atari with Deep Reinforcement Learning
A single network learns to play seven Atari games straight from the screen pixels by trying moves, scoring its own guesses about future points, and shuffling a memory of past moments so the learning never spirals out of control.

Read at your level
Start where you're comfortable and climb as far as you like.
- For a 5-year-old
- For a high schooler
- For a college student
- For an industry pro
- For a PhD candidate
- For a peer researcher
Executive summary
Before this paper, an agent that learned to act from raw vision needed hand-built features, someone to tell it what parts of the screen mattered. The authors fed a neural network nothing but the raw pixels and the score, and asked it to learn seven Atari games on its own. The network predicts the value of each move, the total future score it expects if it plays that move and keeps going. It trains by nudging that prediction toward what actually happened plus its own guess about the rest. That recipe is unstable on its own, because the moments an agent lives through come in long correlated streaks and the network chases its own shifting opinion. The fix is experience replay. Store every moment in a memory, then train on a random shuffled batch instead of the last thing that happened. With that one trick the same learning rate that would blow up stays calm. The network beat every prior method on six of the seven games and beat a human expert on three. The cost is that it still needs millions of frames and the memory is a blunt instrument that forgets old moments and treats every memory as equally worth studying.
Try it
Press play on the Stable preset and watch the paddle learn to slide under the ball while the value line at the bottom stays flat near zero. Now flip the Experience replay button off while it runs. The value line climbs, then spirals, then blows up, the runaway the paper warns about, at the exact same learning rate. Flip replay back on and load Stable again to settle it. Then try Buffer too small to see the milder version, where the memory is too thin to shuffle anything useful.
Algorithm 1 as published. Random minibatches from the replay memory keep the value estimate bounded while the paddle learns to catch.
| action | Q-value | chosen |
|---|---|---|
| left | 0.000 | greedy ★ |
| stay | 0.000 | |
| right | 0.000 |
Flip replay, drag a slider, or pin the ball to start the log.
This runs the inner loop of Algorithm 1 exactly: behave epsilon-greedily, store each transition, sample a minibatch, and regress toward the target r + γ·max Q(s'). Two honest simplifications stand in for the paper's scale. The game is a 5 × 5 catch grid, not an Atari screen, and the Q-network is a linear approximator over a few overlapping tile features, not a convolutional net. The overlap is on purpose — it recreates the deadly triad the paper warns about. With replay off the value estimate runs away; with replay on the same learning rate stays bounded. The discount factor gamma is fixed at 0.95; the run is deterministic for any given preset.
For a 5-year-old
Imagine a kid learning a video game nobody explained to her. Nobody says press this button. She just watches the screen and presses things, and the only feedback she gets is the score going up or down. So she learns by guessing. Every time she does something good, the score goes up, and she remembers that doing that thing was a good idea.
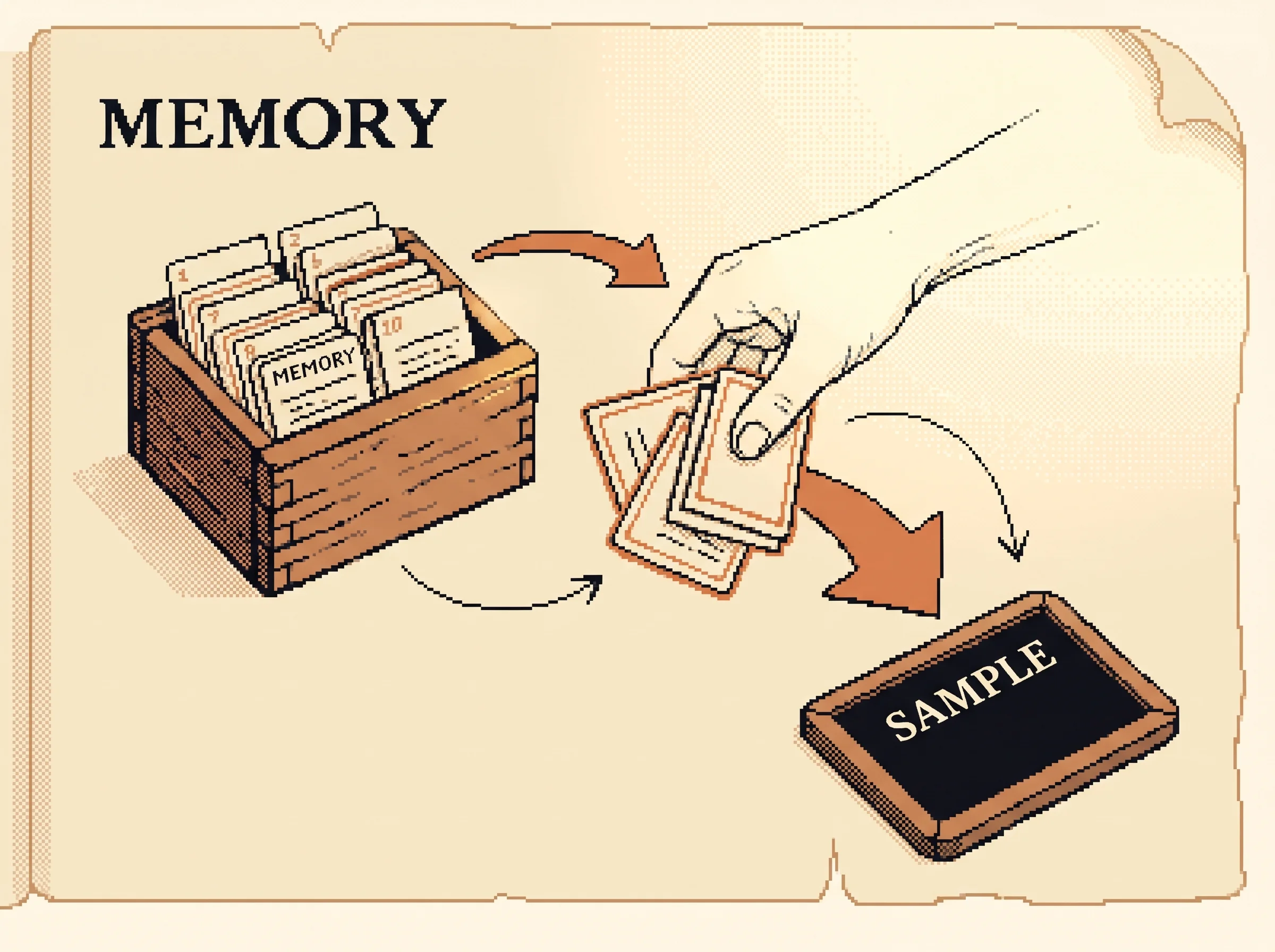
