Trust Region Policy Optimization
Improve a policy by taking the biggest step that still keeps the new policy close to the old one, so your estimate of the improvement stays trustworthy and the real performance goes up almost every time.

Read at your level
Start where you're comfortable and climb as far as you like.
- For a 5-year-old
- For a high schooler
- For a college student
- For an industry pro
- For a PhD candidate
- For a peer researcher
Executive summary
Training a policy with reinforcement learning means nudging its behavior in a direction that should earn more reward. The trouble is the policy never knows the real reward landscape. It only has a local estimate, built from the trajectories it just collected, and that estimate goes stale the moment the policy changes, because a different policy visits different states. Take too big a step and the estimate that pointed uphill was lying, so the real performance drops. Take tiny steps to stay safe and training crawls. TRPO finds the sweet spot. It builds a surrogate, a local model of how much a candidate policy would improve, and it takes the largest step that keeps the new policy within a fixed distance of the old one, measured by KL divergence. That distance is the trust region. The paper proves that this kind of bounded step gives monotonic improvement, then turns the proof into a practical algorithm that learns simulated swimming, hopping, and walking gaits from scratch, and plays Atari from raw pixels, all with little hyperparameter tuning. The cost is that each update solves a constrained optimization with a conjugate-gradient and line-search inner loop, which is heavier than a plain gradient step.
Try it
Load the No trust region: overshoot preset and press play. Watch the surrogate curve (clay-orange, dashed) keep promising gains while the true return (sage) lurches and crashes below it. Now switch the update to trust region mid-run and watch the true curve settle and climb to the top. Then load KL penalty: crawl to see the opposite failure, where the steps get so timid the climb barely moves.
Each round takes the natural-gradient step scaled to a mean KL of delta, then backtracks until the surrogate truly improves. The new policy stays close enough that the surrogate stays honest, so the true return climbs almost every round. Press play and watch the two curves rise together toward optimal.
Run a few rounds to draw the climb.
Sage is the true return from the start, clay-orange dashed is what the surrogate predicts. The dashed ceiling is optimal. When they split, the policy moved past where the surrogate is trustworthy.
Click a cell to read its move probabilities and each move's true advantage. Solid clay-orange is the policy's favored move.
Overshoots, backtracks, and control changes show up here.
The policy is a softmax over moves in each cell of a 5 by 5 gridworld with a goal worth +1 and a trap worth −1. Every round the model solves the policy exactly for its value, advantage, and discounted visitation, builds the surrogate and its natural-gradient step, then scales the step to a mean KL of delta and backtracks until the surrogate truly improves. The advantage estimate carries a fixed bias whose pattern is set by the preset; raising estimate error makes the surrogate less trustworthy even within the KL budget. Runs are deterministic: the same preset always produces the same trajectory. This runs one small MDP solved exactly, where the paper estimates these quantities from sampled trajectories.
For a 5-year-old
Imagine you're walking up a hill, but there's thick fog everywhere. You can only see the ground in a small circle right around your feet. Inside that circle the ground is clear, so you know which way is up and you can step there safely. Past the circle it's all fog. You can't see if it's a path or a cliff.
So here's the smart rule. Only step as far as the clear circle lets you. Step to the edge, look around at the new clear circle, then step again. You climb the whole hill this way, one safe step at a time, and you never fall off a cliff you couldn't see.
The silly way is to take a huge leap into the fog because you feel like up is that way. Maybe you're right. Maybe you land in a hole and end up lower than you started.
A robot learning to walk has the same problem. It can't see the whole "hill" of good and bad behaviors. It can only guess from what it just tried, and that guess is only good for behaviors close to what it's doing now. So the robot steps a little, checks, steps a little more. That careful stepping is the whole trick.
For a high schooler
Think about how a video game character learns to play better. It tries some moves, sees how many points it got, and figures out which moves seemed to help. Then it changes its strategy to do more of the good moves. A strategy like this, a rule for picking actions, is called a policy.
Here's the catch. After the character changes its strategy, it starts playing differently, which means it ends up in different situations than before. The notes it took on the old strategy ("jumping here was great") might not apply anymore, because now it rarely gets to that spot. So a guess about how much a new strategy helps is only reliable if the new strategy is close to the old one.
TRPO turns that into a hard rule. It builds a surrogate, a quick estimate of how much a new policy would improve, using the data it just collected. Then it asks for the policy that the surrogate likes best, but with a leash. The new policy is not allowed to differ from the old one by more than a set amount. That set amount is the trust region.
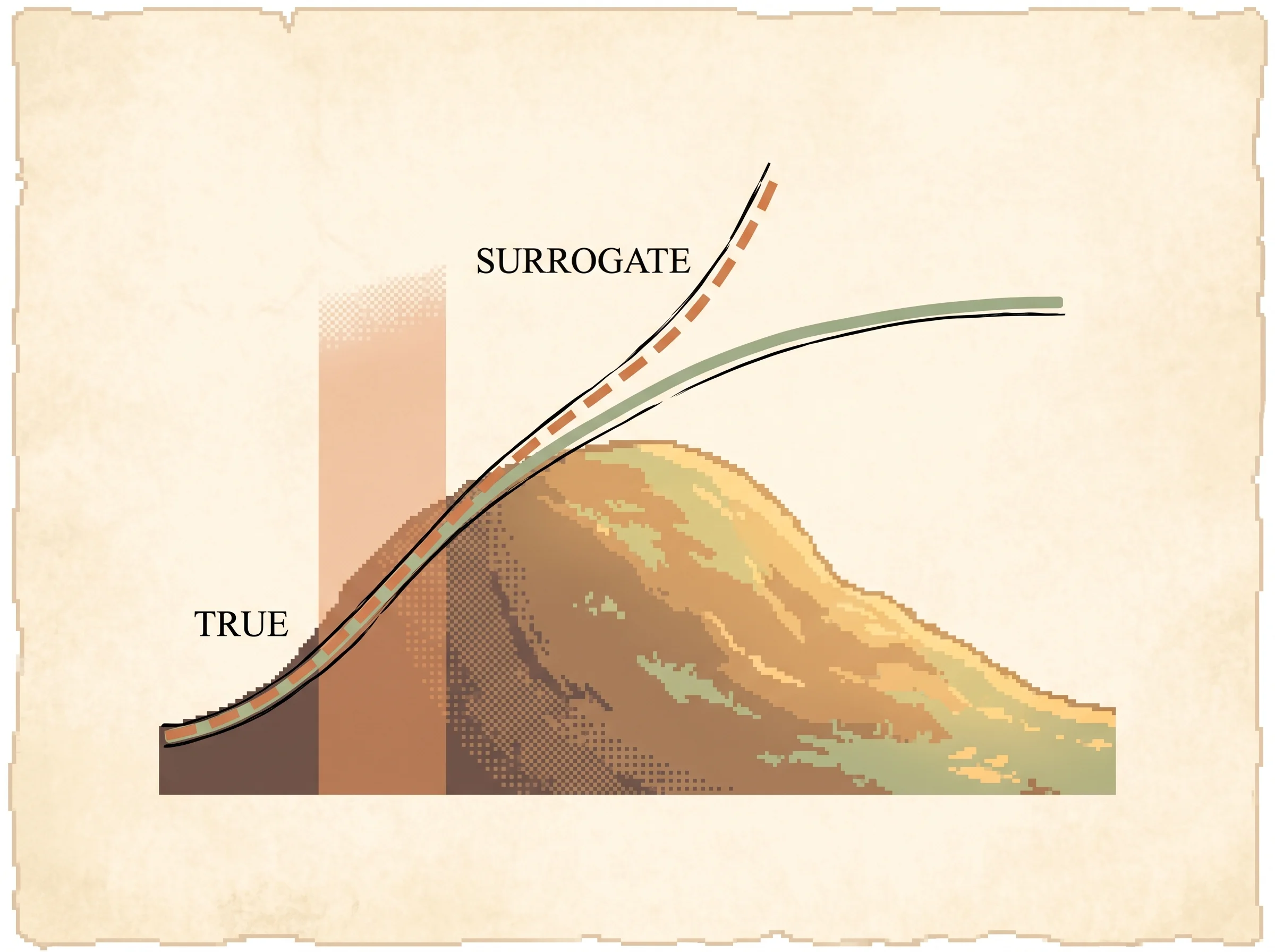
Picture two lines on a graph as you change the policy more and more. One line is the surrogate's prediction, the other is the real result. Near the start they sit right on top of each other, so the surrogate is honest. Far out, they split, and the surrogate keeps promising gains the real result never delivers. The trust region is a fence that keeps you in the part where the two lines still agree.