Here's the clever part. Instead of only thinking about the last second of the game, she keeps a shoebox full of little snapshots, moments from games she already played. When she wants to get better, she reaches into the box and pulls out a random handful and studies those. A bit from this game, a bit from that one, all mixed up.
Why mix them up? Pretend she only ever studied the last few seconds. The last few seconds are almost all the same, the ball over here, the ball still over here, the ball a tiny bit lower. If you only ever study the same thing, you start believing silly things and you can't tell when you're wrong. Pulling random old snapshots from the shoebox keeps her honest, because no two are quite the same.
The kid in this story isn't really a kid. It's a computer doing math with numbers, and the score is the only teacher it ever gets. But the shoebox of mixed-up memories is real, and it's the thing that made the whole idea work.
For a high schooler
You've used a phone that learns. The keyboard that guesses your next word, the app that learns which videos you'll watch. Those learn from labeled examples, somebody already marked the right answer. A game-playing agent has no answer key. It only gets a score, and often the score doesn't move for a long time, so it can't tell which of its hundred recent moves earned the point.
So the agent learns to predict, not to copy. For every move it could make, it predicts a number called the Q-value. That's its best guess of the total score it will rack up if it makes that move now and plays well after. Pick the move with the biggest Q-value and you're playing your best.
The problem is the agent has to learn these numbers without an answer key. Here's the trick it uses. After it makes a move it sees the real reward it got, plus it can look one step ahead and guess the value of the next situation. So a better estimate of "value of this move" is "reward I just got, plus my guess of the value from here." The agent nudges its prediction toward that better estimate. It's bootstrapping, using its own guesses to improve its own guesses.
Now the danger. The situations an agent lives through come in streaks. Frame after frame the ball is in nearly the same spot, so the agent trains on the same thing over and over. Train on one streak too hard and the agent overcommits, then a new streak yanks it the other way. The numbers swing instead of settling. The fix is experience replay. Save every moment, the situation, the move, the reward, the next situation, into a big memory. To learn, pull out a random mix of saved moments and train on those. The mix is varied, so no single streak dominates, and the numbers settle.
Built from raw pixels and that one memory trick, the agent beat every earlier program on six of seven Atari games and beat a skilled human on three of them.
For a college student
You should care about this because it's the paper that kicked off deep reinforcement learning. The recipe here, a deep network predicting action values, trained off a replay buffer, is the skeleton inside a decade of work that followed.
The setup is a Markov decision process you only see through pixels. At each step the agent gets an image, picks an action a from a small set, and receives a reward r (the change in game score). It wants to maximize the discounted return.
R_t = r_t + γ r_{t+1} + γ² r_{t+2} + ...The discount γ (between 0 and 1) makes points sooner worth more than points later. Define the optimal action-value function Q*(s, a) as the best return you can get after seeing situation s and taking action a. It satisfies the Bellman equation, which just says the value of a move is the reward now plus the discounted value of playing optimally from the next situation.