Stay inside the fence and every step is a real step up. That's the payoff.
For a college student
You should care about this because TRPO is the bridge between the clean theory of policy iteration and the messy reality of training neural-network policies, and its descendant PPO became the default workhorse for everything from robot control to tuning large language models.
Start with the objective. A policy pi has an expected discounted return eta(pi). There's an exact identity, due to Kakade and Langford, that writes the return of a new policy pi-tilde in terms of the old one plus the advantages it collects:
eta(pi-tilde) = eta(pi) + E_{tau ~ pi-tilde} [ sum_t gamma^t A_pi(s_t, a_t) ]The advantage A_pi(s, a) is how much better action a is than the policy's average at state s. The identity is exact but useless on its own, because the expectation is over trajectories from the new policy, which you don't have yet. So you make one approximation. Replace the new policy's state visitation with the old one's, rho_pi instead of rho_pi-tilde:
L_pi(pi-tilde) = eta(pi) + sum_s rho_pi(s) sum_a pi-tilde(a|s) A_pi(s, a)This L is the surrogate. It matches eta to first order around the current policy, but it ignores the fact that changing the policy changes which states you visit. That's exactly why it goes stale far from pi.
The contribution is bounding how stale. The paper proves a lower bound on the true return in terms of the surrogate minus a penalty that grows with how far the policy moved:
eta(pi-tilde) >= L_pi(pi-tilde) - C * D_KL_max(pi, pi-tilde)where C = 4 * epsilon * gamma / (1 - gamma)^2 and epsilon is the largest advantage. If you maximize the right-hand side, the true return can only go up. That's the monotonic improvement guarantee.

The practical algorithm makes one swap. Using that big penalty C forces microscopic steps, so instead of penalizing the KL divergence, constrain it. Maximize the surrogate subject to the policy staying inside a fixed KL budget delta:
maximize_theta L_theta_old(theta)
subject to mean_KL(theta_old, theta) <= deltaThe trust region is the dashed circle in the figure, and the update steps right to its edge. Solving this needs the natural-gradient direction (the surrogate gradient preconditioned by the Fisher information, which is the second derivative of the KL), found with conjugate gradient, followed by a line search that backtracks until the surrogate truly improves and the KL stays under budget.
The simulation above runs this exactly on a small gridworld it can solve in closed form. Load trust region and step through it. Each round computes the advantage, takes the natural step scaled to KL = delta, and the true return climbs almost monotonically. Crank the delta slider up and the climb starts to wobble, because a wide trust region lets the policy move past where the surrogate is honest.
For an industry pro
The problem TRPO solves is fragile training. Plain policy gradient with a fixed learning rate is a coin flip on continuous-control and high-variance tasks. One bad batch produces a step that wrecks the policy, and because the next batch is collected by that wrecked policy, it often can't recover. You spend your time babysitting learning rates per task.
TRPO replaces the learning rate with a trust region. Instead of "move this far in parameter space," it says "move until the policy's behavior changes by this much," measured in KL divergence, which is scale-invariant and far more stable across tasks. The headline operational win is that one setting, delta = 0.01 in the paper, works across swimming, hopping, walking, and Atari with little retuning. That is the property you actually want in production: fewer knobs, predictable behavior.
The deployment cost is real. Each update solves a constrained problem with a conjugate-gradient inner loop to get the natural-gradient direction, plus a backtracking line search, plus Fisher-vector products. That's more compute and more code than a vanilla step, and it needs a batch big enough to estimate the gradient and the KL Hessian. For most teams today the honest recommendation is PPO, the direct descendant, which keeps the "limit how much the policy changes" idea but enforces it with a clipped objective and ordinary first-order optimization, so it drops the heavy inner loop while keeping most of the stability.
The failure mode to plan around is the approximations stacking up. The monotonic-improvement proof assumes exact advantages and the max KL over all states; the practical algorithm uses sampled advantages and the average KL. When your advantage estimates are noisy, the surrogate is less trustworthy, so even a within-budget step can hurt. Load the Trust region too wide preset in the simulation to see this directly: with a loose budget and estimation error, the true return wobbles and can settle short of optimal. Tighten the budget and it steadies.
For a PhD candidate
The contribution is extending Kakade and Langford's conservative policy iteration bound from mixture policies to general stochastic policies, and turning the resulting penalty bound into a tractable trust-region constraint that scales to neural-network policies.
The lineage matters. CPI gave a monotonic-improvement guarantee, but only for policies of the form pi_new = (1 - alpha) pi_old + alpha pi', a restrictive mixture rarely used in practice. TRPO's Theorem 1 replaces the mixture coefficient alpha with the total-variation distance between pi and pi-tilde, then upper-bounds TV by KL via Pinsker, giving the bound eta(pi-tilde) >= L(pi-tilde) - C * D_KL_max. This now applies to any policy pair, which is what makes it usable.
The methodological choices reward scrutiny. The penalty coefficient C = 4 epsilon gamma / (1 - gamma)^2 is provably correct but practically catastrophic, since it forces tiny steps, so they trade the guarantee for a fixed KL constraint delta and accept that monotonicity now holds empirically rather than provably. The constraint uses the average KL D-bar_KL rather than the theoretically required max KL, because the max over all states is intractable to estimate. The natural-gradient connection is explicit: linearize L and take a quadratic approximation to the KL constraint and you recover Kakade's natural policy gradient with a principled step size, where TRPO's line search is the piece that fixes the step natural gradient leaves as a free hyperparameter. They build the Fisher information by analytically differentiating the KL twice rather than using the covariance of gradients, which removes a sampling error and is cheaper at scale.
Two sampling schemes estimate the objective and constraint. Single-path samples whole trajectories, the standard policy-gradient setup, usable on a physical system. Vine samples a set of states then rolls out every action from each (with common random numbers to cut variance), which gives far better advantage estimates but needs a resettable simulator. The variance reduction from vine is substantial, and it's the better choice when you can reset.
Threats to validity worth probing. The proof's chain of approximations (sampled advantages, average KL, fixed delta) is acknowledged but not bounded in the practical setting, so "monotonic in practice" rests on the experiments rather than the theorem. The locomotion tasks are low-dimensional next to modern benchmarks. And the cost of the second-order inner loop is the soft spot the whole next wave of work attacked.
For a peer researcher
The delta against natural policy gradient is the constraint replacing the free step size, and the delta against CPI is the move from mixture policies to arbitrary stochastic policies via a TV-then-KL bound. Strip those two and you have the prior art; add them and you get an algorithm that is both theoretically grounded and trainable on neural nets.
The choices read as deliberate tradeoffs. Constraint over penalty trades the provable monotonicity of the C-penalty form for steps large enough to make progress, buying back robustness with the line search that rejects any step where the measured surrogate improvement or KL violates the budget. Average KL over max KL trades a slightly weaker guarantee for an estimable constraint. The analytic Fisher over the empirical covariance trades a little generality for lower variance and a cheaper Fisher-vector product. Vine over single-path trades simulator resets for a large cut in advantage-estimate variance.
What would change my mind on the central claim. If a first-order method matched TRPO's cross-task stability without the second-order machinery, the trust-region apparatus would look like overkill. That basically happened: PPO kept the bounded-update idea and dropped the conjugate-gradient and KL-constraint inner loop, matching or beating TRPO with ordinary SGD, which is the strongest evidence that the durable contribution is "constrain how much the policy changes per update," not the specific way TRPO enforces it. The honest open question the paper leaves is how far the approximation chain can be pushed before the empirical monotonicity breaks, which is exactly the territory the deep-RL reproducibility literature later mapped.
How it works
The problem and why prior approaches failed. Policy optimization wants to push a policy toward higher expected return. The exact return of a candidate policy depends on the states that policy visits, which you can't know until you run it, so every practical method optimizes an estimate built from the current policy's data. Plain policy gradient takes a step in the estimated-improvement direction with a hand-tuned learning rate, and the right rate varies wildly by task, so training is fragile. Conservative policy iteration fixed the fragility with a monotonic-improvement guarantee, but only for mixture policies that interpolate between the old policy and a greedy one, which is too restrictive to use with neural networks.