Q*(s, a) = E[ r + γ max_a' Q*(s', a') ]
You can't store Q* for every screen, there are far too many, so you approximate it with a neural network Q(s, a; θ). Train it by turning the Bellman equation into a regression target. The target for one stored transition is y = r + γ max_a' Q(s', a'; θ), and you minimize the squared error against the network's current prediction.
L(θ) = E[ (y − Q(s, a; θ))² ]Take a gradient step on that and you have Q-learning with a neural network. The trouble is the deadly triad, the combination of function approximation, bootstrapping (the target uses the network's own output), and off-policy learning. Each is fine alone. Together they can diverge, and the paper cites exactly this risk.
The stabilizer is experience replay. Store transitions (s, a, r, s') in a buffer, and each step sample a random minibatch to train on instead of the latest transition. Two things improve. Each experience gets reused in many updates, so you're data-efficient. And the random sample breaks the correlation between consecutive frames, which smooths the training distribution and stops the network from chasing its own tail. The behavior is ε-greedy, mostly take the best-looking action, but with probability ε pick at random so you keep exploring.
The simulation above runs this exact loop on a tiny catch game. Press play with replay on and the value estimate stays flat while the paddle learns. Turn replay off at the same learning rate and watch it diverge. That isn't a quirk of the toy, it's the deadly triad biting, the same instability the buffer tames at full scale.
For an industry pro
The problem this solves is learning control from raw perception without a feature engineer in the loop. Before it, getting an agent to act from vision meant someone hand-coding which pixels mattered. This learns the features and the policy end to end from pixels and a scalar reward.
What it costs to run. The agent needs a lot of interaction, 10 million frames per game here, and a replay memory holding the last 1 million transitions. Preprocessing matters more than it looks. Frames are downsampled to grayscale 84 by 84, and the network sees the last 4 frames stacked so it can perceive motion. The agent acts every 4th frame and repeats the action between, which quadruples throughput for free. Rewards are clipped to +1, 0, or −1 so one learning rate works across games with wildly different score scales, at the price of being blind to how big a reward is. Training used RMSProp, minibatches of 32, and ε annealed from 1 down to 0.1 over the first million frames.
The improvement over the prior bar is large and broad, not a fragile sliver. Across all seven games it beat the best linear-feature methods, and on Breakout, Enduro, and Pong it beat a skilled human. The same network and the same hyperparameters did all seven with no per-game tuning, which is the real headline for anyone shipping. The failure envelope is honest. On Q*bert, Seaquest, and Space Invaders, games that need a plan stretching over long time scales, it stayed well below human. The reward clipping caps what it can express, the buffer forgets and samples everything uniformly, and there's no convergence guarantee, just empirical stability. If your task has dense feedback and short horizons, you get the win cleanly. If it needs long-horizon credit assignment, expect the gap.
For a PhD candidate
The contribution is the first demonstration that a deep network trained by a Q-learning variant can learn control policies directly from high-dimensional raw pixels, across a suite of tasks, with one fixed architecture. The mechanism that makes it tractable is experience replay layered onto online Q-learning, which the authors borrow from Lin and repurpose as the stabilizer for nonlinear function approximation.
The methodological choices reward scrutiny. The deadly triad, function approximation plus bootstrapping plus off-policy updates, was the known reason Q-learning with nonlinear approximators was considered unsafe, and prior work like NFQ leaned on batch methods (RPROP over the whole dataset) to sidestep it. This paper instead keeps cheap online stochastic updates and breaks the correlation statistically by sampling a random minibatch from a large buffer. That's the key trade. It decorrelates the update distribution and smooths the behavior distribution the network trains against, which is what prevents the feedback loop where a shifting greedy policy biases its own training data. The architecture choice is also deliberate. Rather than feed the state-action pair and get one Q-value, they feed only the state and emit a Q-value per action in a single forward pass, so action selection costs one inference regardless of action count.
The threats to validity are visible. Stability is empirical, the authors report no divergence in their runs but offer no guarantee, and the value-estimate curves in Figure 2 are their evidence that the method tracks a sensible objective. Reward clipping confounds any claim about value magnitude, since the agent cannot distinguish a small reward from a large one. The replay buffer is uniform and finite, so it overwrites old experience and weights every transition equally, which the authors flag as crude next to prioritized sweeping. And the long-horizon failures (Q*bert, Seaquest, Space Invaders) point straight at the limits of one-step bootstrapping with a short effective horizon. The obvious follow-ups, most of which the field then chased, are a separate slowly-updated target network to further stabilize the bootstrap, prioritized replay, and better handling of partial observability than a 4-frame stack.