The key idea. Build a surrogate L that estimates the improvement of a candidate policy using the current policy's state visitation, then take the largest step that keeps the candidate within a fixed KL divergence of the current policy. Close-by policies keep the surrogate honest, so optimizing it inside that trust region raises the true return. The single sentence the rest supports: maximize the local improvement model subject to a trust-region constraint on the policy change.
Methodology. The exact return identity expands eta(pi-tilde) as eta(pi) plus the new policy's discounted advantages. Swapping the new policy's visitation for the old policy's gives the surrogate L_pi, which matches eta to first order around pi.
L_pi(pi-tilde) = eta(pi) + sum_s rho_pi(s) sum_a pi-tilde(a|s) A_pi(s, a)Theorem 1 bounds the true return below by the surrogate minus a KL penalty, so maximizing the bound guarantees improvement. The penalty's coefficient is too large to be useful, so the practical algorithm constrains the KL instead.
maximize_theta E_{s,a ~ pi_old} [ (pi_theta(a|s) / pi_old(a|s)) * A_old(s,a) ]
subject to E_{s ~ pi_old} [ D_KL(pi_old(.|s) || pi_theta(.|s)) ] <= deltaThe objective uses an importance ratio because the actions were sampled from the old policy. To solve it, linearize the objective and take a quadratic approximation of the KL constraint, which makes the step the natural-gradient direction A^-1 g (with A the Fisher information, the KL's Hessian) scaled to land on the constraint boundary. Conjugate gradient computes A^-1 g without forming A, and a backtracking line search shrinks the step until the actual surrogate improves and the measured KL stays under delta.
g = estimate_surrogate_gradient(trajectories)
step_dir = conjugate_gradient(fisher_vector_product, g) # A^-1 g
beta = sqrt(2 * delta / (step_dir @ fisher_vector_product(step_dir)))
for frac in [1, 0.5, 0.25, ...]: # line search
candidate = theta_old + frac * beta * step_dir
if surrogate(candidate) > surrogate(theta_old) and kl(theta_old, candidate) <= delta:
return candidateTwo sampling schemes feed this. Single-path collects whole trajectories and is usable on real hardware. Vine samples states then rolls out every action from each, using common random numbers, which sharply cuts advantage-estimate variance but needs a resettable simulator.
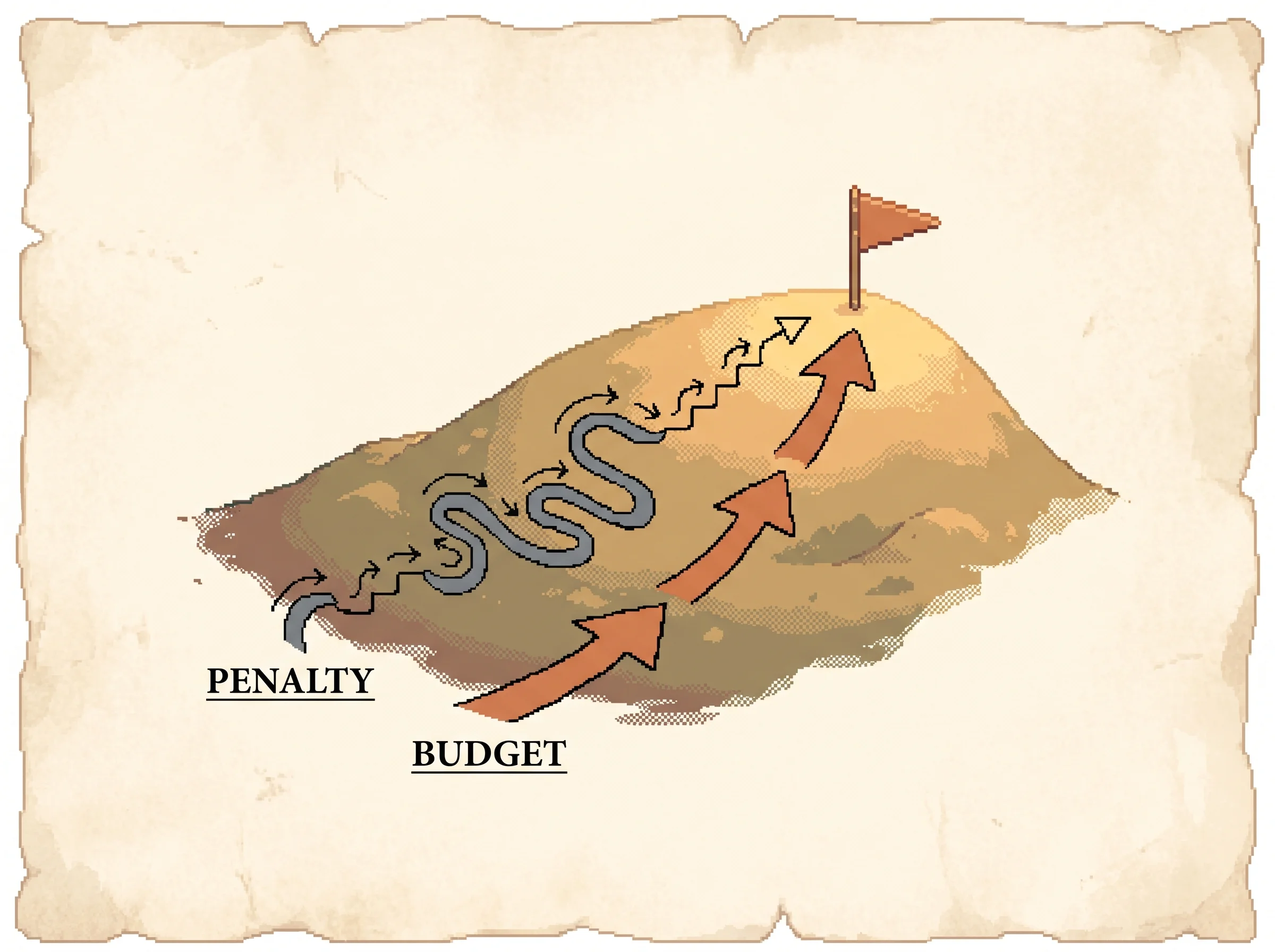
The constraint-versus-penalty choice is the practical heart of the method. The theory's penalty coefficient is so large that it forces a crawl, the slate path above. The fixed KL budget lets the policy take bounded but confident steps, the clay-orange path that reaches the top. Load the KL penalty: crawl preset in the simulation to feel the difference, then switch to trust region and watch the steps grow.