For a peer researcher
The delta against NFQ and the Lin-style replay work is that this fuses online stochastic Q-learning with a large replay buffer and a deep convolutional approximator, and shows it holds up across seven games from pixels alone with no per-game tuning. NFQ paid a batch cost per iteration proportional to dataset size; this keeps constant-cost online updates and recovers stability statistically by decorrelating the minibatch. Earlier visual RL first learned a low-dimensional representation with an autoencoder and then did RL on top; here the convolutional features and the policy are learned jointly, end to end, against the reward.
The choices read as deliberate tradeoffs. Reward clipping buys a single learning rate across games at the cost of value-magnitude fidelity. Frame skipping with action repeat buys roughly 4x throughput at the cost of temporal resolution. Uniform replay buys simplicity at the cost of the prioritization that would let the agent learn most from its most surprising transitions. The per-action output head buys cheap action selection. Each is a defensible engineering call rather than a claimed universal truth.
What would change my read. The central stability claim rests on the absence of observed divergence rather than a proof, so a regime where this exact recipe reliably diverges, without changing the learning rate into obviously bad territory, would weaken it. It didn't show up in their suite. The honest soft spots, uniform finite replay, a bootstrap target that moves with the same network being trained, and weak long-horizon credit assignment, are precisely the seams the next few years pried open, with target networks, prioritized replay, and longer-horizon returns.
How it works
The problem and why prior approaches failed. Reinforcement learning from raw vision was stuck. Deep learning needs lots of labeled data; RL has only a sparse, noisy, delayed scalar reward, and the gap between an action and the point it earns can be thousands of frames. Deep learning assumes independent samples; an agent's experience is a stream of highly correlated states. And the data distribution shifts as the policy changes, which breaks methods that assume a fixed distribution. Combine a nonlinear approximator with bootstrapping and off-policy learning and Q-learning was known to diverge, so the field had retreated to linear approximators with convergence guarantees.
The key idea. Approximate Q* with a convolutional network on raw pixels, and stabilize the training with experience replay. Store every transition in a memory, and learn from a random minibatch drawn from it rather than from the latest moment. The random draw breaks the correlation between consecutive frames and averages the behavior distribution over many past policies, which is what keeps the unstable combination from running away.
Methodology. The full loop is Algorithm 1.
Initialize replay memory D to capacity N
Initialize action-value network Q with random weights
for episode = 1, M:
observe first screen, preprocess to state s_1
for t = 1, T:
with probability ε pick a random action a_t
otherwise a_t = argmax_a Q(s_t, a; θ)
execute a_t, observe reward r_t and next screen
store transition (s_t, a_t, r_t, s_{t+1}) in D
sample a random minibatch of transitions from D
set y_j = r_j if s_{j+1} is terminal
= r_j + γ max_a' Q(s_{j+1}, a'; θ) otherwise
take a gradient step on (y_j − Q(s_j, a_j; θ))²The state s is the last 4 preprocessed frames stacked, so motion is visible. Each frame is converted to grayscale and downsampled to 84 by 84. The network is three convolutional layers into a fully connected layer into one output per action, so a single forward pass scores every move.
Results with effect sizes. Across all seven games DQN beat the best prior learning methods (Sarsa and Contingency on hand-engineered features). On Breakout it scored 168 versus a human's 31, on Enduro 470 versus 368, on Pong 20 versus a roughly −3 baseline. On Beam Rider it landed close to human. The harder long-horizon games stayed below human, Q*bert at 1952 versus 18900, Seaquest at 1705 versus 28010, Space Invaders at 581 versus 3690. The same architecture and hyperparameters trained all seven with no per-game adjustment.
Limitations and open questions. The replay memory is uniform and finite, so it forgets old transitions and treats every memory as equally worth learning from; the authors point at prioritized sweeping as the better path. Reward clipping flattens reward magnitude. Stability is empirical, not proven. And one-step bootstrapping with a short effective horizon is weak exactly where the failing games demand a long plan.
My assessment
The authors got the central engineering call right, and the field has been blunt about it. Deep RL as a discipline grows out of this skeleton. The piece that carried the most weight was the cheapest one, experience replay, an idea borrowed and repurposed into a statistical fix for the deadly triad. It costs a buffer and a random index, and it converts a known-unstable combination into something you can actually train. That's the kind of janky, decisive move that wins.
Where the paper was appropriately modest is in what it claimed. It reported stability rather than proved it, and it named its own soft spots cleanly, the uniform finite buffer, the clipped rewards, the long-horizon failures. Those weren't hand-waved, and each one became a research program. The follow-up the same group published a year later added a separate slowly-updated target network, the missing brace on the bootstrap, and that's what pushed the method past human on the full Atari suite. Prioritized replay fixed the uniform-sampling crudeness. The long-horizon games are still hard. None of that dents the core lesson here. Give a network the raw screen, a score, and a shuffled memory of its own past, and it learns to play.