Results with effect sizes. On the MuJoCo locomotion tasks, both TRPO variants learned swimming, hopping, and walking gaits from scratch with general-purpose neural-net policies and minimal reward shaping, while natural gradient learned the two easy tasks but failed to produce hopping or walking gaits, and the derivative-free CEM and CMA scaled poorly with the parameter count. A single delta = 0.01 worked across all tasks. On seven Atari games from raw pixels, the same method reached reasonable scores on most games despite not being designed for that domain, with 500 iterations taking about 30 hours on a 16-core machine. The generality is the headline: one method, locomotion and vision-based games, without per-domain engineering.
Limitations and open questions. The monotonic-improvement proof assumes exact advantages and the max KL over all states, while the practical algorithm uses sampled advantages and the average KL, so monotonicity in practice is empirical, not proven. The second-order inner loop costs compute and code. And the locomotion tasks are small by today's standards.
My assessment
The authors got the central idea exactly right, and it has aged better than the specific algorithm. "Bound how much the policy changes per update, measured by behavior rather than parameters" is the durable lesson, and it survives in nearly every modern policy-optimization method. The KL-as-distance choice is the quiet stroke of genius, because it makes the step size scale-invariant and gives you one hyperparameter that transfers across wildly different tasks, which is the property that made the experiments so clean.
Where the paper oversold is the theory-to-practice link. The monotonic-improvement theorem is elegant, but the practical algorithm tosses out the provable penalty for a chosen constraint, swaps max KL for average KL, and uses noisy sampled advantages, so by the time you reach the code the guarantee is gone and what's left is a well-motivated heuristic that happens to work. The paper is honest that these are approximations, but the framing leans on the theorem more than the deployed method earns. The verdict came fast and blunt: PPO kept the bounded-update insight, threw away the conjugate-gradient and KL-constraint machinery, and matched TRPO with plain first-order optimization. That's the cleanest possible evidence that the heavy second-order apparatus was the part you could drop, and the idea of constraining policy change was the part you couldn't. TRPO's real legacy is not its inner loop but the way it reframed the step size as a trust region.